本文主要是介绍丢弃法(Dropout)——原理及代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、原理
1.1、动机
一个好的模型需要对输入数据的扰动具有鲁棒性
什么是一个“好”的预测模型?
我们期待“好”的预测模型能在未知的数据上有很好的表现:经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。
简单性以较小维度的形式展现,简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。
例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的。
1995年,克里斯托弗·毕晓普证明了具有输入噪声的训练等价于Tikhonov正则化(正则是使权重w不要太大,避免一定程度的过拟合的方法)。
这项工作用数学证实了“要求函数光滑”和“要求函数对输入的随机噪声具有适应性”之间的联系。
在2014年,斯里瓦斯塔瓦等人就如何将毕晓普的想法应用于网络的内部层提出了一个想法:
在训练过程中,他们建议在计算后续层之前向网络的每一层注入噪声。因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。
丢弃法(dropout)便由此而生
丢弃法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。这种方法之所以被称为丢弃法,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。在整个训练过程的每一次迭代中,标准丢弃法包括在计算下一层之前将当前层中的一些节点置零。即在层之间加入噪音。
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
1.2、无偏差的加入噪音
对 x 加入噪音得到 x',我们希望:
E(x') = x
注: E(x') 即对 x' 求期望
丢弃法做一个很简单的事情,它对每个元素进行如下扰动:

以概率 p 将原始数据元素变为 0,即丢弃数据;以概率 1-p 将原始数据元素变大
可以看到现在的期望就变成了 E(x') = 0*p + (1-p)*x' / (1-p) = x',并没有变化
1.3、使用丢弃法
通常将丢弃法作用在隐藏全连接层的输出上

说明:
h 为隐藏层
sigma 为激活函数
o 为输出
将 o 经过 softmax 层得到分类结果
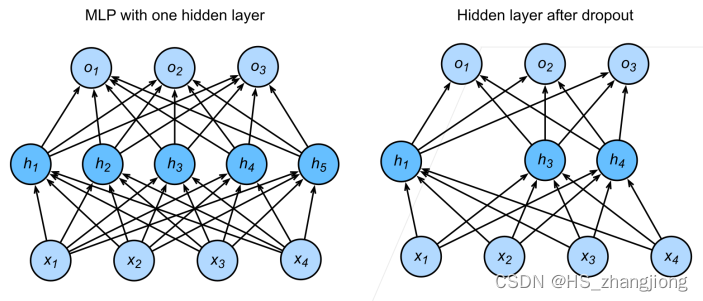
上图中左边为带有1个隐藏层和5个隐藏单元的多层感知机。当我们将丢弃法应用到隐藏层,以 p 的概率将隐藏单元置为零时,结果可以看作是一个只包含原始神经元子集的网络。
比如在上图右边中,删除了 h2 和 h5,因此输出的计算不再依赖于 h2 或 h5,并且它们各自的梯度在执行反向传播时也会消失。这样,输出层的计算不能过度依赖于 h1, ... , h5 的任何一个元素。
1.4、推理中的丢弃法(predict)
正则项只在训练中使用: 它们影响模型参数的更新
在推理过程中,丢弃法直接返回输入:
h = dropout(h)
这样能保证确定性的输出
二、代码实现
2.1、从零开始实现
这里实现 dropout_layer 函数,该函数以 dropout 的概率丢弃张量输入 X 中的元素,将剩余部分除以 1.0 - dropout
其中 概率 0 <= dropout <= 1
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return X# torch.rand() 生成 0~1 之间的随机均匀分布, mask 最终生成与 输入 X 同维度 且元素只有 0 或 1 的张量mask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)这里定义模型参数
使用 Fashion-MNIST 数据集。我们定义具有两个隐藏层的多层感知机,每个隐藏层包含 256 个单元。
num_inputs 为输入维度,数据集中的图片为 28 * 28 = 784,我们将每个图片转换为 784 * 1 的张量。num_outputs 为输出维度,Fashion-MNIST 数据集中的图片具有 10 个类别。
num_hiddens1, num_hiddens2 为每个隐藏层中的隐藏单元数,这里均为 256 个隐藏单元。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256这里我们定义模型
我们可以将 dropout 应用于每个隐藏层的输出(在激活函数之后),并且可以为每一层分别设置丢弃概率: 常见的技巧是在靠近输入层的地方设置较低的丢弃概率。
下面的模型将第一个和第二个隐藏层的丢弃概率分别设置为 0.2 和 0.5,并且丢弃法只在训练期间有效(is_training = True)。
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)这里我们进行训练和测试,这类似于多层感知机训练和测试。
其中:
num_epochs 为迭代次数
lr 为学习率
batch_size 为批量大小,每次随机从数据集中取 batch_size 大小的数据,直到取完
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
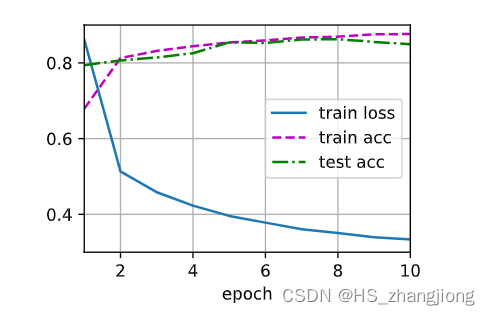
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)结果:
2.2、简洁实现
这里我们进行简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个 Dropout 层,将丢弃概率作为唯一的参数传递给它的构造函数。在训练时,Dropout 层将根据指定的丢弃概率随机丢弃上一层的输出(相当于下一层的输入)。在测试时,Dropout 层仅传递数据。
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);接下来,我们对模型进行训练和测试。
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)结果:

三、总结
丢弃法将一些输出项随机置 0 来控制模型复杂度;
丢弃法常作用在多层感知机的隐藏层输出上;
丢弃概率是控制模型复杂度的超参数,人为设置。
这篇关于丢弃法(Dropout)——原理及代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





