本文主要是介绍拒绝花里胡哨,MySQL统计总数就用count(*),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有一个问题是这样的统计数据总数用count(*)、count(主键ID)、count(字段)、count(1)那个效率高。
先说结论,不用那么花里胡哨遇到统计总数全部使用count(*).
但是有很多小伙伴就会问为什么呢?本期文章就解决大家的为什么。

一、不同存储引擎的做法
你需要知道的是在不同的存储引擎下,MySQL对于使用count(*)返回结果的流程是不一样的。
在Myisam中,每张表的总行数都会存储在磁盘上,因此执行count(*)时,是直接从磁盘拿到这个值返回,效率是非常高的。但你也要知道如果加了条件的统计总数返回也不会那么快的。
在Innodb引擎中,执行count(*),需要把数据一行一行的读出来,然后再统计总数返回。
问题:为什么Innodb不跟Myisam一样把表总数存起来呢?
这个问题就需要追溯的我们之前的MVCC文章,就是因为要实现多版本并发控制,才会导致Innodb不能直接存储表总数。
因为每个事务获取到的一致性视图都是不一样的,所以返回的数据总数也是不一致的。
如果你无法理解,再回到MVCC文章好好看看,意思就跟不同事务看到的数据不一致一回事。
实战案例
假设这三个用户是并行的,你会看到三个用户看到最终的数据总数都不一致。
每个用户会根据read view存储的数据来判断哪些数据是自己可以看见的,那些是看不见的。

read view
当执行SQL语句查询时会产生一致性视图,也就是read-view,它是由查询的那一时间所有未提交事务ID组成的数组,和已经创建的最大事务ID组成的。
在这个数组中最小的事务ID被称之为min_id,最大事务ID被称之为max_id,查询的数据结果要根据read-view做对比从而得到快照结果。
于是就产生了以下的对比规则,这个规则就是使用当前的记录的trx_id跟read-view进行对比,对比规则如下。
如果落在trx_id<min_id,表示此版本是已经提交的事务生成的,由于事务已经提交所以数据是可见的
如果落在trx_id>max_id,表示此版本是由将来启动的事务生成的,是肯定不可见的
若在min_id<=trx_id<=max_id时
- 如果row的trx_id在数组中,表示此版本是由还没提交的事务生成的,不可见,但是当前自己的事务是可见的
- 如果row的trx_id不在数组中,表明是提交的事务生成了该版本,可见
二、MySQL对count(*)做了什么优化
先来看两个索引结构,一个是主键索引、另一个是普通索引。
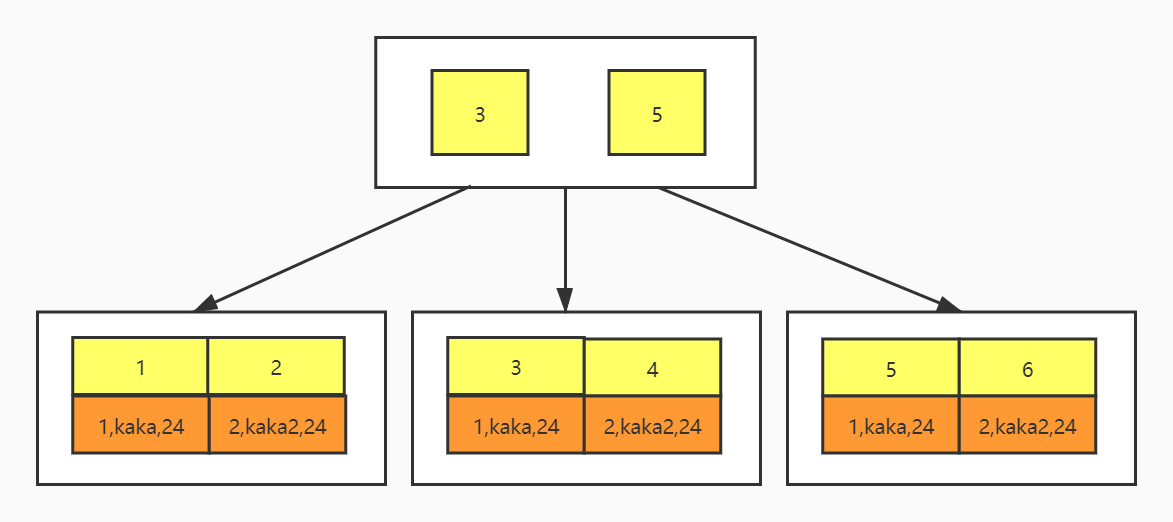
主键索引
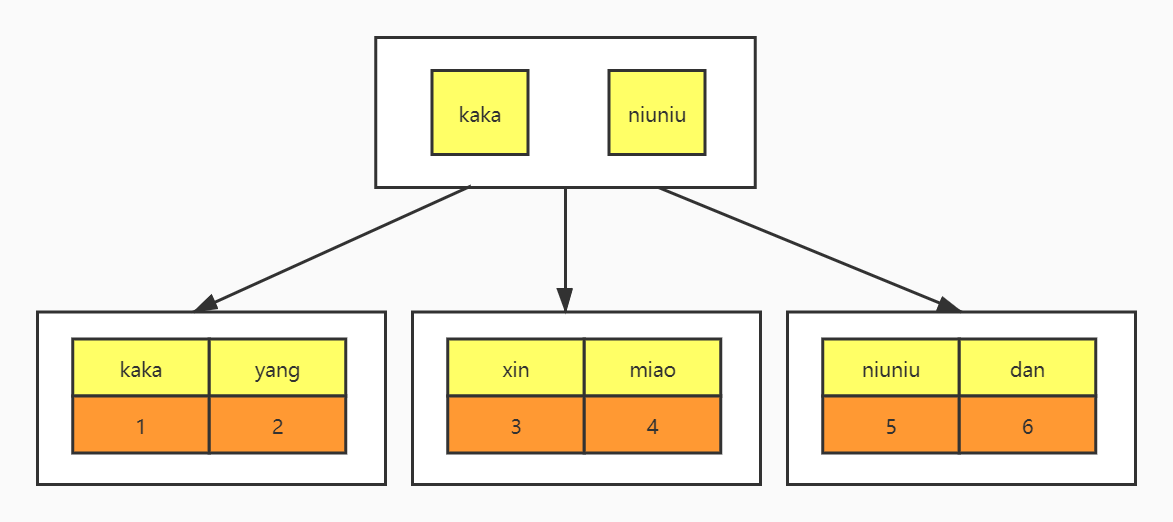
普通索引
现在你应该知道了,主键索引的叶子节点存储的是整行数据,而普通索引叶子节点存储的是主键值。
得出结论就是普通索引的比主键索引会小很多。
所以,MySQL对于count(*)这样的操作,不管遍历那个索引树得到的结果在逻辑上都一样。
因此,优化器会找到最小的那棵树来遍历,在保证正确的逻辑前提下,尽量减少扫描数据量,是数据库系统设计的通用法则之一。
问题:为什么存储的有数据怎么不用?
这个图的数据怎么得到的,我想你应该知道了,没错,就是执行show table status \G;得来的。
那为什么innodb存储引擎不直接使用Rows这个值呢?
还记不记得在第六期文章中,五分钟,让你明白MySQL是怎么选择索引《死磕MySQL系列 六》
先不要返回去看这篇文章,看下上文图中最后查到的数据总条数是多少。
你会发现这两个统计的数据是不一致的,因此这个值肯定是不可以用的。
具体原因
因为Rows这个值跟索引基数Cardinality一样,都是通过采样统计的。
采样规则
首先,会选出N个数据页,然后统计每个数据页上不同的值,最后得到一个平均值。再用这个平均值乘索引的数据页总数得到的就是索引基数。
并且这个索引基数也不是一成不变的,会随着数据持续增删改,当变更的数据超过1/M时才会触发,M值是根据MySQL参数innodb_stats_persistent得到的,设置为on是10,off是16。
在MySQL8.0这个默认值为on,也就是说当这张表的数据变更超过总数据的1/10就会重新触发采样统计。
三、不同count的用法
以下所有的结论都基于MySQL的Innodb存储引擎。
count(主键ID)
innodb引擎会遍历整张表,把每一行的ID值都拿出来,然后返回给server层,server层拿到ID后,判断不可能为空,进行累加。
count(1)
同样遍历整张表,但不取值,server层对返回的每一行,放一个数字1进去,判断是不可能为空的,按行累加。
count(字段)
分为两种情况,字段定义为not null和null
- 为not null时:逐行从记录里面读出这个字段,判断不能为null,累加
- 为 null时:执行时,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
count(*)
这个哥们就厉害了,不是带了*就把所有值取出来,而是MySQL做了专门的优化,count ( * )肯定不是null,按行累加。
结论
按照效率的话,字段 < 主键ID < 1 ~ ,最好都使用count(),别花里胡哨的。
五、总结
本期文章就一句话,统计总数就用count(*),别花里胡哨的。
这篇关于拒绝花里胡哨,MySQL统计总数就用count(*)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




