本文主要是介绍Twitter推特开源机器学习算法学习——For You重排名器及TwHIN嵌入特征算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Twitter推特开源机器学习算法学习——For You重排名器及TwHIN嵌入特征算法
- 系统核心部分
- 机器学习算法
- The "For You" Heavy Ranker
- 1、简介
- 2、开发
- 3、python源码
- TwHIN embeddings
- 1、简介
- 2、工作流
- 3、python源码
- 其它资料下载

2023年3月31日,Twitter 部分推荐算法源码正式在 GitHub 上开放,采用 GNU Affero General Public License v3.0许可证。短短一星期,Github中该推荐算法源码已经取得了**50k+**的Star关注,可见其在算法技术圈中的火爆程度。
今天我们就来重点分析该推荐算法系统中最重要的机器学习算法。再此之前,我们先来简单看看该推荐系统的核心部分,官方博客参考链接:Twitter’s Recommendation Algorithm
系统核心部分
Twitter 官博重点介绍了Twitter如何每天从5亿条推文中展示部分精选内容,也就是“For You”列表下的算法相关推荐机制和排名。
Twitter 算法推荐的基础是一组核心模型和特征,从推文、用户和互动数据中提取潜在信息。推荐流水线由三个主要阶段组成,这些阶段使用这些特征:
1、从不同的推荐来源中获取最佳推文,这个过程称为获取候选推文;
2、使用机器学习模型对每个推文进行排名;
3、应用启发式和过滤器,例如过滤用已屏蔽用户的推文、NSFW 内容和已经看过的推文等。
负责构建和提供 For You 时间线的服务称为 Home Mixer。Home Mixer 基于 Product Mixer 构建,Product Mixer 是 Twitter 自定义的 Scala 框架,可以帮助构建内容流。该服务充当软件骨干,连接不同的候选源、评分函数、启发式和过滤器。
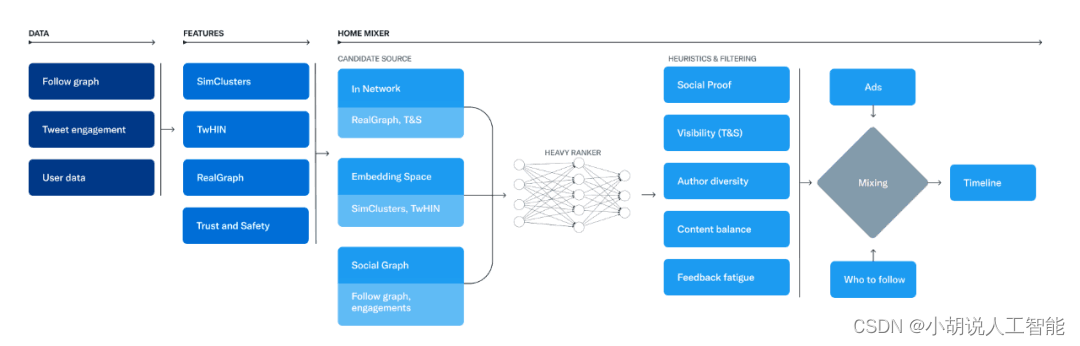
一句话可以总结为:Twitter先获取和你相关的各类推文,然后进行推文排名,最后将广告、关注建议和登录提示等非推文内容与排名出来的推文混合,最终展示到你设备上的For you内容,如下图所示。
机器学习算法
博主对Twitter开源出的推文排名的机器学习算法,比较感兴趣。我们先看下在这次项目开源过程中开源的最重要的两块ML模型:
- The “For You” Heavy Ranker: For You 重排名器算法
- TwHIN embeddings:TwHIN 嵌入算法
The “For You” Heavy Ranker
1、简介
重排名器是用于对已经通过候选检索阶段的“For You”时间轴的推文进行排名的机器学习模型。它是漏斗的最后阶段之一,主要由一组过滤启发式成功。
该模型接收描述推文和推文被推荐给的用户的特征(具体可参考FEATURES.md)。关于Features的详细解析,博主放到后面再进行研究分析。模型架构是一个并行的MaskNet算法,它输出一组0到1之间的数字,每个输出代表用户以特定方式参与推文的概率。预测的参与类型解释如下:
scored_tweets_model_weight_fav:用户喜欢这条Tweet的概率。
scored_tweets_model_weight_rettwitter:用户转发该Tweet的概率。
scored_tweets_model_weight_reply:用户回复Tweet的概率。
scored_tweets_model_weight_good_profile_click:用户打开推文作者配置文件并点赞或回复推文的概率。
scored_tweets_model_weight_video_playback50:用户至少看一半视频的概率。
scored_tweets_model_weight_reply_engaged_by_author:用户回复Tweet并且该回复被Tweet作者占用的概率。
scored_tweets_model_weight_good_click:用户点击进入该推文对话并回复或点赞推文的概率。
scored_tweets_model_weight_good_click_v2:用户点击进入这条Tweet对话并在那里停留至少2分钟的概率。
scored_tweets_model_weight_negative_feedback_v2:用户做出负面反应的概率(请求在Tweet或作者、block 或mute上“少显示”)
通过跨预测的参与概率进行加权求和,将模型的输出组合成最终模型分数。每个参与概率的权重来自配置文件,由这里的ScoredTweetsParam.scala文件服务堆栈读取。文件中的确切权重可以随时调整,但当前概率权重(2023年4月5日)如下:
scored_tweets_model_weight_fav: 0.5
scored_tweets_model_weight_retweet: 1.0
scored_tweets_model_weight_reply: 13.5
scored_tweets_model_weight_good_profile_click: 12.0
scored_tweets_model_weight_video_playback50: 0.005
scored_tweets_model_weight_reply_engaged_by_author: 75.0
scored_tweets_model_weight_good_click: 11.0
scored_tweets_model_weight_good_click_v2: 10.0
scored_tweets_model_weight_negative_feedback_v2: -74.0
scored_tweets_model_weight_report: -369.0
公式如下:
score = sum_i { (weight of engagement i) * (probability of engagement i) }
由于每个engagement 具有不同的平均概率,所以权重最初被设置为平均,即每个加权的engagement概率对分数贡献几乎相等的量。从那时起,我们定期调整权重,以优化平台指标。
一些免责声明:
由于需要确保它独立于Twitter代码库的其他部分运行,因此与生产模型可能会有一些小的差异。
由于隐私限制,我们无法发布真实的训练数据。但是,我们已经包含了一个脚本来生成随机数据,以确保您可以运行模型训练代码。
2、开发
按照repo设置说明操作后,您可以在虚拟环境中运行以下脚本,在 $HOME/tmp/recap_local_random_data 中创建随机训练数据集:
projects/home/recap/scripts/create_random_data.sh
然后,您可以使用以下脚本训练模型。检查点和日志将写入 $HOME/tmp/runs/recap_local_debug :
projects/home/recap/scripts/run_local.sh
可以在 projects/home/recap/config/local_prod.yaml 中配置模型训练
3、python源码
详见官方Twitter Github。
TwHIN embeddings
1、简介
该算法包含用于预训练Twitter实体的密集向量嵌入功能的代码。在Twitter中,这些嵌入用于候选检索,并作为各种推荐系统模型中的模型特征。
我们基于Twitter中的各种图形数据获得实体嵌入,例如:“用户关注用户”“用户收藏夹推文”“用户点击广告”
虽然由于隐私限制,我们无法发布用于训练TwHIN嵌入的图形数据,但可以使用大量子采样的匿名开源图形数据: https://huggingface.co/datasets/Twitter/TwitterFollowGraph https://huggingface.co/datasets/Twitter/TwitterFaveGraph
代码要求parquet文件包含三列:lhs、rel、rhs,分别表示图中每条边的左侧节点、关系类型和右侧节点的词汇索引。
必须在projects/twhin/configs中的配置yaml文件中指定数据的位置。
2、工作流
1)构建本地开发映像
./scripts/build_images.sh
2)运行Docker环境命令
./scripts/docker_run.sh
3)迭代训练图像
./scripts/idocker.sh
4)运行测试
./scripts/docker_test.sh
3、python源码
详见官方Twitter Github。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于Twitter推特开源机器学习算法学习——For You重排名器及TwHIN嵌入特征算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



