本文主要是介绍X32位汇编和X64位区别无参函数分析(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
一、X32汇编函数无参无返回分析
二、X64汇编函数无参无返回分析
总结
前言
提示:以下是个人学习总结:如有错误请大神指出来,只供学习参考,本内容使用使用VS2017开发工具:语言是C++,需要一些常见的汇编指令,寄存器的概念,不会的可以看下其他的博主的,我用的这里方便学习全程debug,函数用的默认C++cdecl调用约定模式(可以网上查下调用约定,右边入参到左边,称为外平栈)。
好久没更新博客了,准备把汇编自我总结复习的顺带把过程记录下来,接下来开始吧,准备简单的无参函数。
一、X32汇编函数无参无返回分析
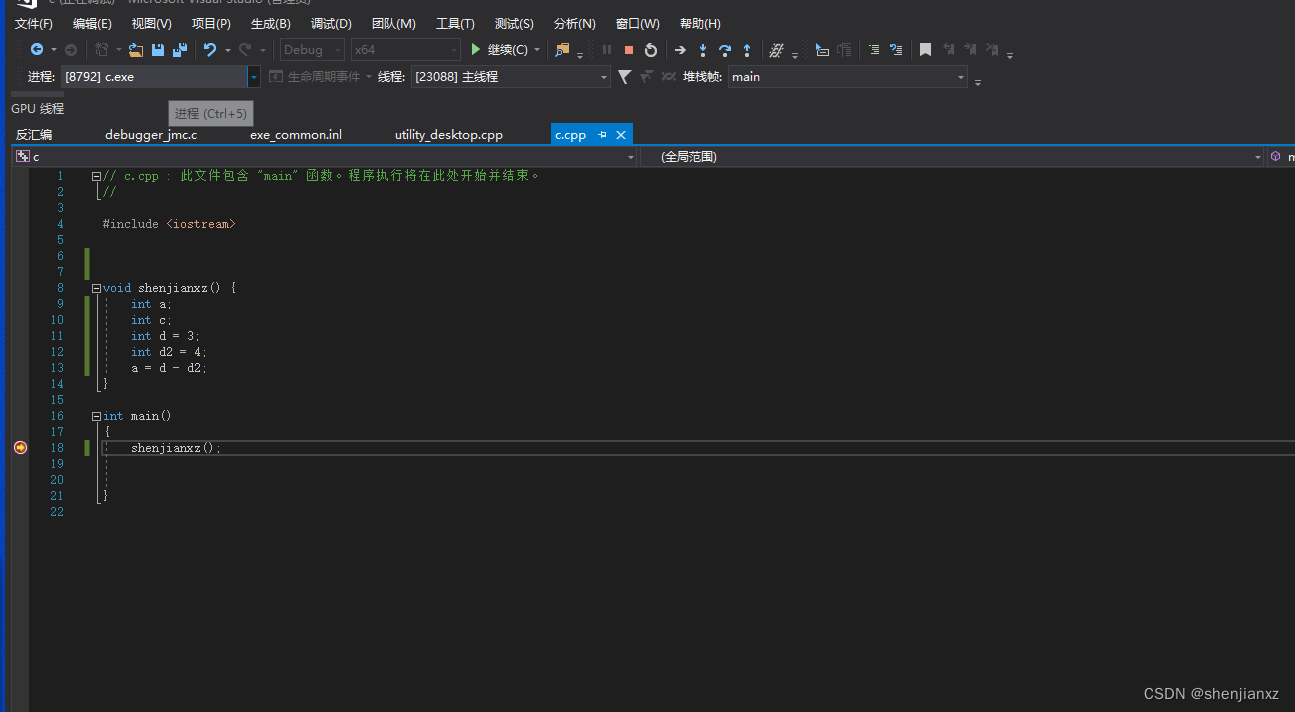
1.代码图片(示例):
不知道为什么不能赋值图这里直接赋值代码了。 #include <iostream>void shenjianxz() {int a;int c;int d = 3;int d2 = 4;a = d - d2; }int main() {shenjianxz();}
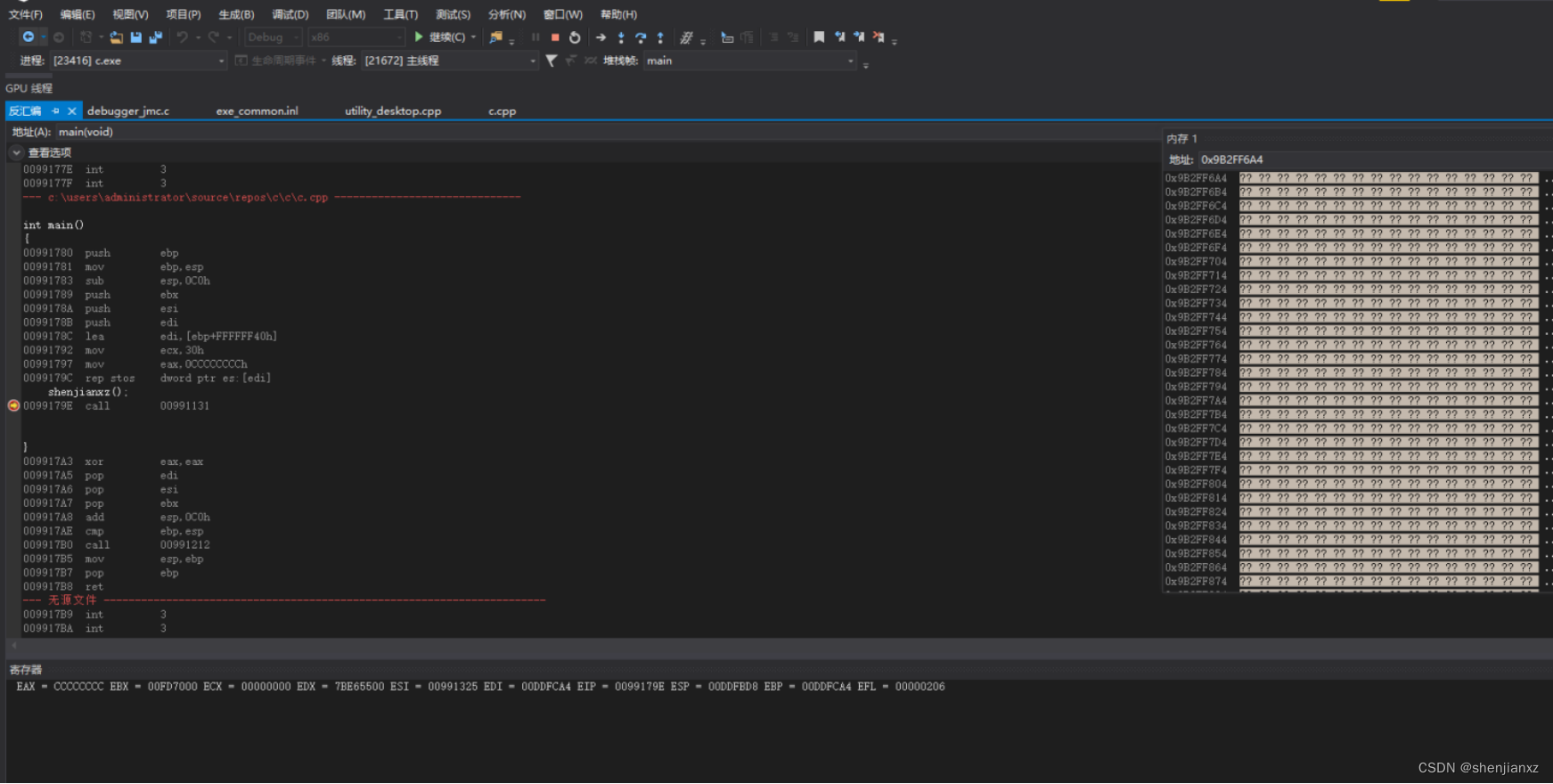
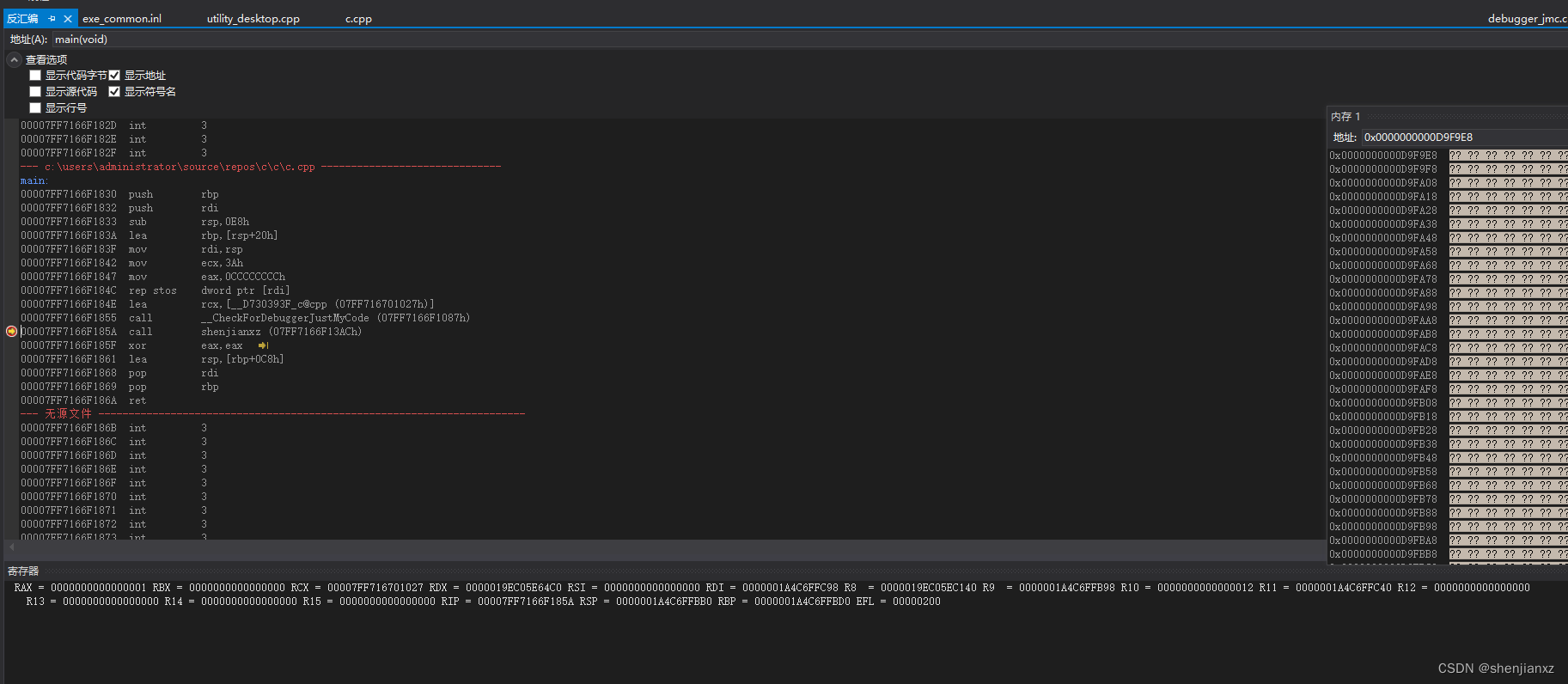
0099179E call 00991131 这个就是上面那个简单shenjianxz()函数调用,
CPU主要执行的是根据EIP执行跳转的,
call指令会 push 009917A3 压栈 :因为我们调用完函数返回的时候会取这个地址,跳转到下一行执行的代码, EIP寄存器=00991131
现在我们跳去看看按F11
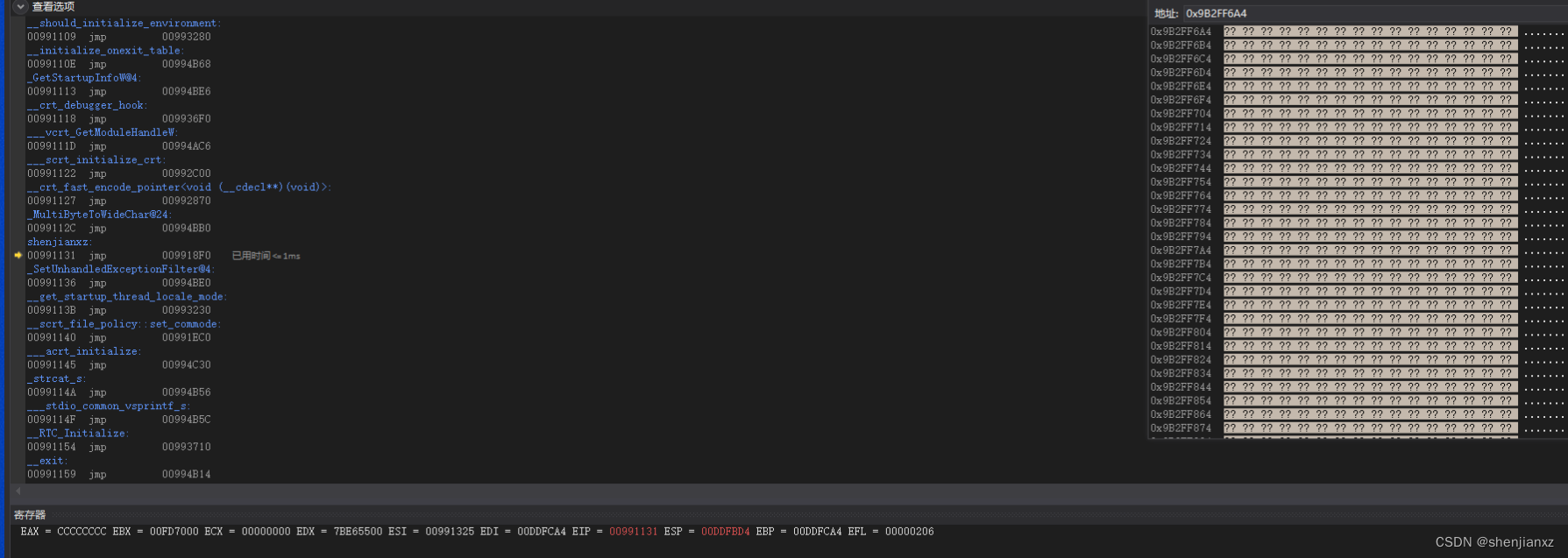
这里 jmp 中间跳转程序空间保存的函数地址 00EA1750,咱们先不管,这不是重点
简单解下:jmp 只改变eip地址,cpu会自动运行到执行的地址去,在点下F11进入 调用函数代码区了。
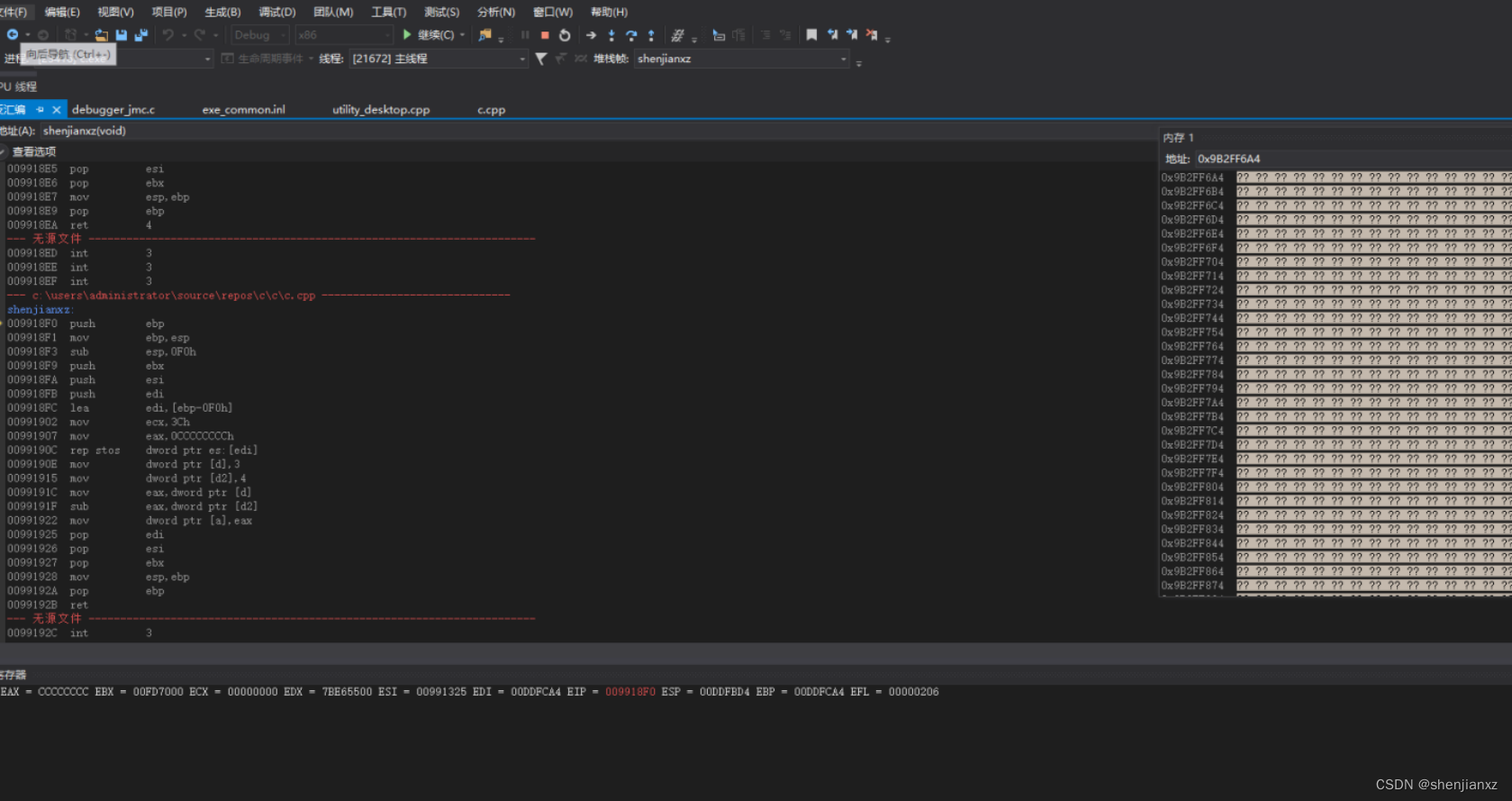
重点关注下:ESP寄存器到哪了,EBP寄存器值等于多少。
我讲解下上面代码含义:
shenjianxz
009918F0 push ebp
保留ebp 寄存器
009918F1 mov ebp,esp
为了后面恢复esp栈顶位置把他赋值给ebp进行操作
009918F3 sub esp,0F0h
因为前面已经保存了esp的赋值,就不担心这里esp就开始扩展0F0h 位置esp位置肯定就变了
009918F9 push ebx
009918FA push esi
009918FB push edi
保留 ebx,esi,edi 寄存器位置
009918FC lea edi,[ebp-0F0h]
这里ebp的作用就体现了,最前面我们不是把esp赋值给了ebp吗,
这里就代表把sub esp,0F0h 地址赋值给edl
00991902 mov ecx,3Ch 3c次数
00991907 mov eax,0CCCCCCCCh
0099190C rep stos dword ptr es:[edi]
重复3c次把occccccch=int 3先不用管,就理解是ccccccc赋值给edi 每次成功赋值就 edi+4
0099190E mov dword ptr [ebp-20h],3
00991915 mov dword ptr [ebp-2Ch],4
0099191C mov eax,dword ptr [ebp-20h]
0099191F sub eax,dword ptr [ebp-2Ch]
ebp的位置是push ebp的位置,之后不是 ebp=esb 下一句不是 sub esp,0F0h 扩展了0f0的大小空间么
那么ebp-20,-2c都是在扩展的位置区间,可见X32是ebp-N代表取局部变量
00991922 mov dword ptr [ebp-8],eax
最终把结果放到ebp-8内存中
00991925 pop edi
00991926 pop esi
00991927 pop ebx
因为esp一直在栈顶所以还原3个寄存器 esp-Ch位置
00991928 mov esp,ebp
esp已经距离很远了,因为扩展了0F0h大小字节,所以用ebp恢复esp位置esp在 push ebp位置了
0099192A pop ebp
恢复ebp栈底
0099192B ret
之前我们用call 调用的函数,这里面push的是 call的下一条代码地址=pop eip 让cpu跳转到eip位置,下面是对应的自己画的图:

2.小结:
1:X32是先保留push ebp寄存器,在扩展堆栈大小
2:mov ebp,esp 保留栈顶位置,方便后面恢复
3:[ebp-20],[ebp-2c]都是在扩展的位置区间,可见X32是ebp-N代表取局部变量,参数获取(这里演示无参数)
二、X64汇编函数无参无返回分析
1.代码图片(示例)
同样的代码看不同:
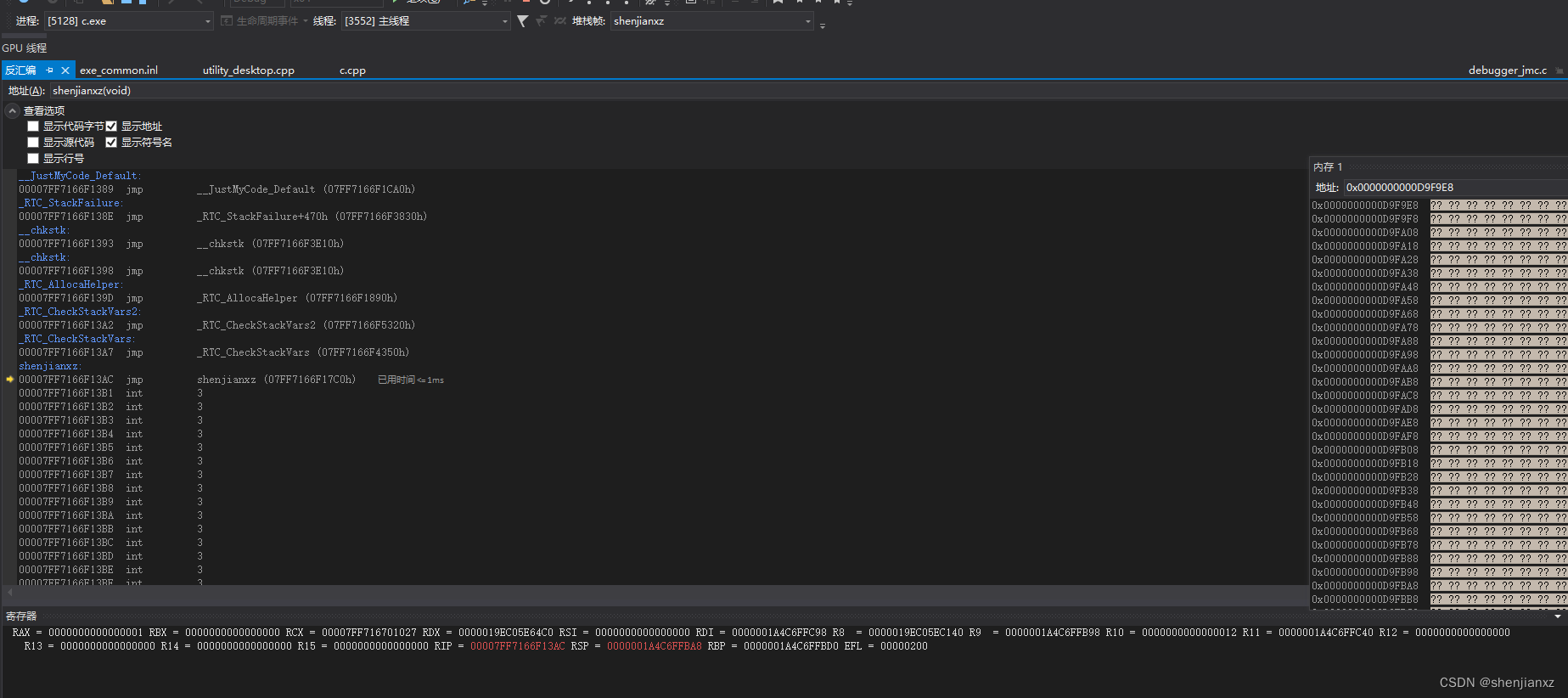
前面讲过,这里也是jmp方式跳转到函数代码快,继续F11跟进去,因为中间重启过地址发生变化,直接看下面的函数内容就行
00007FF7CA1717C0 push rbp
00007FF7CA1717C2 push rdi
00007FF7CA1717C3 sub rsp,168h
00007FF7CA1717CA lea rbp,[rsp+20h]
00007FF7CA1717CF mov rdi,rsp
00007FF7CA1717D2 mov ecx,5Ah
00007FF7CA1717D7 mov eax,0CCCCCCCCh
00007FF7CA1717DC rep stos dword ptr [rdi]
这里是重复ecx的次数填充栈顶开始往回每次 rdi+4
00007FF7CA1717DE lea rcx,[__D730393F_c@cpp (07FF7CA181027h)]
00007FF7CA1717E5 call __CheckForDebuggerJustMyCode (07FF7CA171087h)
这2行 因为是debug模式是检测堆栈的直接跳过看下面的
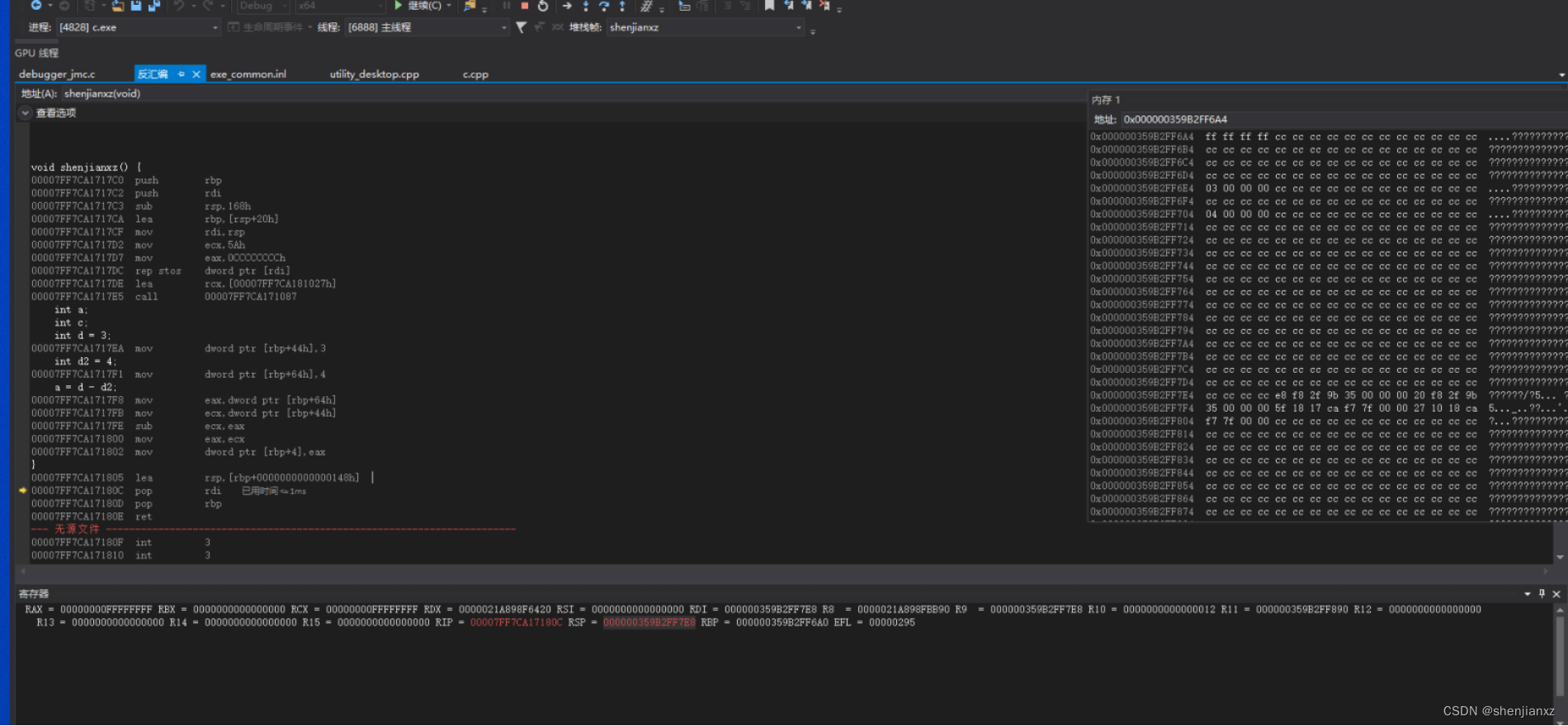
00007FF7CA1717EA mov dword ptr [rbp+44h],3
00007FF7CA1717F1 mov dword ptr [rbp+64h],4
RBP+N 代表局部变量,在X32中是EBP-N代表局部变量,那么这里就是把立即数赋值给局部变量
我的理解因为之前 扩展168h,rsp,168h
这里局部变量不能>rbp+148h大小范围,因为rsp+20了之前,大于了下一条就到了push rdi的位置了
00007FF7CA1717F8 mov eax,dword ptr [rbp+64h]
00007FF7CA1717FB mov ecx,dword ptr [rbp+44h]
看这里rbp+64 ,+44都是在扩展的局部变量赋值,在范围内
00007FF7CA1717FE sub ecx,eax
00007FF7CA171800 mov eax,ecx
00007FF7CA171802 mov dword ptr [rbp+4],eax
最后把值赋值给局部变量rbp+4
00007FF7CA171805 lea rsp,[rbp+0000000000000148h]
之前rsp-168h,然后rbp+20 这里在加个148h 不就回去了最早的push RDI位置
00007FF7CA17180C pop rdi
00007FF7CA17180D pop rbp
这里就是恢复 RDI RBP里的值
00007FF7CA17180E ret 这里pop eip 让cpu跳转到调用程序下一条指令执行
三、X32位汇编和X64位区别无参函数调用
总结
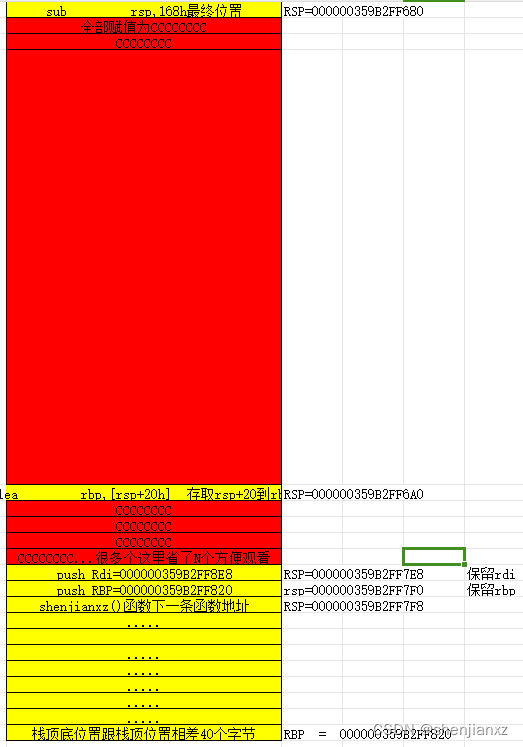
提示:可以看下对比堆栈图变化和我说的文字区别
X32:
1:X32是先保留push ebp寄存器,在扩展堆栈大小
2:mov ebp,esp 保留栈顶位置,方便后面恢复
3:[ebp-20],[ebp-2c]都是在扩展的位置区间,可见X32是ebp-N代表取局部变量,参数获取(这里演示无参数)

X64:
1:X64是先扩展栈顶大小,在进行保留寄存器
2:EBP+N是获取局部变量
3:EBP+20=ESP+20,后用EBP进行局部变量赋值,参数获取(这里演示无参数)

这篇关于X32位汇编和X64位区别无参函数分析(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






