本文主要是介绍Janus: 逆向思维,以数据为中心的MoE训练范式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章链接:Janus: A Unified Distributed Training Framework for Sparse Mixture-of-Experts Models
发表会议: ACM SIGCOMM 2023 (计算机网络顶会)
目录
- 1.背景介绍
- all-to-all
- Data-centric Paradigm
- 2.内容摘要
- 关键技术
- Janus
- 细粒度任务调度
- 拓扑感知优先级策略
- 预取测略
- 实验结果
- End-to-End Performance
- Ablation Study
- Janus中Data-centric和Expert-centric的统一
- 3.文章总结
1.背景介绍
稀疏激活的MoE是一种很有前途的模型扩展架构,但由于层与层之间的的
all-to-all通信,训练MoE模型的成本是十分昂贵的。常见的all-to-all通信都以专家为中心范式,通过将专家保留在合适的位置,并交换中间数据以满足专家的需求。
那么如果调换一下专家和数据的位置关系,会有什么神奇的现象发生呢?
基于这个猜想,诞生了Janus:以数据为中心范式——保持数据在适当的位置,并在gpu之间移动专家。这个猜想的合理处在于,如果专家的规模小于数据规模,那么以数据为中心的范式可以减少交流的工作量。
all-to-all

训练一个大型的稀疏MoE模型并非易事。随着专家数量的增加,模型最终将超过单个GPU的内存限制。为了训练大型MoE模型,提出了专家并行性。
如图上图所示,MoE模型块中的专家层被分割并放置在多个gpu上。因此,在模型计算过程中,必须在专家层之前和之后添加all -to- all通信,以便在所有gpu之间交换中间结果,all -to- all原语是一种同步集体通信,这意味着延迟由需要发送和的最繁忙的工作者决定。all -to- all的操作是昂贵的,成为MoE模型训练的主要瓶颈。

上图报告了在4台8A100GPU,每个MoE块有32个专家的训练时间成本,以及在两台8A100 GPU,每个MoE块有16位专家的训练时间成本。在一次迭代中,由all -to- all通信引起的平均延迟占整个迭代时间的38.5% - 68.4%。
Data-centric Paradigm

鉴于在模型训练过程中all-to-all的交流是非常耗时的,后退一步,重新思考在MoE模型训练过程中必不可少的通信交流。现有的训练系统保持专家到位,并交换中间数据以满足专家的需求。我们将这种模式称为Expert-centric Paradigm,如图 a 所示,在这种模式中,专家被静态地放置,而中间数据被移动。
相反,还可以保持中间数据的静态,并在gpu之间移动专家,如图2所示。将此范式命名为Data-centric Paradigm,这是实现训练MoE模型所需通信的一种新颖而等价的方法。通过比较现有的专家中心范式和新提出的数据中心范式,我们发现后者在减少交流工作量方面具有优势。
在一定条件下,Data-centric Paradigm规模可能比Expert-centric Paradigm的方式小得多。当模型尺寸比较小,而输入数据量比较大(比如batch比较大)时,这种差距可以扩大。由于每个专家的规模相同,员工之间的沟通工作量也变得平衡。此外,以数据为中心的范例可能会带来两个机会:
- 与
Expert-centric Paradigm不同,其All-to-All通信是严格阻塞的(同步的),Data-centric Paradigm在GPU之间移动专家可以使用非阻塞的(或异步的)通信原语(如pull和push)来实现。这进一步提高了性能,可重用性提供了减少跨机器流量的机会。 - 其次,由于专家权重在模型训练的迭代过程中是确定的,因此可以预取专家,并且它允许我们进一步改善计算和通信之间的重叠。预取技术不适用于以专家为中心的范例,因为中间数据只能在运行中填充。
2.内容摘要
Janus支持细粒度异步通信,它可以重叠计算和通信。Janus实现了分层通信,通过共享同一台机器中获取的专家来进一步减少跨节点通信。其次,在调度“抓取专家”请求时,Janus实现了一种拓扑感知的优先级策略,以有效地利用节点内和节点间的链接。最后,Janus允许预取专家,这允许下游计算在前一步完成后立即开始。
本文还整合了两种MoE训练范式,设计了Janus2,这是一种通信最优的混合专家模型训练系统。
关键技术
Janus

上图显示了Janus的体系结构。
-
Worker 仍然负责执行模型计算。在对MoE模型进行训练时,这些专家被分成几个部分,分配给工人。每个工作人员负责存储专家的权重,并在每次迭代中更新它们。
-
当计算到达一个MoE块的 Gate 时,如果传输专家的通信大小大于中间数据。Janus将采用
Expert-centric Paradigm,并调用All-to-All原语。否则,Janus将采用Data-centric Paradigm,工作人员将获取专家的请求放入Janus Task Queue中,等待专家模块。 -
获取专家后,Worker 可以对专家模块进行计算。在迭代结束时,Worker 生成专家的梯度,他们需要请求Janus Task Queue将梯度发送回这些专家的原始 Worker ,以更新模型的权重。
-
每台机器都有一个Janus Task Queue,它包括一个节点间调度器和几个节点内调度器(每个Worker 一个)。
-
每个节点内调度器(Intra-node Scheduler)连接到一个Worker (即GPU),位于GPU的内存中,负责接收相应Worker 的请求,并为Worker 获取专家。它有一个名为Credit-based buffer的组件来管理缓冲区空间,以节省提取的专家。
-
节点间调度器(Inter-node Scheduler)位于机器的CPU内存中,负责在收到来自本地机器的节点内调度器的请求时从其他机器获取专家。除了通信功能之外,它还有一个名为Cache Manager的组件,用于缓存从其他机器获取的专家。
-
如果所请求的专家已预先分配给本地机器,则节点内调度程序从拥有专家的工人中提取专家。否则,节点内调度器会将请求传递给本机器的节点间调度器,并等待节点间调度器返回专家。节点间调度器将返回来自Cache Manager的专家模块或来自其他机器的请求。
受Data-centric Paradigm提供的机会的启发,Janus从三个角度提高了Data-centric Paradigm的系统效率。
- Janus将获取每个专家的请求视为一个单独的任务,而不是批量发送专家请求。这样,Janus就实现了异步通信,即一个worker可以在接收另一个专家的同时执行一个专家的计算,这意味着部分通信时间可以被专家的计算时间所隐藏。
- 可以使Janus实现分层抓取操作,即可以合并同一台机器上工人对同一专家的请求,从而进一步减少跨节点流量。其次,为了缓解瓶颈的带宽争用,Janus设计了一种拓扑感知的优先级策略,精心安排抓取专家请求的优先级。
- Janus利用空闲时隙的带宽预取专家,使得前一层的计算完成后,可以立即开始专家层的计算。
细粒度任务调度

在Janus中,每个worker通常需要在expert层中拉出所有专家,以完成其在该层上的令牌的计算。然而,在计算开始之前,将所有专家同时拉出是不必要的,也是不可行的。
一旦某个专家到达,就可以开始对该专家进行计算。Janus将一个工人的所有非本地专家的请求分解为一组小任务,每个小任务中只需要拉入一个专家。因此,Janus可以以细粒度的方式调度这些小任务。这样做有三个好处:
- 一旦成功接收到专家,就可以立即开始计算该专家。因此,一个专家的计算和另一个专家的交流可以重叠,从而加快了训练的速度。
- 有限的GPU内存不可能容纳所有的专家。通过逐个请求专家,我们可以丢弃使用的专家,以招待稍后的专家。
- 通过调度,Janus避免了抓取专家导致的资源争用,从而可以提前接收到一些专家,并将其共享给本地机器中的其他工人。这样,可以进一步减少结点间的流量。
拓扑感知优先级策略

在GPU集群中,链路带宽是异构的。图(a)显示了一台A100机器的内部链路,
- GPU通过NVlink连接,带宽为600GB/s。最快
- GPU通过PCIe连接到机器的CPU,带宽为64GB/s。其次
- 跨机连接通过GDR网卡,带宽为200Gbps。最慢
在从本地或外部机器的Worker 中获取专家时,忽略物理拓扑容易导致一些链路不必要的拥塞,影响通信效率。因此,需要根据拓扑结构仔细考虑 作业的调度优先级。
对于每一个Worker 来说,需要拉的专家可以分为两部分。
| 位置 | 拉取方式 |
|---|---|
| 内部专家 | 存储在同一台机器中的工人中 内部专家是通过NVlinks直接拉出的 |
| 外部专家 | 由其他机器存储 必须通过RDMA网络拉到CPU内存中,然后复制到GPU内存中 |
当从其他本地GPU拉取内部专家 和 从cache Manager拉取外部专家时,可以通过适当的安排来缓解资源争用。具体安排如下:
- 如果所有的worker都按照相同的顺序拉取内部专家,那么被请求专家所在的GPU将同时接收来自不同worker的请求,这意味着流量需求在时间轴上是不平衡的,瓶颈将依次出现在每个GPU上。因此,Janus需要在第一阶段以交错顺序安排这些操作,如上图 Stage 2 所示。

- 当将专家从CPU内存复制到gpu内存时,流量需要通过PCIe链路。如果两个worker从CPU内存中请求相同的专家,该专家将进行两次PCIe切换。与NVlink效率相比,PCle链路效率是次优的,因此可以通过同机间的NVlink拉取来提高效率。如上图所示:一个worker首先通过PCIe将它负责的组中的专家从CPU内存中拉出,然后通过NVlink将另一个worker组中的专家从它的对等worker中拉出。这样可以减少与CPU和PCIe Switch相连的链路的工作负载。
预取测略
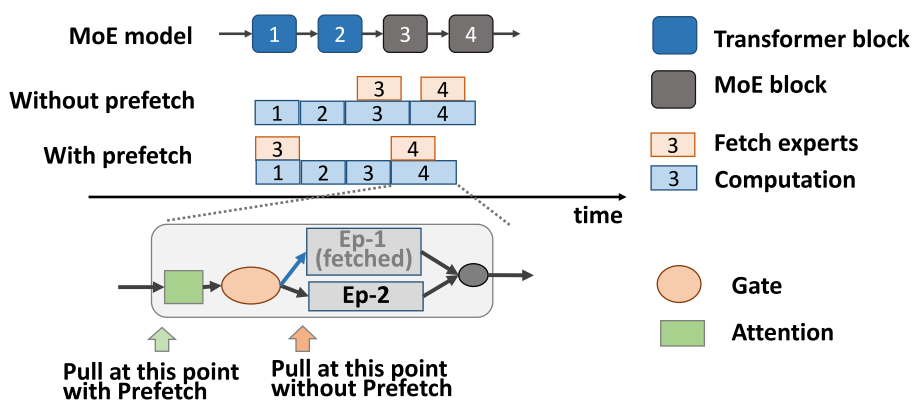
Data-centric Paradigm允许Janus在模型计算到达MoE模型块的入口之前拉专家,因为专家的权重不会在迭代中改变。因此,在迭代开始时,Janus可以开始将所有外部专家拉到本地CPU内存中,以利用跨节点链接的空闲时隙。采用预取机制,在Gate中计算完成后,专家计算可以立即开始,无需等待长时间的专家抓取,可以加快训练。
如上图所示,当一个worker在Transformer块或混合专家模型块的Attention层中执行计算时,它不需要与其他worker交换信息,因此在这些时间段中它的通信链路可能是空闲的(至少未被充分利用)。
实验结果
End-to-End Performance

上图显示了Janus和Tutel的端到端性能。在端到端性能方面,Janus可以大大降低一次迭代的时间成本,三种模型分别达到1.28×、1.48×、1.52×加速。
Ablation Study

上图的消融实验结果表明,Data-centric Paradigm是提高效率的主要贡献者。在没有拓扑感知优化和预取策略的Data-centric Paradigm中,MoE-BERT、MoE-GPT、MoETransformer-xl的训练速度可以分别达到1.26×、1.58×和1.79×。这是因为在这种模式下,交通量大大减少了。
基于拓扑感知的调度策略和预取策略都对预取策略有增量和有效的贡献。在所有优化条件下,MoE-BERT、MoE-GPT、MoE-Transformer-xl训练速度分别达到1.31×、1.63×和1.81×。
Janus中Data-centric和Expert-centric的统一

Janus优于纯Expert-centric Paradigm和纯Data-centric Paradigm。与Expert-centric Paradigm相比,它在16 gpu集群和32 gpu集群上的速度分别提高了2.06× 1.44×。随着GPU数量(即机器数量)的增加,Expert-centric Paradigm、Data-centric Paradigm和统一范式的迭代时间都在增加。
3.文章总结
本文提出了Data-centric Paradigm和Janus设计思想。Data-centric Paradigm创造性地提出,数据可以在适当的位置,模型可以在专家并行中移动,而人们总是认为模型在适当的位置,数据可以在专家并行中移动。Data-centric Paradigm提供了并行性的一个新维度。
Janus统一了Expert-centric Paradigm和Data-centric Paradigm,是最优的沟通模式。Data-centric Paradigm可以在一定条件下减少通信流量,实现通信负载均衡。
为了提高系统效率,本文精心设计了抓取专家请求的调度策略,包括异步通信、分层通信中的缓存机制、拓扑件优先级管理和预取机制。
- 通过异步通信,专家计算可以与获取专家的操作重叠。
- 利用高速缓存机制,本文减少了节点间的通信流量。
- 通过仔细安排请求的优先级,本文减轻了内部节点链路带宽上的争用。
- 本文利用预取机制实现了通信和计算的进一步重叠。
所有这些策略都有助于减少训练时间。实验证明了该系统的有效性。
这篇关于Janus: 逆向思维,以数据为中心的MoE训练范式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





