本文主要是介绍标准图数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、节点分类
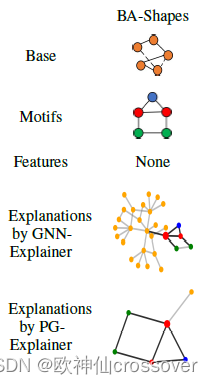
1. BA-Shapes:单图,包括一个300节点的Barabasi-Albert(BA)子图和80个“房子”图案,这些图案被随机的加在BA图的节点上,并且加入随机边进行干扰。
该图没有节点特征。节点在基本图上是类型0,在“房子”的顶部,中部,底部分别为类型1-3.
2.BA-community:包含两个BA图(社区),每一个BA图的节点特征符合高斯分布,根据不同社区的不同成员身份总共分成8个类

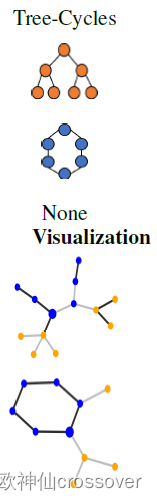
3. Tree-Cycles:二分树作为基图,80个6节点循环图被附加于基本图随机节点上。
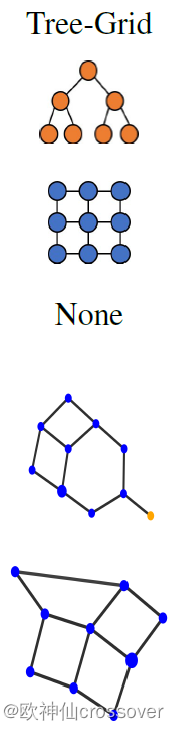
4. Tree-Grid:基本图与Tree-Cycles类似,但用3×3的网络图代替循环图。
二、 图分类
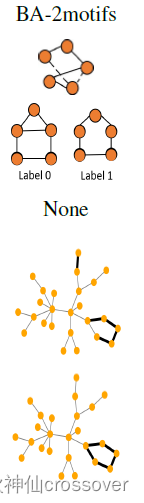
1. BA-2motifs dataset:800个子图,采用BA图为基图,一半的附加图为“房子”图案,其余是附有5节点的循环图案(根据附加图的不同,可分为2种类型的图)
2. MUTAG(真实图):由4337个分子图组成,根据诱变效应分为两类。碳环中含有NH2和NO2原子团被认为是有诱变性的,而没有诱变性的分子也含有碳环。因此,我们可以将碳环作为基本图(共有图),将NH2和NO2原子团作为突变基图的基序(附加图,判据图)
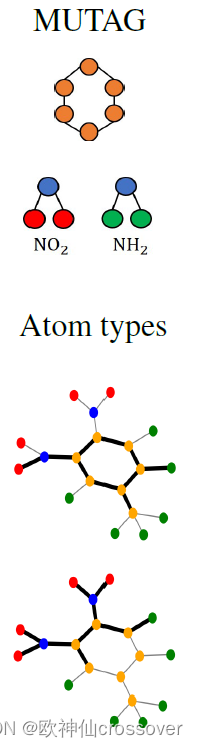

三、评估指标
1、定性评估:在上面的图示中,黑边表示具有重要权重的边(按top-k排序)。并且可以明显地看出高权重边被赋予BA-Shapes和BA-Community的“house”图,Tree-Cycles和BA-2motifs的循环图,Tree-Grid的网格图,以及MUTAG的NO2原子团。
2、定量评估:此处将解释问题量化为边的二元分类。将重要图案的边视为正性边,否则为负性边。解释方法所得出的重要性权重被视为预测得分。较好的解释方法是赋予真实重要图案的边较高的权重,采用AUC作为定量评估的指标。特别地,对于MUTAG数据集,只考虑诱导图,因为非诱导图不存在明显的诱变原子团。
每个实验重复10次,得出AUC的平均值和标准差。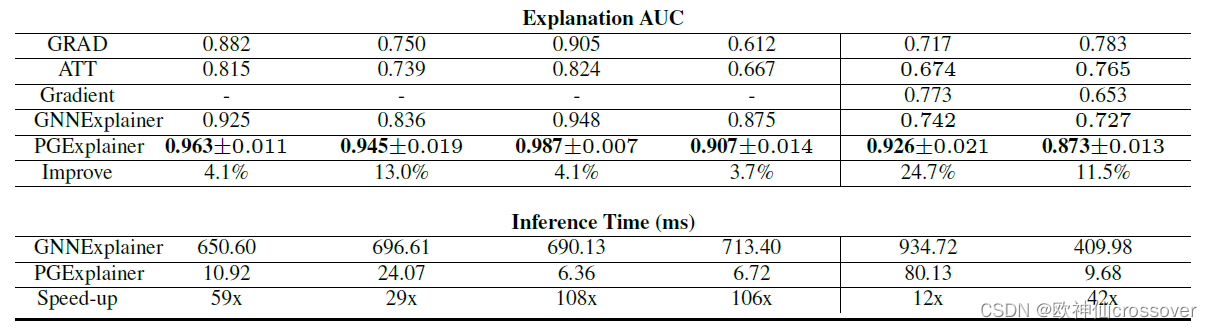
PGExplainer利用图生成模型的参数化解释网络,对多个实例共同提供解释。因此,PGExplainer可以拥有gnn的全局视图,这就解释了为什么PGExplainer可以比GNNExplainer表现得更好。
(38条消息) 模型评估指标AUC(area under the curve)_Webbley的博客-CSDN博客_auc值
3、效率评估:PGExplainer的解释网络可以在所有实例中共享(权值),因此,一个训练后的PGExplainer可以用来解释归纳设置中的新实例。用推理时间标识解释器解释一个新实例的时间,由于GNNExplainer必须对模型进行再训练,所以相比之下,PGExplainer大幅度降低推理时间,其计算效率是GNNExplainer的108倍,因此,PGExplainer更适合大规模数据。
4、归纳评估:
1)AUC随着训练实例的增加而增加。
2)训练的实例数越多,标准差越小,PGExplainer更倾向于全局检测共享图案,鲁班性更高。
3)PGExplainer只需要少量的训练实例就能取得相对较好的性能。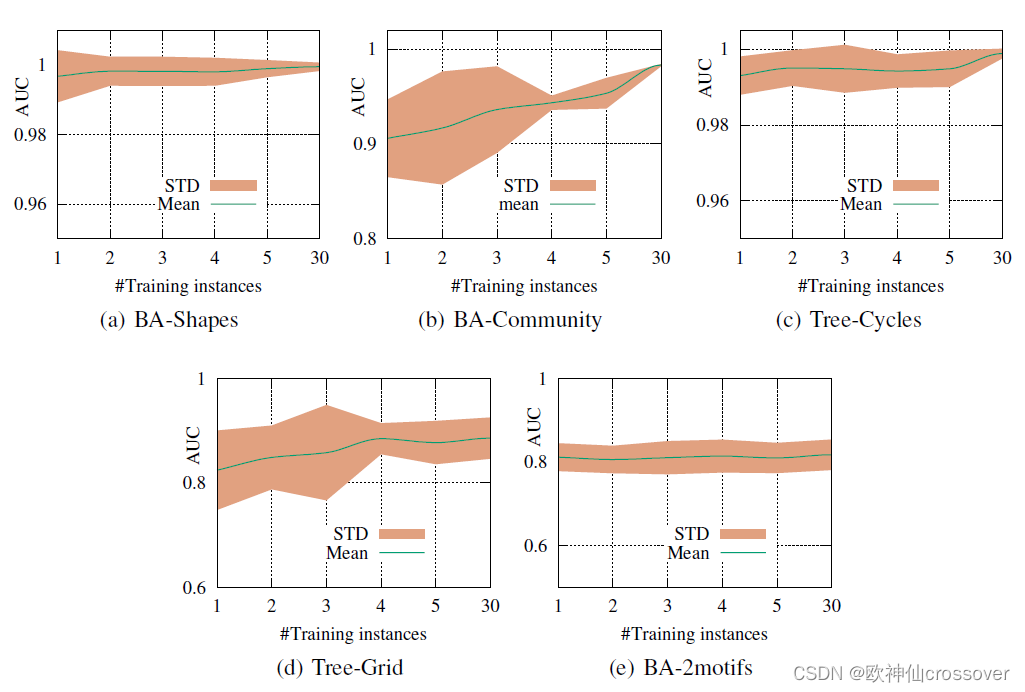
5、图大小和交叉熵约束性能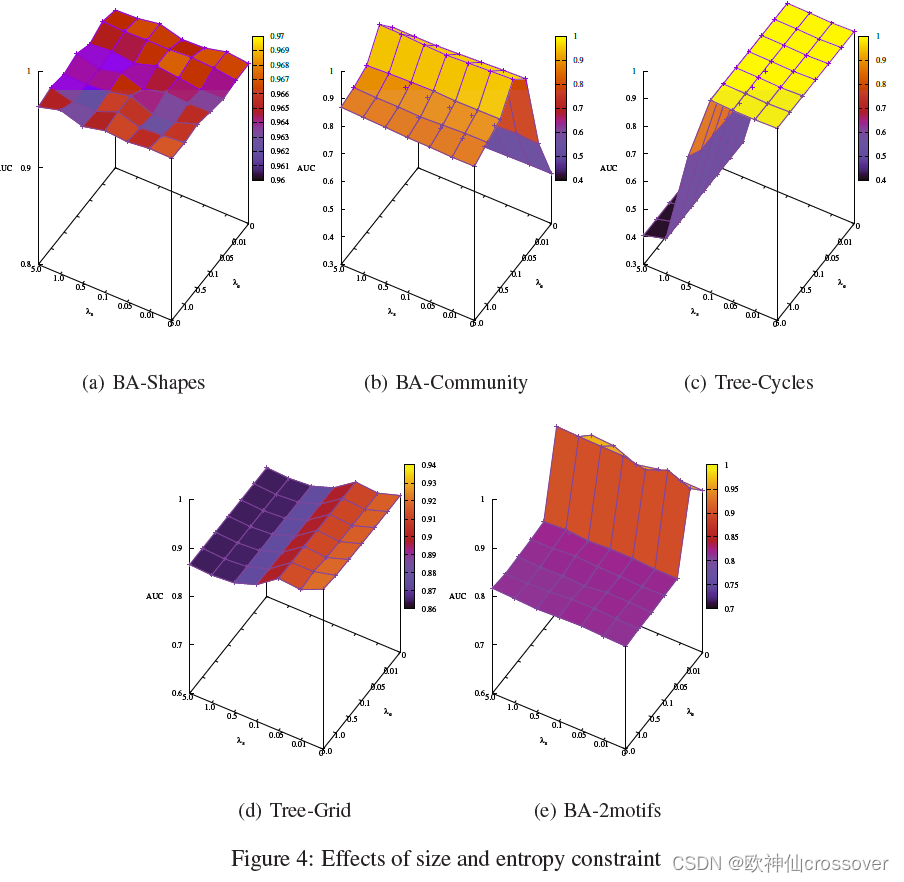
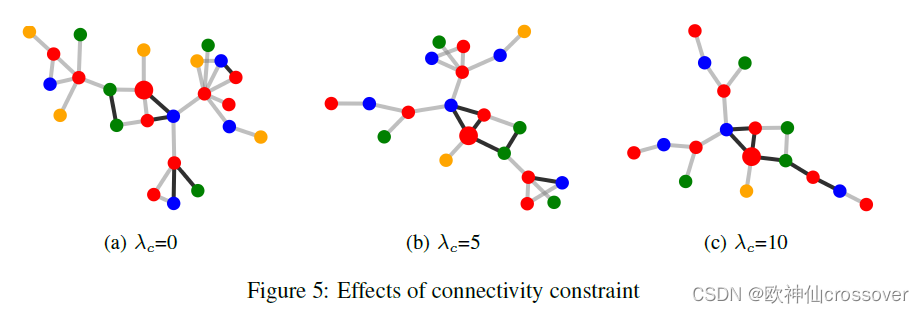
6、连通约束:
该类约束指的是更多的边会约束在重要节点上。下图可以看出,通过连通约束,PGExplainer更倾向于提供一个连通子图作为解释图。
7、特征选择:可以参考GNNExplainer做特征掩码。
这篇关于标准图数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





