本文主要是介绍Python爬取寻医问药网得到每个疾病的诱因和诱因上下位,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python爬取寻医问药网得到每个疾病的诱因和诱因上下位
- Python爬取寻医问药网得到每个疾病的诱因和诱因上下位
- 分析流程
- 代码
- 导包
- getHTMLText(url)
- main()
- processAPart(ch,path)
- processAnIllness(eachUrl,path)
- getFileName(path,soup)
- getAppositions(soup)
- getHypernymHyponym(soup)
- processPTextForSubtitle(text)
- processASubtitle(text,key)
- processASentence(str)
- getSentence(str,key)
- cutToPreviousComma(str,end)
- cutToBothComma(str,keyPos)
- ContainsNoImpurity(string)
- ifConcat(ch)
- notDigit(ch)
- 各个函数间的关系和流程图
- 各函数间关系
- 获取小标题
- 获取文本中诱因上下位
Python爬取寻医问药网得到每个疾病的诱因和诱因上下位
通过爬取寻医问药网的所有疾病,获取与筛选符合条件的每个疾病病因页面下相关的小标题(即诱因小标题)以及页面中基于诱因关键字,根据关键字前的语义分析是否提取子句以及如何提取子句(即文本中的诱因上下位)。
整个过程比较简单,说白了就是if else的嵌套和对整个流程的宏观把控。其中有些像分词什么的都是用的现成的python库。
本次作业是我大二的时候第一次接触爬虫写的,推荐视频:
Python网络爬虫与信息提取 北京理工大学:嵩天
看完前面33p就可以开始了。
结果大致是这样的:
 声明:本博客只作学习记录与交流用,不做任何盈利用途。
声明:本博客只作学习记录与交流用,不做任何盈利用途。
分析流程
1.到寻医问药网的疾病查询页面按字母查询获取到所有疾病的分区
2.在每个字母分区的页面中获取到该字母打头的所有疾病
3.转到每个疾病的病因页面
4.对于小标题:由于疾病很多,每一页病因的代码参次不齐,因此需要分情况提取
4.1在strong、b、h3这三个标签中有小标题的情况:
4.1.1直接获取这三个标题,然后判断是否满足要求,如发病病因,发病机制等这类标题需要过滤掉
4.2整个病因页面的文本仅仅只是一个p标签的情况(此情况比较复杂):
4.2.1创建一个标志词列表(后期可以发现更新),如(一)1.(1)①等
4.2.2对于整个文本从位置0开始查找是否含有标志词中的任一个
4.2.3含有则执行提取句子操作(同时需要判断句子是否满足提取条件如3.2%这类就不提取,因为3.在这里是数字,不是标题序号),还需要进行判断提取结束位置
4.2.4将提取标志词从文本中移除,再次从文本0开始查找,重复直到文本不再含有标志序号
5.对于文本中诱因关键字的上下位:
5.1创建一个诱因关键字的列表,如引起、导致、致使等等
5.2将整个p标签的文本利用python的zhon库进行中文分句
5.3再创建一个标志列表(里面放jieba分词的词性结果是实意动词的标志,如n,v,a,nt,ns等等)
5.4分别处理中文分句得到的句子:
5.4.1如果关键词前是虚词或者‘,’,则从关键字开始判断是否到提取边界,此类情况需要提取整个句子。
5.4.2如果关键词前到标点除(即关键词所在子句中关键词前部分),含有实意动词,如动词,名词等等,则从关键字开始判断是否到提取边界,此类情况需要提取分句即可。
6.将上面两个结果进行检查后拼串并输出写入文本
代码
导包
import requests
from bs4 import BeautifulSoup
import re#正则表达式
import bs4
import zhon#中文分句
from zhon import hanzi
import jieba.posseg as pseg #词性标注
import string
import os#建文件等
getHTMLText(url)
try:kv={'user-agent':'Mozilla/5.0'}r=requests.get(url,timeout=30,headers=kv)#伪装成浏览器r.raise_for_status()#异常处理r.encoding=r.apparent_encoding#编码设置return r.text#返回文本except:return "产生异常"
main()
main函数,依次处理每个按字母分区的疾病病因,输出并建立文件夹在G盘根目录下
def main():path='E:/数据分析与可视化/'if not os.path.exists(path):os.makedirs(path)for ch in 'abcdefghijklmnopqrstuvwxyz':try:processAPart(ch,path)except OSError:passcontinue
if __name__ == '__main__':main()
processAPart(ch,path)
处理一个字母分区
def processAPart(ch,path):url='http://jib.xywy.com/html/'+ch+'.html'r=getHTMLText(url)soup=BeautifulSoup(r,"html.parser")for li in soup.find_all('ul','ks-zm-list clearfix mt10'):if isinstance(li,bs4.element.Tag):for a in li.find_all('a'):if isinstance(a,bs4.element.Tag):eachUrl='{}{}'.format('http://jib.xywy.com/il_sii/cause/',a.attrs['href'][8:])processAnIllness(eachUrl,path)
processAnIllness(eachUrl,path)
处理一个疾病病因,输出小标题间同位关系和文本内容中诱因上下位关系
r=getHTMLText(url)soup=BeautifulSoup(r,"html.parser")path=getFileName(path,soup)string=getAppositions(soup)string='{0}{1}{2}'.format(string,'\n',getHypernymHyponym(soup))print(string)f=open(path,"w",encoding='utf-8')f.write(string)f.close
getFileName(path,soup)
给文件命名为病的名字
for title in soup.find_all('strong','fb db f20 fYaHei fb jib-articl-tit tc'):if isinstance(title,bs4.element.Tag):T='{}'.format(title.string) for ch in T:if ch is not ' ' and ch is not '\t' and ch is not '\n' and ch is not '//' and ch is not '\\': path='{}{}'.format(path,ch)path='{}{}'.format(path,'.txt')return path
getAppositions(soup)
得到同位关系
def getAppositions(soup):string=''for tag in soup.find_all('div','jib-articl fr f14 jib-lh-articl'):if isinstance(tag,bs4.element.Tag):#这一页的标题,xxx病因,在strong标签里for strong in tag.find_all('strong',recursive=False):#排除发病病因发病机制等字样if isinstance(tag,bs4.element.Tag) and ContainsNoImpurity(strong.string):if strong.string is not None:string='{0}{1}'.format(string,strong.string)#主要内容就在这一个p标签里for p in tag.find_all('p'):if isinstance(p,bs4.element.Tag) :#小标题在h3标签里,有的页面还在b标签里for h3 in p.find_all('h3'):if isinstance(h3,bs4.element.Tag) and ContainsNoImpurity(h3.text):string='{0}{1}'.format(string,h3.text)for b in p.find_all('b',recursive=False):if isinstance(b,bs4.element.Tag) and ContainsNoImpurity(b.string):string='{0}{1}{2}'.format(string,'\n',b.string)if isinstance(p,bs4.element.Tag):#有的页面的小标题还在strong标签for strong in p.find_all('strong',recursive=False):if isinstance(p,bs4.element.Tag):if strong.string is not None and ContainsNoImpurity(strong.string):string='{0}{1}{2}'.format(string,'\n',strong.string)return string
getHypernymHyponym(soup)
得到诱因上下位
string=''for tag in soup.find_all('div','jib-articl fr f14 jib-lh-articl'):if isinstance(tag,bs4.element.Tag):for p in tag.find_all('p',recursive=False):rst = re.findall(zhon.hanzi.sentence, p.text)res=processPTextForSubtitle(p.text)string='{0}{1}{2}'.format(string,res,'\n')string='{0}{1}'.format(string,'\n----------------上方为诱因小标题间的同位概念,下方为诱因上下位关系--------------\n')for str in rst:res=processASentence(str)if res is not None:string='{0}{1}{2}'.format(string,res,'\n')return string
processPTextForSubtitle(text)
在p标签里的小标题
def processPTextForSubtitle(text):#尽可能多的列出来小标题关键字string=''#序号必须按这个顺序排keys=['(一)','(二)','(三)','1、','2、','3、','4、','1.','2.','3.','4.','5.','6.','7.','(1)','①','②','(2)','(3)','(4)','(5)','(6)','(7)','①','②']flag=0i=0while i < len(keys):if text.find(keys[i],0,len(text)) is not -1:#包含标志if notDigit(text[text.find(keys[i],0,len(text))+2] ):res=processASubtitle(text,keys[i])#print(res)if res is not None:string='{0}{1}{2}'.format(string,res,'\n')flag=text.find(keys[i],0,len(text))+1text='{0}{1}'.format(text[:flag-1],text[flag+1:])#把这个标志从文本中剔除i=i-1i=i+1return string
processASubtitle(text,key)
处理小标题
def processASubtitle(text,key):string=''pos=text.find(key)text=text[pos:]#print(text)for ch in text:if ifConcat(ch):string+=chelse:min=8if min>len(string):min=len(string)if ContainsNoImpurity(string[:min]):if len(string)<100:return stringelse:return string[:100]
processASentence(str)
处理分句后的句子,如果存在诱因关键词则开始提取句子
def processASentence(str):keys=['引发','引起','可导致','导致','致使','致','使','有关','因为','原因','病因','诱因','因','诱发','影响']for word in keys:if str.find(word) != -1:return getSentence(str,word)
getSentence(str,key)
对于有诱因关键词的句子,先利用jieba分词判断是否有实意词,有则提取子句,无则返回整个句子
def getSentence(str,key):part=cutToPreviousComma(str,str.find(key))words=pseg.cut(part)notionals=['n','v','a','nt','ns','nr','an','vn','vg','nz','Ng','ad','Ag','s','vd','j']#这些都是实意词的标志for word,flag in words:if flag in notionals:#前面是实词,仅提取子句return cutToBothComma(str,str.find(key))#前面是情态动词,副词,连词,介词等虚词或者标点符号,提取整个句子return str
cutToPreviousComma(str,end)
从诱因关键词往前开始截取到标点符号处,前面没有标点符号就截取到str[0]用于判断诱因关键词前面是否有虚词
def cutToPreviousComma(str,end):start=endwhile start >= 1:#是汉字if '\u4e00' <= str[start] <= '\u9fff':start=start-1else:return str[start:end]return str[start:end]#这句别忘了,因为可能key前面是标点,那样就会返回none
cutToBothComma(str,keyPos)
对于前面有实意词的情况,截取子句
start=keyPosend=keyPoswhile end < len(str):if '\u4e00' <= str[end] <= '\u9fff':end=end+1else:breakwhile start >= 1:if '\u4e00' <= str[start] <= '\u9fff':start=start-1else:breakreturn str[start:end]
ContainsNoImpurity(string)
过滤杂质,排除发病病因发病机制等字样
flags=['其他','其它','发病','病因','病理生理','剖析']for flag in flags:if string is not None:if string.find(flag) is not -1:return Falsereturn True
ifConcat(ch)
判断是否到句子截取停止标志
flags=[':',':',' ',',',',','。','\n',',']for flag in flags:if ch == flag:return Falsereturn True
notDigit(ch)
排除是数字百分比的情况
for flag in '0123456789':if ch ==flag:return Falsereturn True
各个函数间的关系和流程图
各函数间关系

获取小标题
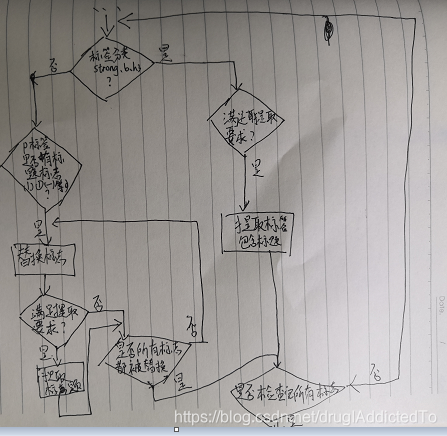
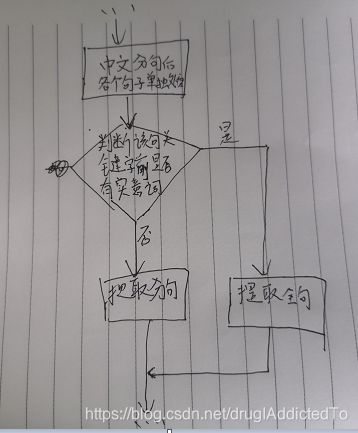
获取文本中诱因上下位
这篇关于Python爬取寻医问药网得到每个疾病的诱因和诱因上下位的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







