本文主要是介绍IPFS小明师兄《Filecoin分析专场》直播文字版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Filecoin测试网即将上线,你准备好了吗?为了让广大FIL爱好者第一时间参与测试,星际大陆CTO小明师兄在27日(周四)晚八点进行了一个小时的直播课程之旅,为大家倾情献上自己对FIL的研究成果。同时,直播期间还设置了VNS代币抽奖活动,一度将活动热度引向高潮。重点直播内容概况如下:
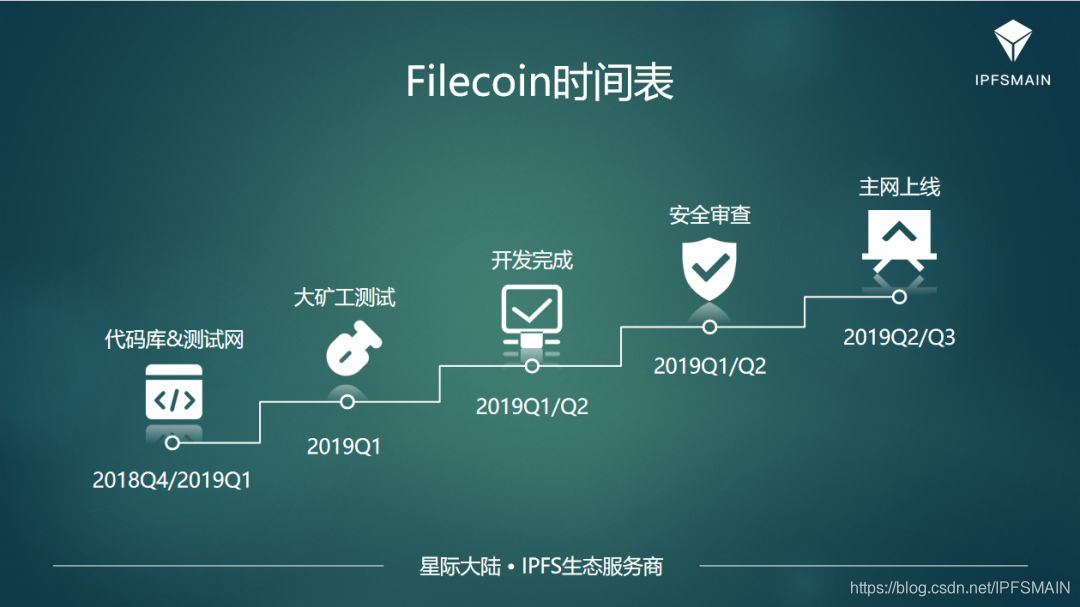
1、核心问题:关于Filecoin时间表
(1) 协议实验室在2018年8月份,发布了Q1、Q2的更新。如果不出现延期的话,2019年Q1将迎来测试网。
(2) 在测试网发布之前,会有一个重要的阶段即发布挖矿的硬件标准以及代码库的打开。代码库的打开对于所有挖矿矿工和厂商来说,都是非常重要的时刻。代码库打开之前,是不会上线测试网的,所以大家还有时间准备。(3) 所有矿工都可以参与测试网,测试网后期会进行大矿工测试,主要测试大容量下的网络性能,测试成本很高,小矿工可以不参与。(4) 测试网之后是代码冻结,代表开发完成。开发完成与安全审查是同步进行的。对于一个合格的区块链项目来说,进行严格的安全审核是必备阶段。矿工判断一个项目是不是真项目,除了开源之外,这是第二个重要的因素。(5) 乐观时间表显示2019Q3能如期迎来主网上线。矿工无需着急,可以等测试网上线或者明确测试网上线时间之后再准备。(6) 所有准确时间以官方公告为准,星际大陆也会随时关注官方动态,有新消息都会公告。

2、核心问题:测试网有收益吗?
(1) 根据星际大陆与官方沟通的情况显示,测试网可能存储部分的激励措施。官方希望有更多的人参与测试网,因为测试有一定的运营成本,所以适当的激励是合理的,但具体的奖励措施还不明确。
(2) 测试网激励应该不会是所谓的测试币,并且测试币应该不可能兑换成真币的。(3) 具体激励措施以官方公告为准,不要相信任何第三方的承诺,不排除没有找到好的激励措施不实行测试网激励的可能。

3、核心问题:如何测算收益
对于大家关心的多久能够回本?直接答案目前还无法告知,但可以通过一定的模型进行大概的测算。具体如下:
(1) 挖矿利润=收益(区块奖励+存储收益+检索收益)- 成本(矿机成本+运营成本)。
(2) 收益包含区块奖励(含交易手续费)、存储收益、检索收益。(3) 成本包括矿机、硬盘和运营成本,运营成本包括场地、宽带费、电费、人工费等。(4) 从长期来看,同等条件下运营成本的降低成为企业能否实现长期盈利的核心竞争力。

4、核心问题:如何测算区块奖励
(1) 根据之前官方公布的分币方式,矿工总量14亿,6年分发一半,即前6年平均每天分发32万个,根据分发曲线,主网上线初期会大于32万个,大约33万个左右。
(2) 因此可以得出结论:以平均每天分发32万个来计算,平均每秒钟大约3.7个Fil,具体到每个区块分多少需要看上线时平均每个区块的周期是多少。假设30秒为一个区块周期来计算,平均每个区块的奖励大约为111个FIL。(3) 假设每30秒一个区块,那么平均每天的区块数大约为2880,这些奖励是早期矿工争夺的重点。

5、核心问题:矿工多久能获得打包一个区块的奖励?
① 每个矿工能获得打包区块的概率与矿工的有效存储成正比。
② 计算方法:矿工的有效存储/全网有效存储>=radom(0,1)。③ 举例:如果一个矿工有效存储为100TB,当全网有效存储达到1EB时,打包一个区块的概率为100/1/1024/1024=0.000095367,一天打包一个区块的概率约为24%。④ 每TB有效存储获得的奖励是随着全网有效存储的增长而减少,假设全网存储达到1EB,平均每T有效存储区块链奖励每月9.42个,当全网存储达逐渐变大,奖励则会逐渐变少。按此逻辑推断,早期矿工应该相对会更有优势。

6、核心问题:存储收益和检索收益有多少
(1)存储收益和检索收益目前无法做出预测。Filecoin上线初期,大家可能都会想争夺区块奖励,这时候存储订单报价可能会非常低,甚至可能为零。但是挂单为零可能存在长期风险,大家需要注意,因为挂单为零,意味着你放弃了存储长期收益,只是能得到区块奖励和检索收益。检索收益取决于存的数据是否会被频繁获取。
(2)存储收益和检索收益可以用中心化云储存和流量的价格进行对比。亚马逊每T每月流量是630元,存储是182元;阿里每月每T流量包是505元,存储包是111元。Filecoin这二部分收益上线初期应该要比中心化的云便宜不少。

7、核心问题:家庭网络能不能挖矿
(1) 根据目前的研究结果,Filecoin的底层网络传输用的是IPFS。矿工要参与Filecoin挖矿,就必须把矿机暴露在外网,让存储数据的用户能够连上矿工,并给矿工发送数据以及数据被用户检索。目前IPFS网络没有解决多层NAT穿透的问题,我们测试的结果是一层NAT穿透应该没有问题。
(2) 非IDC宽带开通时默认矿工基本都处于二层NAT以内,解决办法是要求运营商分配一个公网IP,这样路由器就会获得一个公网IP,并打开路由器的upnp转发(部分路由器好像不支持这个功能),这样就可以使矿机暴露在外网。(3) 目前协议实验室已经意识到这个问题,并已经将此纳入2019年的重点目标,相信在不久的将来IPFS团队能彻底解决这个问题,所以大家不必过份担心。(4) 有些矿机厂商声称自己出售的矿机解决了这个问题,这是一种销售的误导行为。我想稍微懂点网络知识的人都清楚,这与矿机本机无关,请大家多了解点相关知识,以免受诱导。

8、核心问题:挖矿需要哪些配套软件
(1) Filecoin挖矿是一种需要高度运营的挖矿方式,与比特币和以太坊等挖矿方式不一样,Filecoin挖矿在矿机、用电、网络等方面的稳定要求较高,因此矿机监控软件将会发挥重大的作用。
(2) 对于大型矿工来说,批量管理矿工的工具也是必不可少,批量管理软件还将集成一键检测自己的挖矿环境到底能不能够满足挖矿条件的功能。 (3) 另外,每个矿工都很关注挖矿收益,拥有一个随时随地都可以查看矿机收益和状态的工具很重要。(4) 整个配套软件是一个复杂系统工程,软件需要考虑易用性、可扩展性、稳定性和并发能力等,并不是有就行,所以大家在购买矿机时需要仔细考察厂商的软件实力,一款好的配套软件将助力你无忧无虑的挖矿。(5) 除了配套软件以外,厂家也需要具备挖矿数据分析能力,这是厂家能否实现长期运营挖矿的重要衡量标准。(6) 目前星际大陆挖矿配套软件开发已经接近尾声,部分功能需要等待Filecoin代码库打开以及标准API接口发布后继续完善,我们将在测试网期间逐步发布配套软件,大家可持续关注星际大陆官方微信公众号。

9、核心问题:如何自建矿场
(1) 对于矿场如何选址,星际大陆已经对全国十几个城市做了网络延迟数据比较。我们发现,从全国范围内看,各个主要城市之间的网络延迟并不会太大。
(2) 对于大型矿工,会面临选择IDC和自建矿场的困惑,二者各有优势,IDC在挖矿环境、稳定性、网络质量等方面应该优于自建矿场,但缺点可能是成本较高。自建矿场成本较对来说稳定性不如IDC,但是成本可以降低一些。(3) 二种方式取决于大型矿工的资源和经验,具备优势资源的矿工可以考虑采用自建的方式。在没有数据监测之前,星际大陆不能给出明确选择,大家可以根据自己的研究来判断。(4) 星际大陆已建设模拟了一个实验型Filecoin矿场,我们欢迎大型矿工来参观交流,我们在自建矿场上积累了一定的经验,可以为大型矿工提供全方位的自建矿场指导服务。(5) 对于宽带的选择,每个人都有自己的选择理由,个人认为,大家要根据自己的需求进行选择。如果你想偷懒,怕麻烦,你可以找稳定、贵的。对于小型矿工,我建议,可能托管为主会比较好,挖矿需要经营,如果小矿工没有经验和精力去维护管理,可能会出现挖矿风险。最后,再次感谢融实体、金融及技术为一体的区块链生态平台VNS,VNS致力于探索区块链技术与实际应用的结合,秉承“创造价值、传递价值、实现价值互联”的理念,打造信任、共赢的区块链生态环境。VNS的获取方式为纯挖矿获取,贯彻POW多劳多得的理念,人人皆可参与,付出即有所得。还要感谢一起玩转区块链的区块链研习社、区块链金融科技第一短视频媒体米林财经、专注于区块链项目报道的链茶馆、每天一分钟,读懂区块链的五六财经、新金融投资人智库33财经、ipfs技术产业联盟、公信宝社区、币市小姐姐等的大力支持。
这篇关于IPFS小明师兄《Filecoin分析专场》直播文字版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






