本文主要是介绍姓CNN还是姓Transformer? 关键是“有效”学到“大”模型!基础打好,赢者通吃!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注公众号,发现CV技术之美
本文转载自机器之心。
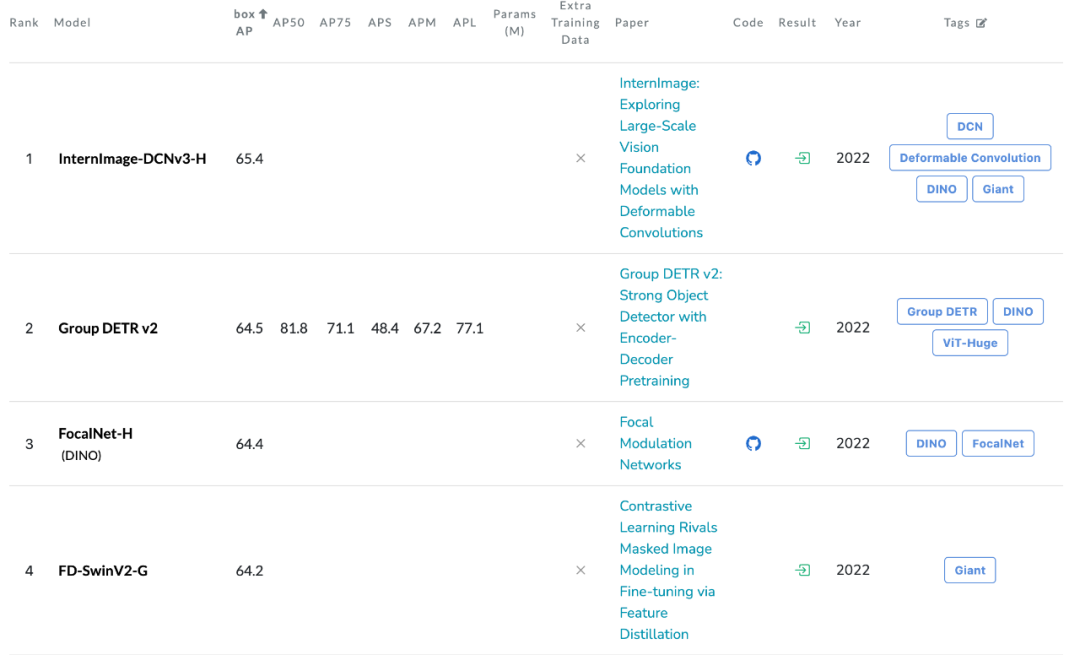
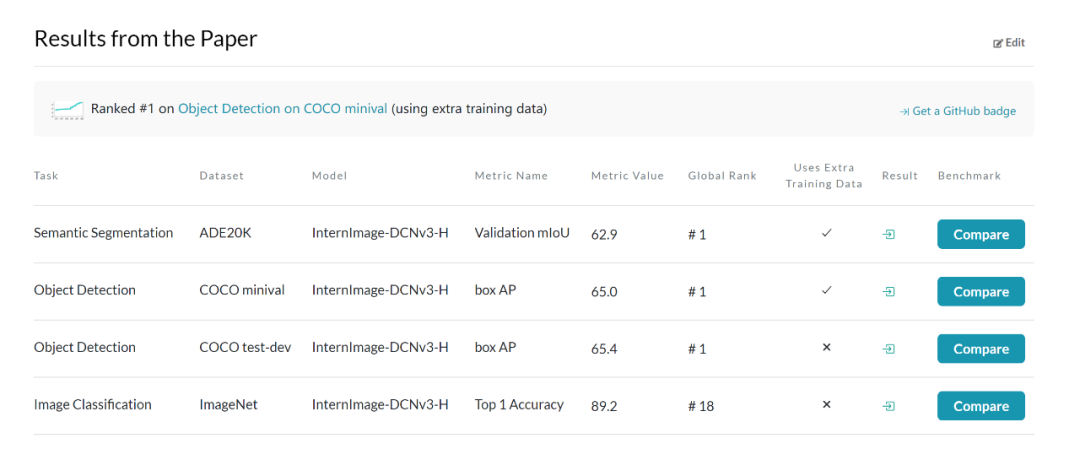
来自浦江实验室、清华等机构的研究人员提出了一种新的基于卷积的基础模型,称为 InternImage,与基于 Transformer 的网络不同,InternImage 以可变形卷积作为核心算子,使模型不仅具有检测和分割等下游任务所需的动态有效感受野,而且能够进行以输入信息和任务为条件的自适应空间聚合。InternImage-H 在 COCO 物体检测上达到 65.4 mAP,ADE20K 达到 62.9,刷新检测分割新纪录。
近年来大规模视觉 Transformer 的蓬勃发展推动了计算机视觉领域的性能边界。视觉 Transformer 模型通过扩大模型参数量和训练数据从而击败了卷积神经网络。来自上海人工智能实验室、清华、南大、商汤和港中文的研究人员总结了卷积神经网络和视觉 Transformer 之间的差距。从算子层面看,传统的 CNNs 算子缺乏长距离依赖和自适应空间聚合能力;从结构层面看,传统 CNNs 结构缺乏先进组件。
针对上述技术问题,来自浦江实验室、清华等机构的研究人员创新地提出了一个基于卷积神经网络的大规模模型,称为 InternImage,它将稀疏动态卷积作为核心算子,通过输入相关的信息为条件实现自适应空间聚合。
InternImage 通过减少传统 CNN 的严格归纳偏置实现了从海量数据中学习到更强大、更稳健的大规模参数模式。其有效性在包括图像分类、目标检测和语义分割等视觉任务上得到了验证。并在 ImageNet、COCO 和 ADE20K 在内的挑战性基准数据集中取得了具有竞争力的效果,在同参数量水平的情况下,超过了视觉 Transformer 结构,为图像大模型提供了新的方向。

论文链接:https://arxiv.org/abs/2211.05778
开源代码:https://github.com/OpenGVLab/InternImage
传统卷积神经网络的局限
扩大模型的规模是提高特征表示质量的重要策略,在计算机视觉领域,模型参数量的扩大不仅能够有效加强深度模型的表征学习能力,而且能够实现从海量数据中进行学习和知识获取。
ViT 和 Swin Transformer 首次将深度模型扩大到 20 亿和 30 亿参数级别,其单模型在 ImageNet 数据集的分类准确率也都突破了 90%,远超传统 CNN 网络和小规模模型,突破了技术瓶颈。但是,传统的 CNN 模型由于缺乏长距离依赖和空间关系建模能力,无法实现同 Transformer 结构相似的模型规模扩展能力。研究者总结了传统卷积神经网络与视觉 Transformer 的不同之处:
(1)从算子层面来看,视觉 Transformer 的多头注意力机制具有长距离依赖和自适应空间聚合能力,受益于此,视觉 Transformer 可以从海量数据中学到比 CNN 网络更加强大和鲁棒的表征。
(2)从模型架构层面来看,除了多头注意力机制,视觉 Transformer 拥有 CNN 网络不具有的更加先进的模块,例如 Layer Normalization (LN), 前馈神经网络 FFN, GELU 等。
尽管最近的一些工作尝试使用大核卷积来获取长距离依赖,但是在模型尺度和精度方面都与最先进的视觉 Transformer 有着一定距离。
可变形卷积网络的进一步拓展
InternImage 通过重新设计算子和模型结构提升了卷积模型的可扩展性并且缓解了归纳偏置,包括(1)DCNv3 算子,基于 DCNv2 算子引入共享投射权重、多组机制和采样点调制。(2)基础模块,融合先进模块作为模型构建的基本模块单元(3)模块堆叠规则,扩展模型时规范化模型的宽度、深度、组数等超参数。
该工作致力于构建一个能够有效地扩展到大规模参数的 CNN 模型。首先,重新设计的可变形卷积算子 DCNv2 以适应长距离依赖和弱化归纳偏置;然后,将调整后的卷积算子与先进组件相结合,建立了基础单元模块;最后,探索并实现模块的堆叠和缩放规则,以建立一个具有大规模参数的基础模型,并且可以从海量数据中学习到强大的表征。
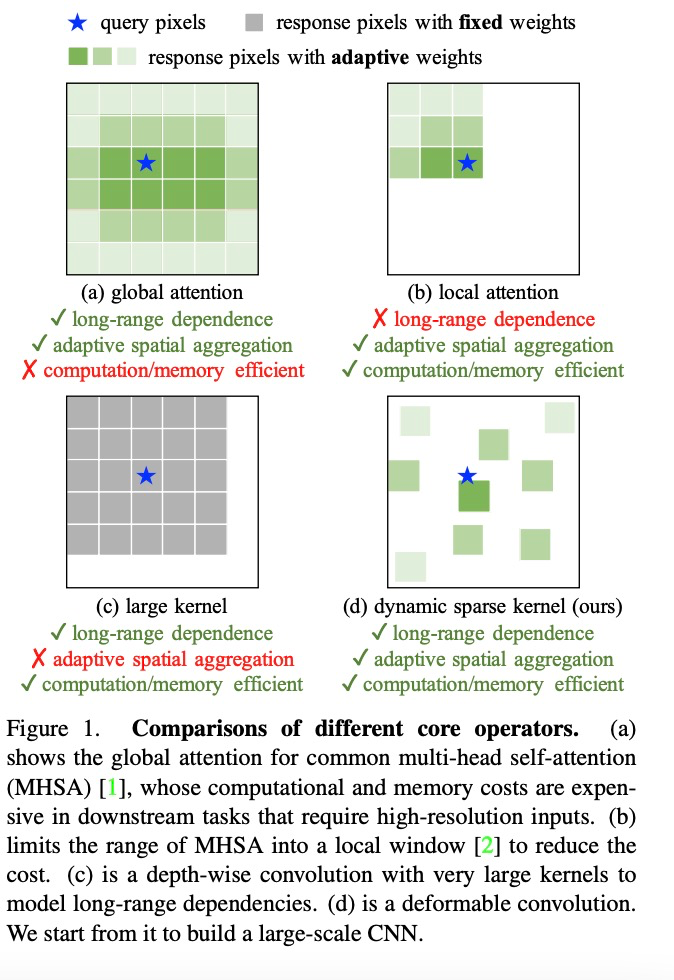
算子层面,该研究首先总结了卷积算子与其他主流算子的主要区别。当前主流的 Transformer 系列模型主要依靠多头自注意力机制实现大模型构建,其算子具有长距离依赖性,足以构建远距离特征间的连接关系,还具有空间的自适应聚合能力以实现构建像素级别的关系。但这种全局的注意力机制其计算和存储需求量巨大,很难实现高效训练和快速收敛。同样的,局部注意力机制缺乏远距离特征依赖。大核密集卷积由于没有空间聚合能力,而难以克服卷积天然的归纳偏置,不利于扩大模型。因此,InternImage 通过设计动态稀疏卷积算子,达到实现全局注意力效果的同时不过多浪费计算和存储资源,实现高效训练。
研究者基于 DCNv2 算子,重新设计调整并提出 DCNv3 算子,具体改进包括以下几个部分。
(1)共享投射权重。与常规卷积类似,DCNv2 中的不同采样点具有独立的投射权重,因此其参数大小与采样点总数呈线性关系。为了降低参数和内存复杂度,借鉴可分离卷积的思路,采用与位置无关的权重代替分组权重,在不同采样点之间共享投影权重,所有采样位置依赖性都得以保留。
(2)引入多组机制。多组设计最早是在分组卷积中引入的,并在 Transformer 的多头自注意力中广泛使用,它可以与自适应空间聚合配合,有效地提高特征的多样性。受此启发,研究者将空间聚合过程分成若干组,每个组都有独立的采样偏移量。自此,单个 DCNv3 层的不同组拥有不同的空间聚合模式,从而产生丰富的特征多样性。
(3)采样点调制标量归一化。为了缓解模型容量扩大时的不稳定问题,研究者将归一化模式设定为逐采样点的 Softmax 归一化,这不仅使大规模模型的训练过程更加稳定,而且还构建了所有采样点的连接关系。
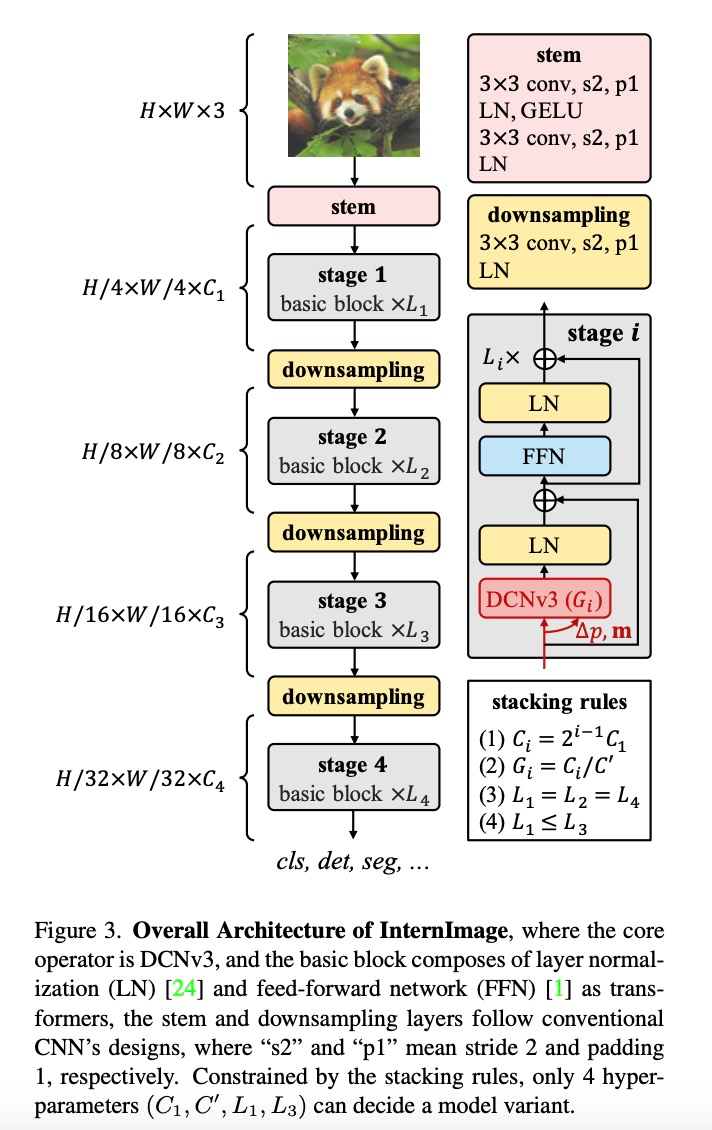
构建 DCNv3 算子之后,接下来首先需要规范化模型的基础模块和其他层的整体细节,然后通过探索这些基础模块的堆叠策略,构建 InternImage。最后,根据所提出模型的扩展规则,构建不同参数量的模型。
基础模块。与传统 CNN 中广泛使用的瓶颈结构不同,该研究采用了更接近 ViTs 的基础模块,配备了更先进的组件,包括 GELU、层归一化(LN)和前馈网络(FFN),这些都被证明在各种视觉任务中更有效率。基础模块的细节如上图所示,其中核心算子是 DCNv3,通过将输入特征通过一个轻量级的可分离卷积来预测采样偏置和调制尺度。对于其他组件,遵循与普通 Transformer 相同的设计。
叠加规则。为了明确区块堆叠过程,该研究提出两条模块堆叠规则,其中第一条规则是后三个阶段的通道数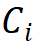 ,由第一阶段的通道数
,由第一阶段的通道数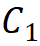 决定,即
决定,即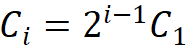 ;第二条规则是各模块组号与各阶段的通道数对应,即
;第二条规则是各模块组号与各阶段的通道数对应,即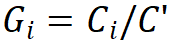 ;第三,堆叠模式固定为 “AABA”,即第 1、2 和 4 阶段的模块堆叠数是相同的
;第三,堆叠模式固定为 “AABA”,即第 1、2 和 4 阶段的模块堆叠数是相同的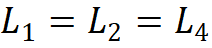 ,并且不大于第 3 阶段
,并且不大于第 3 阶段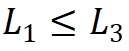 。由此选择将参数量为 30M 级别的模型作为基础,其具体参数为:Steam 输出通道数
。由此选择将参数量为 30M 级别的模型作为基础,其具体参数为:Steam 输出通道数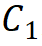 为 64;分组数为每个阶段输入通道数的 1/16,第 1、2、4 阶段的模块堆叠数
为 64;分组数为每个阶段输入通道数的 1/16,第 1、2、4 阶段的模块堆叠数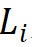 为 4,第 3 阶段的模块堆叠数
为 4,第 3 阶段的模块堆叠数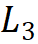 为 18,模型参数为 30M。
为 18,模型参数为 30M。
模型缩放规则。基于上述约束条件下的最优模型,该研究规范化了网络模型的两个缩放维度:即深度 D(模块堆叠数)和宽度 C(通道数),利用限制因子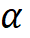 和
和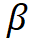 沿着复合系数
沿着复合系数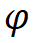 对深度和宽度进行缩放,即,
对深度和宽度进行缩放,即,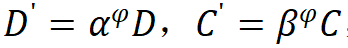 ,其中
,其中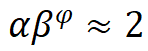 ,根据实验其最佳设置为
,根据实验其最佳设置为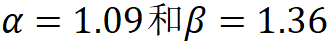 。
。
按照此规则,该研究构建了不同尺度的模型,即 InternImage-T、S、B、L、XL。具体参数为:

实验结果
图像分类实验:通过使用 427M 的公共数据集合:Laion-400M,YFCC15M,CC12M,InternImage-H 在 ImageNet-1K 的精度达到了 89.2%。
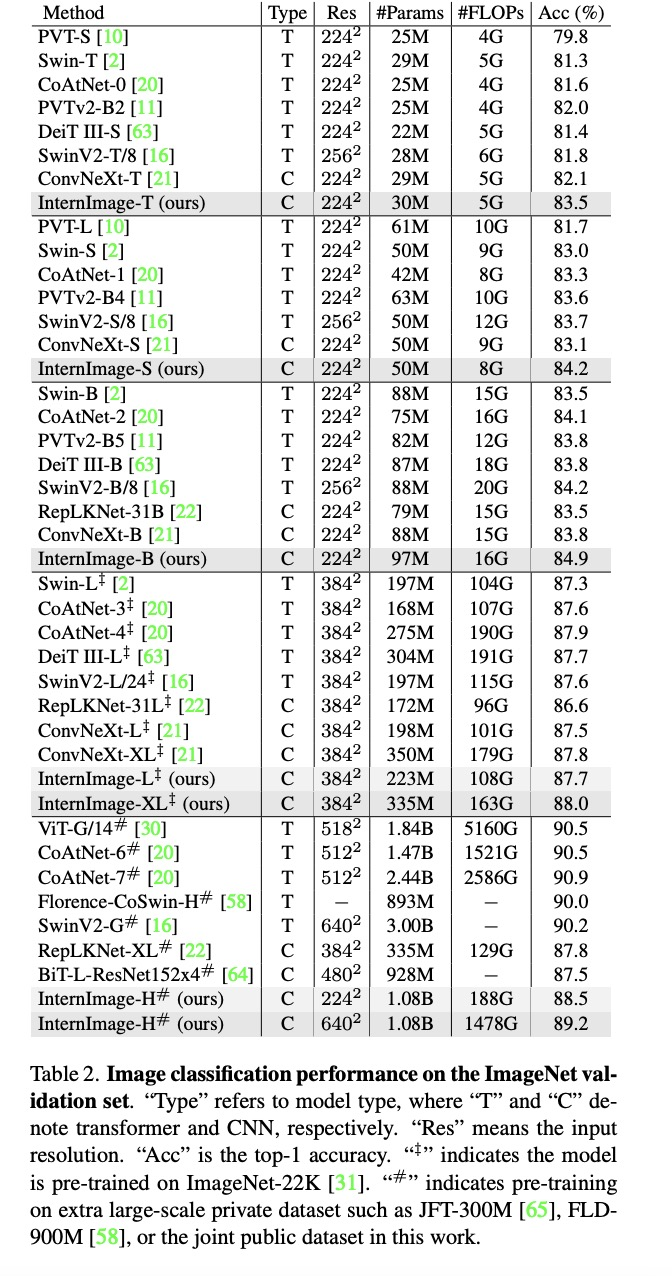
目标检测:以最大规模的 InternImage-H 为骨干网络,并使用 DINO 作为基础检测框架,在 Objects365 数据集上预训练 DINO 检测器,然后在 COCO 上进行微调。该模型在目标检测任务中达到了 65.4% 的最优结果,突破了 COCO 目标检测的性能边界。
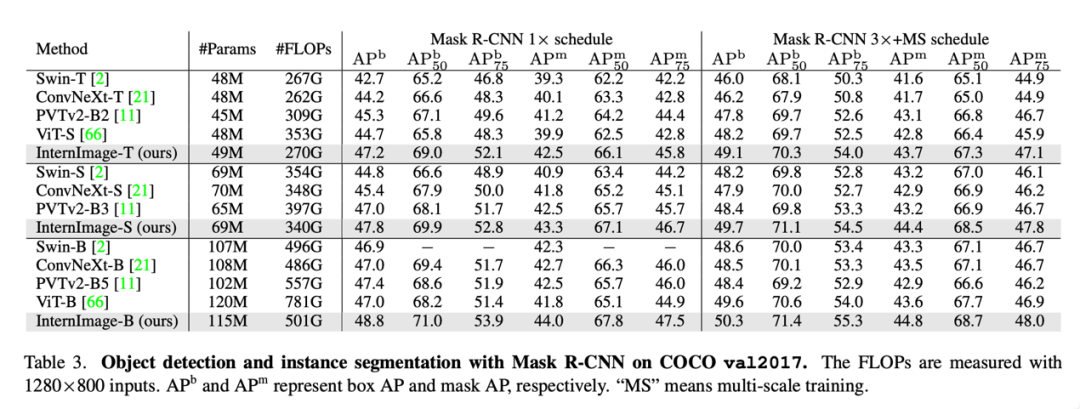
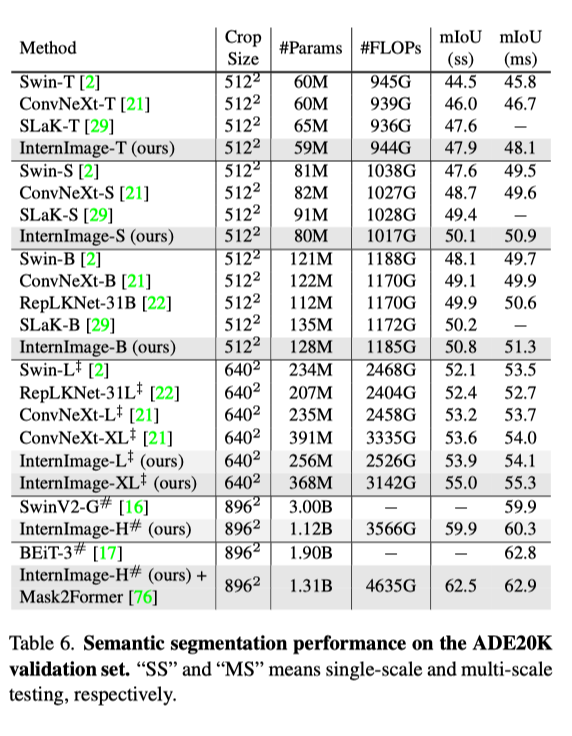
语义分割:在语义分割上,InternImage-H 同样取得了很好的性能,结合 Mask2Former 在 ADE20K 上取得了当前最高的 62.9%。
结论
该研究提出了 InternImage,这是一种新的基于 CNN 的大规模基础模型,可以为图像分类、对象检测和语义分割等多功能视觉任务提供强大的表示。研究者调整灵活的 DCNv2 算子以满足基础模型的需求,并以核心算子为核心开发了一系列的 block、stacking 和 scaling 规则。目标检测和语义分割基准的大量实验验证了 InternImage 可以获得与经过大量数据训练、且精心设计的大规模视觉 Transformer 相当或更好的性能,这表明 CNN 也是大规模视觉基础模型研究的一个相当大的选择。尽管如此,大规模的 CNN 仍处于早期发展阶段,研究人员希望 InternImage 可以作为一个很好的起点。

END
欢迎加入「目标检测」交流群👇备注:OD

这篇关于姓CNN还是姓Transformer? 关键是“有效”学到“大”模型!基础打好,赢者通吃!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



