本文主要是介绍localforage-本地存储的优化方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
前端本地化存储算是一个老生常谈的话题了,我们对于 cookies、Web Storage(sessionStorage、localStorage)的使用已经非常熟悉,在面试与实际操作之中也会经常遇到相关的问题,但这些本地化存储的方式还存在一些缺陷,比较明显的缺点如下:
存储量小:即使是web storage的存储量最大也只有 5M
存取不方便:存入的内容会经过序列化,当存入非字符串的时候,取值的时候需要通过反序列化。
当我们的存储量比较大的时候,我们一定会想到我们的 indexedDB,让我们在浏览器中也可以使用数据库这种形式来玩转本地化存储,然而 indexedDB 的使用是比较繁琐而复杂的,有一定的学习成本,但第三方库 localForage 的出现几乎抹平了这个缺陷,让我们轻松无负担的在浏览器中使用 indexedDB。
什么是 indexedDB?
IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象)。
存取方便
IndexedDB 是一个基于 JavaScript 的面向对象数据库。IndexedDB 允许你存储和检索用键索引的对象;可以存储结构化克隆算法支持的任何对象。
之前我们使用 webStorage 存储对象或数组的时候,还需要先经过先序列化为字符串,取值的时候需要经过反序列化,那indexedDB就比较完美的解决了这个问题,可以轻松存取对象或数组等结构化克隆算法支持的任何对象。
异步存取
我相信你肯定会思考一个问题:localStorage如果存储内容多的话会消耗内存空间,会导致页面变卡。那么 IndexedDB 存储量过多的话会导致页面变卡吗?
不会有太大影响,因为 IndexedDB 的读取和存储都是异步的,不会阻塞浏览器进程。
庞大的存储量
IndexedDB 的储存空间比LocalStorage 大得多,一般可达到500M,甚至没有上限。
关于 indexedDB 的介绍就到此为止,详细使用在此不再赘述,因为本篇文章我重点想介绍的是 localForage!
什么是 localForage?
localForage 是基于 indexedDB 封装的库,通过它我们可以简化 IndexedDB 的使用。
兼容性
通常涉及到这类型的技术,我们都会考虑一个问题,那就是浏览器的兼容性。我们可以看下 localStorage 与 indexedDB 兼容性比对,两者之间还是有一些小差距。
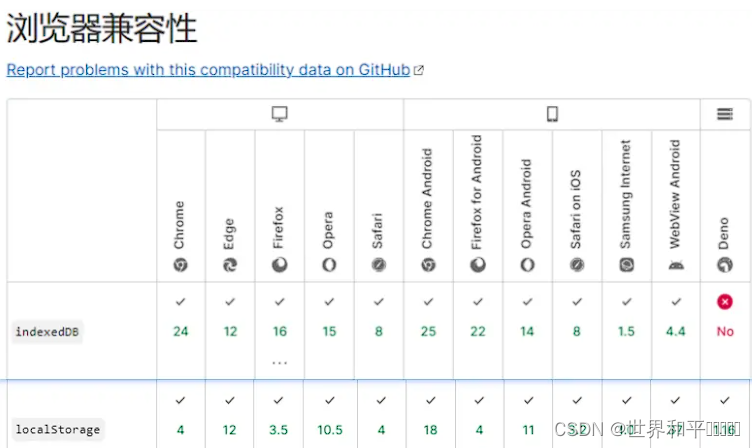
但是你也不必太过担心,因为 localforage 已经帮你消除了这个心智负担,它有一个优雅降级策略,若浏览器不支持 IndexedDB 则使用 WebSQL ,如果不支持 WebSQL 则使用 localStorage。在所有主流浏览器中都可用:Chrome,Firefox,IE 和 Safari(包括 Safari Mobile)。
localForage 的使用
①使用
import localforage from 'localforage'
②创建一个 indexedDB
const myIndexedDB = localforage.createInstance({name: 'myIndexedDB',
})
③存值
myIndexedDB.setItem(key, value)
④取值
由于indexedDB的存取都是异步的,建议使用 promise.then() 或 async/await 去读值
myIndexedDB.getItem('somekey').then(function (value) {// we got our value
}).catch(function (err) {// we got an error
});
或者
try {const value = await myIndexedDB.getItem('somekey');// This code runs once the value has been loaded// from the offline store.console.log(value);
} catch (err) {// This code runs if there were any errors.console.log(err);
}
⑤删除
myIndexedDB.removeItem('somekey')
⑥重置数据库
myIndexedDB.clear()
VUE 推荐使用 Pinia 管理 localForage
如果你想使用多个数据库,建议通过 pinia 统一管理所有的数据库,这样数据的流向会更明晰,数据库相关的操作都写在 store 中,让你的数据库更规范化。
// store/indexedDB.ts
import { defineStore } from 'pinia'
import localforage from 'localforage'export const useIndexedDBStore = defineStore('indexedDB', {state: () => ({filesDB: localforage.createInstance({name: 'filesDB',}),usersDB: localforage.createInstance({name: 'usersDB',}),responseDB: localforage.createInstance({name: 'responseDB',}),}),actions: {async setfilesDB(key: string, value: any) {this.filesDB.setItem(key, value)},}
})通过调用store来使用库:
import { useIndexedDBStore } from '@/store/indexedDB'
const indexedDBStore = useIndexedDBStore()
const file1 = {a: 'hello'}
indexedDBStore.setfilesDB('file1', file1)
这篇关于localforage-本地存储的优化方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



