本文主要是介绍操作系统之调度算法评价指标 (十二) --- 利用率、系统吞吐量、周转时间、等待时间、响应时间...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 调度算法评价指标
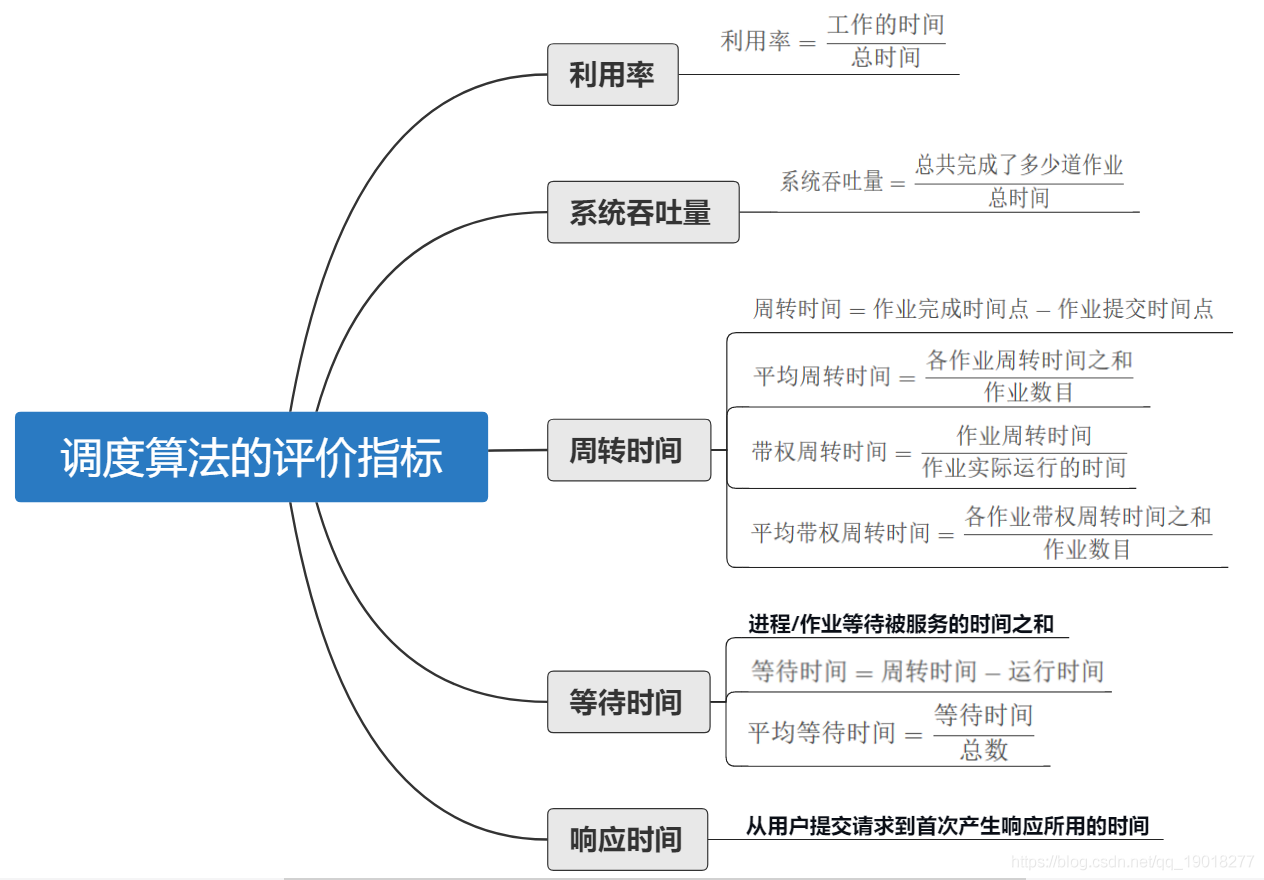
- 利用率
- 系统吞吐量
- 周转时间
- 等待时间
- 响应时间
- 总结
- 感谢
调度算法评价指标
利用率
我们先说说CPU利用率,由于早期CPU造价极其昂贵,因此人们希望让CPU尽可能多的工作。于是出现了一个衡量指标,CPU利用率。当然,利用率同样适用于其他设备。下面是利用率计算公式。
利 用 率 = 工 作 的 时 间 总 时 间 利用率 =\frac {工作的时间} {总时间} 利用率=总时间工作的时间
Eg:某计算机只支持单道程序,某个作业刚开始需要在CPU上运行5秒,再用打印机打印输出6秒,之后再在CPU运行7秒。问:在此过程中,CPU利用率、打印机利用率分别为多少?
直接给出计算结果。
C P U 利 用 率 = 5 + 7 5 + 6 + 7 = 66.66 % CPU利用率 =\frac {5 + 7} {5 + 6 + 7} = 66.66\% CPU利用率=5+6+75+7=66.66%
打 印 机 利 用 率 = 6 5 + 6 + 7 = 33.33 % 打印机利用率 =\frac {6} {5 + 6 + 7} = 33.33\% 打印机利用率=5+6+76=33.33%
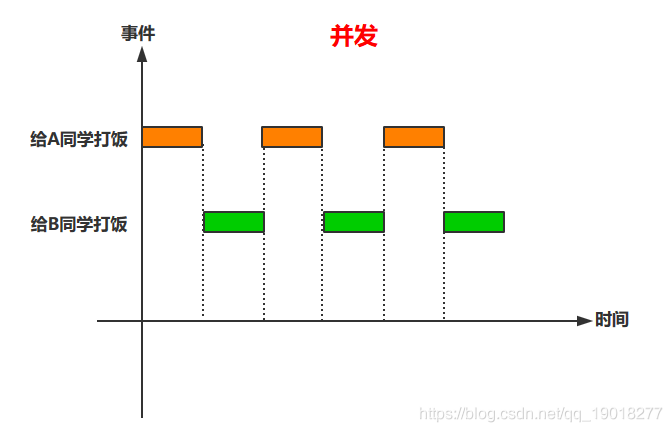
拓展:如果题目考察的是多道程序并发执行的情况,可以用"甘特图"来辅助计算。甘特图类似下图。
系统吞吐量
对于人们来说,人们希望计算机能用尽可能少的时间处理完尽可能多的作业,于是又出现了一个衡量指标,系统吞吐量。下面是系统吞吐量计算方法。
系 统 吞 吐 量 = 总 共 完 成 了 多 少 道 作 业 总 时 间 系统吞吐量 =\frac {总共完成了多少道作业} {总时间} 系统吞吐量=总时间总共完成了多少道作业
Eg:某计算机处理完10道作业,费时100秒,请计算系统吞吐量。
系 统 吞 吐 量 = 10 100 = 0.1 道 / 秒 系统吞吐量 =\frac {10} {100} = 0.1道/秒 系统吞吐量=10010=0.1道/秒
周转时间
对于计算机用户来说,他们很关心自己的作业从提交到完成花了多少时间。周转时间,是指作业从被提交给系统开始,到作业完成为止的这段时间间隔。它包括四个部分:作业从外存后备队列上等待作业调度(高级调度)的时间、进程在就绪队列上等待进程调度(低级调度)的世界、进程在CPU上运行的时间、进程等待I/O操作(即输入输出操作)完成的时间,注意后三项在一个作业的整个处理过程中可能发生多次。下面给出周转时间计算公式。
周 转 时 间 = 作 业 完 成 时 间 点 − 作 业 提 交 时 间 点 周转时间=作业完成时间点 - 作业提交时间点 周转时间=作业完成时间点−作业提交时间点
对于用户来说,他们关心自己的单个作业的周转时间,但是对于操作系统来说,操作系统更关心整体表现,于是出现了平均周转时间,即 周转时间的平均值。下面是平均周转时间的计算公式。
平 均 周 转 时 间 = 各 作 业 周 转 时 间 之 和 作 业 数 目 平均周转时间= \frac {各作业周转时间之和} {作业数目} 平均周转时间=作业数目各作业周转时间之和
当然,除了以上的两个时间,下面还有带权周转时间和平均带权周转时间,先说说为什么需要这两个衡量指标。
我们知道,作业之间的运行时间长短有所差距,有的长,有的短,因此在运行周转时间相同的情况下,运行不同的作业,给用户的感觉肯定是不一样的。
举个例子:
小明去打酱油,他打酱油很快,只需要1分钟。但是到酱油铺后,由于人太多了,小明等了10分钟才轮到自己,这是小明打酱油的经历。现在小红去打醋,她打醋要花10分钟,她到醋铺后只等了1分钟就轮到了自己。
我们可以算出他们的周转时间都是11分钟,但是他们的体验感有所不同,小明打酱油1分钟却等了10分钟,他肯定很暴躁。而小红打醋10分钟却只等了1分钟,她觉得这样的体验挺OK的。
回到操作系统,类比一下,打酱油和打醋都是作业,小明和小红作为用户。可以看出,他们在周转时间相同的情况下,体验是不一样的。
于是,人们提出了带权周转时间来衡量满意度。公式如下。
带 权 周 转 时 间 = 作 业 周 转 时 间 作 业 实 际 运 行 的 时 间 = 作 业 完 成 时 间 点 − 作 业 提 交 时 间 点 作 业 实 际 运 行 的 时 间 带权周转时间 =\frac {作业周转时间} {作业实际运行的时间} = \frac{作业完成时间点 - 作业提交时间点} {作业实际运行的时间} 带权周转时间=作业实际运行的时间作业周转时间=作业实际运行的时间作业完成时间点−作业提交时间点
可以看出,带权周转时间肯定大于等于一,因为作业周转时间包括了作业实际运行的时间。而且,带权周转时间越小,用户满意度越高,反之则越低。例如上面的小明小红,他们的平均周转时间分别是11、1.1。
当然,操作系统更关心他们的整体满意度,所以出现了平均带权周转时间,即 带权周转时间的平均值,公式如下。
平 均 带 权 周 转 时 间 = 各 作 业 带 权 周 转 时 间 之 和 作 业 数 目 平均带权周转时间= \frac {各作业带权周转时间之和} {作业数目} 平均带权周转时间=作业数目各作业带权周转时间之和
等待时间
对于计算机的用户来说,他们希望自己的作业尽可能少的等待处理机。于是人们又提出了一个衡量指标, 等待时间。
等待时间,是指进程/作业处于等待处理机状态的时间之和,显然,等待时间越长,用户满意度越低。公式如下。
等 待 时 间 = 周 转 时 间 − 运 行 时 间 等待时间 =周转时间 - 运行时间 等待时间=周转时间−运行时间
注意:
对于作业来说,不仅要考虑作业建立为进程后的等待时间,还要加上作业在外存后备队列中等待的时间。
对于进程来说,等待时间就是指进程建立后等待被服务的时间之和,在等待I/O完成的期间其实也是在被服务,所以不计入等待时间。
如果进程被I/O设备服务,那该服务时间也算入运行时间。

与前面的指标类似,操作系统依靠平均等待时间来评价整体性能。
平 均 等 待 时 间 = 等 待 时 间 总 数 平均等待时间=\frac {等待时间} {总数} 平均等待时间=总数等待时间
响应时间
对于计算机用户来说,他们希望自己提交的请求尽早的开始被系统服务、回应,于是人们提出响应时间来衡量这个尺度。
响应时间,指从用户提交请求到首次产生响应所用的时间。
总结
感谢
以上内容大部分来自王道操作系统系列视频教学。
这篇关于操作系统之调度算法评价指标 (十二) --- 利用率、系统吞吐量、周转时间、等待时间、响应时间...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




