一、问题概述
手机用户在使用短信、通话等业务、开关机、位置更新等的时候均产生定位数据,每条定位数据均包含了手机用户所处基站的编号、时间和唯一标识用户的EMASI号等。
将每个基站覆盖区域视为一个商圈,通过归纳基站覆盖区域的人流量和人均停留时间等特征,即可划分出不同类别的商圈。然后挑选出高价值商圈,并结合商圈用户活动特点,有针对性开展促销等活动。
现在共有431名用户的定位信息(Excel格式),包含用户编号以及如下考查指标:
1.人均流量:反应商圈的大致用户密度
2.工作日上班时段人均停留时间:用以识别上班人群集中的商圈
3.凌晨人均停留时间:用以识别住宅区居民集中的商圈
4.周末人均停留时间:用以识别周末时段人群集中的商圈
分析主要分两步,首先用tableau进行可视化分析,了解各基站(商圈)的大致情况;然后通过机器学习,采用聚类算法,对各商圈进行进一步的标识。
二、初步分析
从以下图中,可以看到各商圈的日均人流量和各时段的停留时间情况。其中在人均停留时间的三张图中,均有明显的断层现象,我们可以初步判定,断层处即为商圈的类别划分点,断层左边的商圈表示该时段人均停留时间长,右边表示停留时间短。

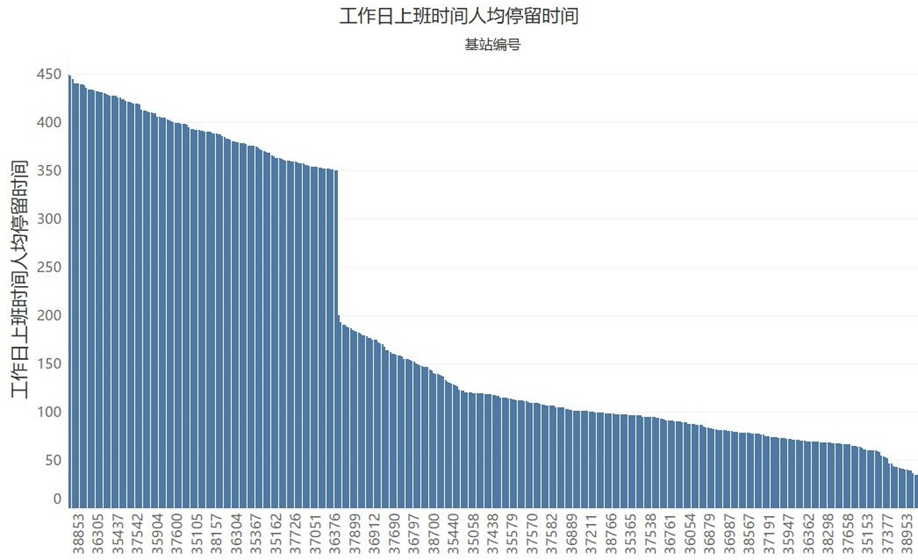
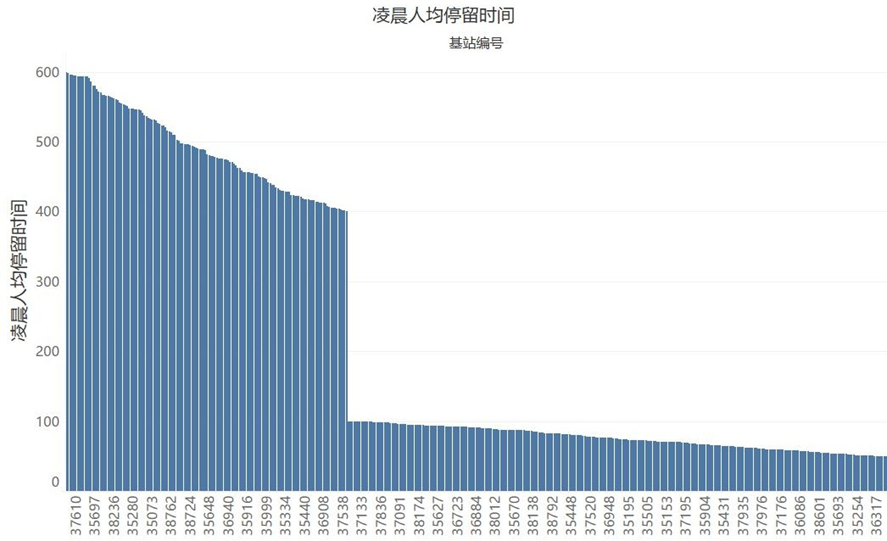
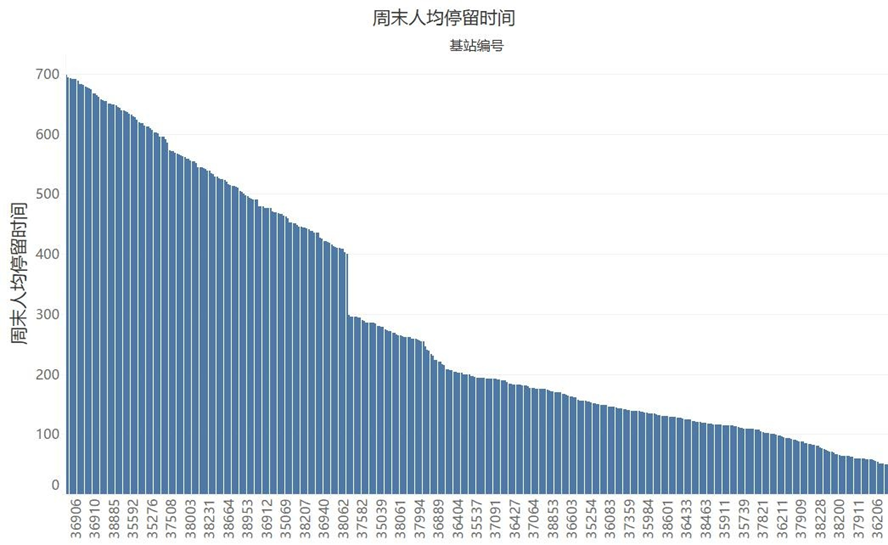
三、聚类分析
由于各个属性之间的数量级相差较大,在进行聚类前,需要进行离差标准化处理,即将各属性数据按比例缩放到一定范围,得到建模数据。
代码如下:
import pandas as pd
import sklearn.preprocessing as prc
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号data=pd.read_excel("../data/business_circle.xls") # 读取数据pm=prc.MinMaxScaler()
data_rd=pm.fit_transform(data.ix[:,1:]) # 数据标准化
data_rd= pd.DataFrame(data_rd,columns=data.columns[1:]) # 标准化后的数据重新转为df格式
采用层次聚类算法对建模数据进行聚类,画出谱系聚类图 。聚类类别数取3 ,根据聚类结果,输出聚类结果存入excel,并绘制各类别的四个特征折线图。
代码如下:
import pandas as pd
import sklearn.preprocessing as prc
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号data=pd.read_excel("../data/business_circle.xls") # 读取数据pm=prc.MinMaxScaler()
data_rd=pm.fit_transform(data.ix[:,1:]) # 数据标准化
data_rd=pd.DataFrame(data_rd,columns=data.columns[1:]) # 标准化后的数据重新转为df格式# print(data_rd)from scipy.cluster.hierarchy import linkage,dendrogram # 导入scipy的层次聚类函数
Z=linkage(data_rd,method="ward",metric="euclidean") # 谱系聚类图
P=dendrogram(Z,0) # 画谱系聚类图
# plt.show()from sklearn.cluster import AgglomerativeClustering # 导入sklearn的层次聚类函数
model = AgglomerativeClustering(n_clusters = 3, linkage = 'ward') # 设置参数,建立模型
model.fit(data_rd) # 训练模型r= pd.concat([data_rd,pd.Series(model.labels_,index = data_rd.index)],axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data_rd.columns) + [u'聚类类别'] # 重命名表头style = ['ro-', 'go-', 'bo-']
xlabels = [u'工作日上班时间人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']
pic_output = '../result/picture/type_' # 聚类图片文件名前缀for i in range(3): # 逐一作图,作出不同样式plt.figure()tmp = r[r[u'聚类类别'] == i].ix[:, :4] # 提取每一类,用于绘制折线图data_rs=r[r[u'聚类类别'] == i].ix[:,:] # 提取每一类,包含类别号data_rs=pd.merge(data,data_rs,how="outer", \on=[u'工作日上班时间人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量'], \) # 加上基站编号,再用于输出data_rs["聚类类别"] = i + 1data_rs.to_excel("../result/data"+str(i+1)+".xls") # 每一类保存为一个单独excel文件for j in range(len(tmp)):plt.plot(range(1, 5), tmp.iloc[j], style[i])plt.xticks(range(1, 5), xlabels, rotation=20) # 坐标标签plt.title(u'商圈类别%s' % (i + 1)) # 商圈类别名称,从1开始编号plt.subplots_adjust(bottom=0.15) # 调整底部plt.savefig(u'%s%s.png' % (pic_output, i)) # 保存图片
谱系聚类图:
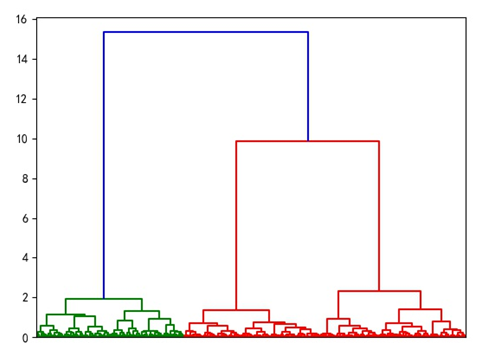
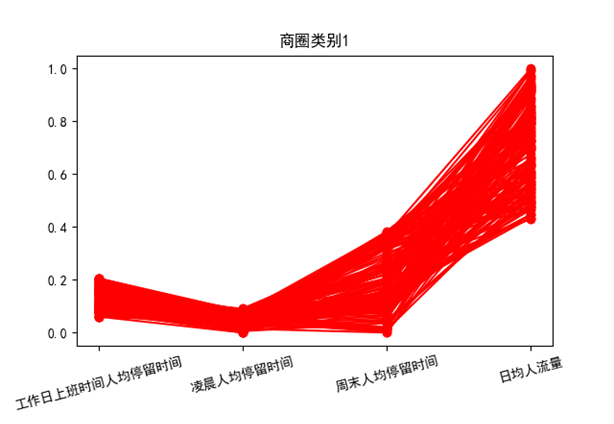
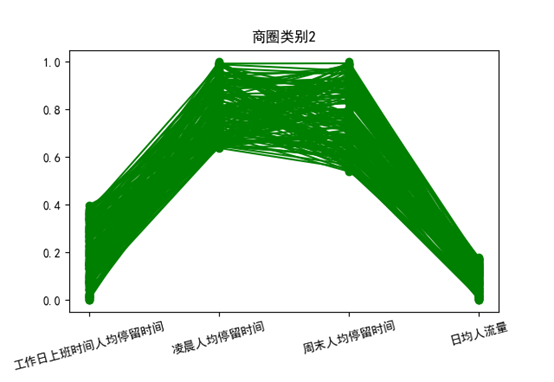
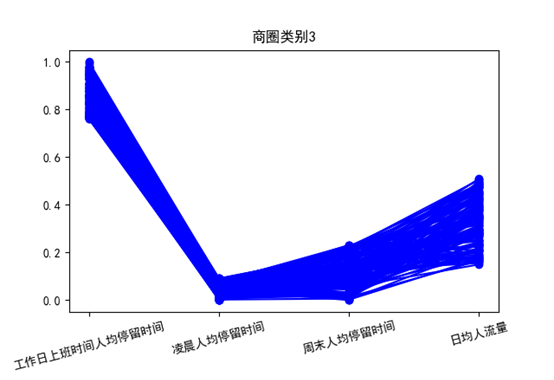
从以上三张图来看
类别2凌晨和周末人均停留时间较长,工作日人均停留时间短,日均人流量小,可以认为是住宅区域。
类别3工作日人均停留时间长,凌晨和周末人均停留时间较短,人流量偏小,可以认为是工作区域。
以上两类区域,如果开展促销活动,可以考虑采取一些针对居民和上班族特点的方式。
类别1在3个时段人均停留时间均不长,但人流量最大,我们认为这类人群相对于住宅区居民和上班人士,往往会对促销之类活动更有兴趣,因此,该类商圈是最宜进行促销的。在输出的结果文件中找到该类的基站编号,即能确定具体的活动地点。




