本文主要是介绍Hive2安装Tez计算引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Tez介绍
ApacheTEZ®项目旨在构建一个应用程序框架,该框架允许使用复杂的有向无环图来处理数据。 它当前构建在Apache Hadoop YARN之上。 Tez的2个主要设计主题是: 通过以下方式增强最终用户的能力: 富有表现力的数据流定义API 灵活的输入-处理器-输出运行时模型 不可知数据类型 简化部署 执行性能 与Map Reduce相比性能提升 最佳资源管理 在运行时计划重新配置 动态物理数据流决策
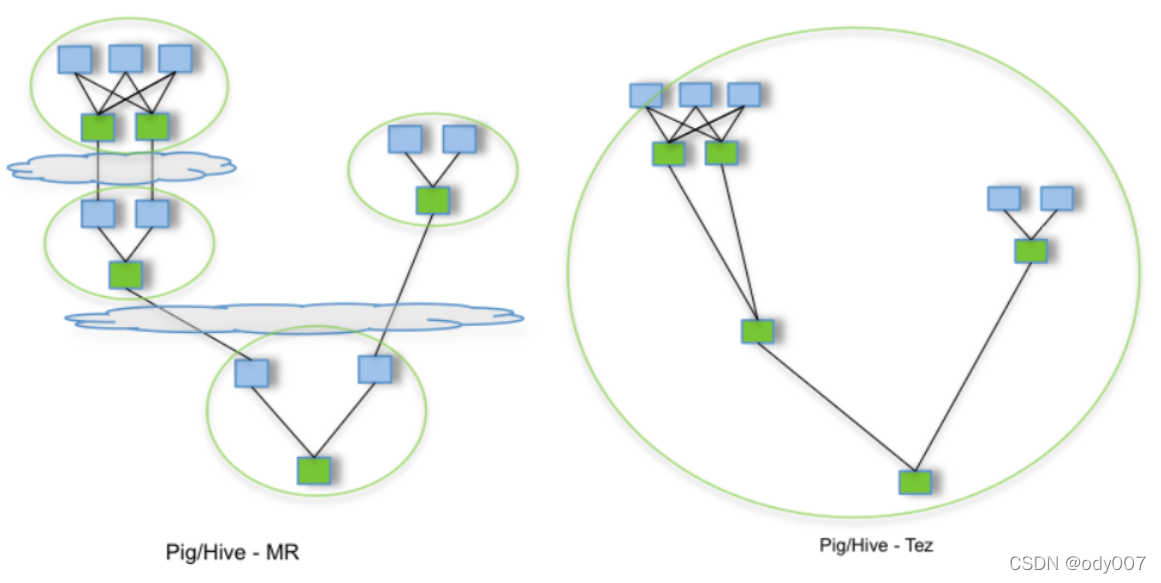
通过允许诸如Apache Hive和Apache Pig之类的项目运行复杂的DAG任务,Tez可以用于处理数据,该数据以前需要执行多个MR作业,而现在在单个Tez作业中,如下所示。
二、安装指南
1)下载 tez 的依赖包:Apache Tez – Welcome to Apache TEZ® 或从国内镜像源下载 Index of apache-local/tez/0.9.2 ![]() https://mirrors.huaweicloud.com/apache/tez/0.9.2/
https://mirrors.huaweicloud.com/apache/tez/0.9.2/

2)拷贝 apache-tez-0.9.2-bin.tar.gz 到 houda 的/software 目录
-
解压安装包到opt下
[root@houda share]# tar -zxvf /software/apache-tez-0.9.2-bin.tar.gz -C /opt/-
修改文件名字
[root@houda share]# mv /opt/apache-tez-0.9.2-bin /opt/tez5)将 tez.tar.gz 上传到 HDFS 的/tez 目录下
[root@houda opt]# cd /opt/tez/share/
[root@houda opt]# hadoop fs -mkdir /tez
[root@houda share]# hadoop fs -put ./tez.tar.gz /tez-
避免与hadoop、hive日志jar包冲突,删除tez的log4j包
[root@houda share]# rm -rf /opt/tez/lib/slf4j-log4j12-1.7.10.jar7)在hadoop创建tez-site.xml文件
[root@houda share]# vim /opt/hadoop-2.7.6/etc/hadoop/tez-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>hdfs://houda:9000/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property><description>Enable Tez to use the Timeline Server for History Logging</description><name>tez.history.logging.service.class</name><value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>-
编辑hadoop-env.sh脚本,在脚本最后,增加配置
[root@hd01 share]# vim /opt/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
export TEZ_CONF_DIR=/opt/hadoop-2.7.6/etc/hadoop
export TEZ_JARS=/opt/tez/
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*-
在yarn-site.xml中设置nodemanager的资源配置
[root@houda share]# vim /opt/hadoop-2.7.6/etc/hadoop/yarn-site.xml<property><name>yarn.nodemanager.resource.memory-mb</name><value>22528</value><discription>每个节点可用内存,单位MB</discription>
</property>
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>1500</value><discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>16384</value><discription>单个任务可申请最大内存,默认8192MB</discription>
</property>-
在hive-site.xml中设置tez计算引擎
[root@hd01 share]# vim /opt/hive-2.3.3/conf/hive-site.xml<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>-
重启hadoop服务测试
[root@houda share]# stop-all.sh && start-all.sh
[root@houda share]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in file:/opt/hive/conf/hive-log4j2.properties Async: true
hive (default)> select count(*) from default.emp;
Query ID = root_20201025200104_58fc10de-25ac-4acc-8d11-24fe0b0c7f0c
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1603626670053_0003)
----------------------------------------------------------------------------------------------VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 3.63 s
----------------------------------------------------------------------------------------------
OK
_c0
14
Time taken: 6.419 seconds, Fetched: 1 row(s)-
运算成功,说明修改成功。
这篇关于Hive2安装Tez计算引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








