本文主要是介绍测试造假数据的库 Faker 随机生成名字的能力如何,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看到某公众号有一篇文章:Python中神奇的第三方库:Faker
Faker 项目地址
文章大致介绍了一下 Faker 这个库的功能和用法。我对其中随机生成名字的功能比较感兴趣,想看看随着生成的数据逐渐变多,随机生成的名字会不会出现重复,以及重复的概率有多大。
测试过程如下:
- 每次随机生成的数目 m 的范围和步长分别是 [100, 10000]、100;
- 每次数据生成后求每条名字的重复的次数 n;
- 概率取 n/m;
- 重复步骤 1、2、3、4 十次;
- 取十次概率的均值并画出变化趋势
代码如下:
from faker import Faker
import math
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter#epoch:运行次数,int 类型
#ite:一次生成的名字数量,int 类型
#sta:是否每次显示统计信息, bool 类型,默认为 False
#函数返回 这一批名字的重复概率(所有可用名字的数量除以 ite),int 类型
def gen_names(epoch, ite, sta=False):fake = Faker(locale='zh_CN')total = 0names = {} #存放名字及其数量的字典for r in range(epoch):for i in range(ite):if (i + r * ite + 1)%(int(epoch * ite / 10)) == 0: #每10%输出一次进度if sta:print(str(round((i + r * ite + 1)/(epoch * ite) * 100)) + '%')name = fake.name()if name in names:names[name] = names[name] + 1 #累加名字重复的次数else:names[name] = 0 #如果是新名字则保存,初始数量为 0repeats = 0for key in names:repeats = repeats + names[key] #累加所有名字的重复次数if sta:print('{} iterations {} names each time'.format(epoch,ite))print('%d names' % len(names))print('%d repeats' % repeats)print('duplicate rate: %.5f' % (epoch * ite)))return round(repeats/(epoch * ite), 4)array = np.zeros((10,100)) #用来绘图的数组,10 次实验每次 100 个数据for i in range(10):print('{}/10'.format(i+1)) #展示进度 需要数几分钟list_ = [] #暂存每次统计的数据for j in range(100,10100,100):list_.append(gen_names(1, j))array[i] = list_data = np.mean(array, axis = 0) #求十次的均值def changex(temp, position): #x轴原来是 1-100,扩大 100 倍来符合实际意义return int(temp * 100)
plt.gca().xaxis.set_major_formatter(FuncFormatter(changex)) #扩展x轴
plt.plot(data.tolist(),color='g') #绘制趋势,横坐标为一次生成的名字数量,纵坐标为所有名字重复的概率
plt.savefig('./test.png', format='png') #保存图片
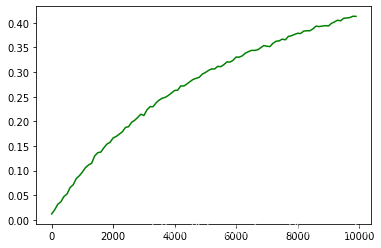
举个例子:
(10000, 0.4)这个点代表的意思是,用 Faker 库一次随机生成 10000 个名字,有 40% 的名字是重复的
综上:
- 这个库随机生成名字的数量比较大的时候,重复的概率还是很高的
- 地址生成的真实度也比较低,但是用来测试应该够用了
这篇关于测试造假数据的库 Faker 随机生成名字的能力如何的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



