本文主要是介绍Redis LFU缓存淘汰算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
Redis 在 4.0 版本之前的缓存淘汰算法,只支持 random 和 lru。random 太简单粗暴了,可能把热点数据给淘汰掉,一般不会使用。lru 比 random 好一点,会优先淘汰最久没被访问的数据,但是它也有一个缺点,就是无法真正表示数据的冷热程度。
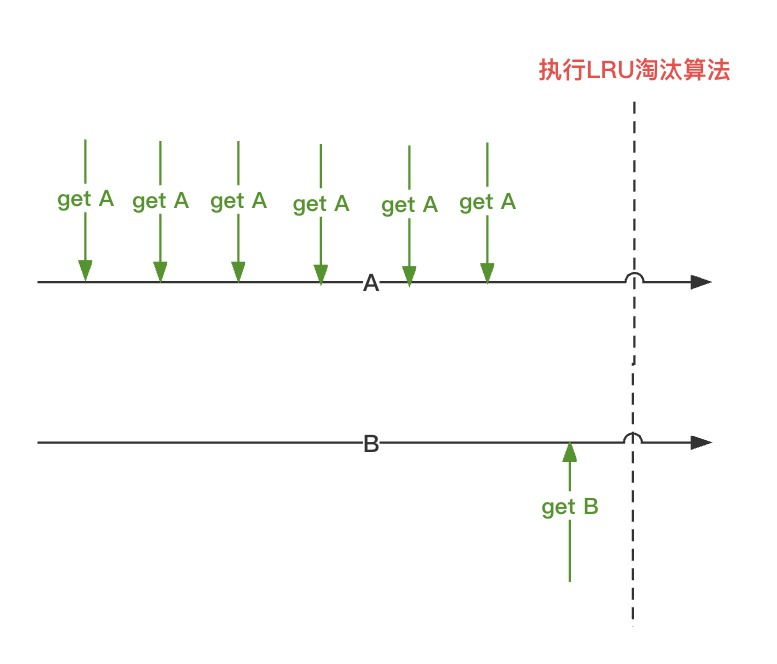
如下示例,A 之前被频繁访问,B 在执行 LRU 淘汰前恰巧被访问了一次,记录了最新的时间戳。此时触发 LRU 淘汰算法,反而会把 A 给淘汰掉。但事实是,A 的热度明显比 B 高。
针对这个问题,Redis 终于在 4.0 版本推出了全新的缓存淘汰策略:LFU。
LFU(Least Frequently Used)也叫 最不频繁使用 算法,它会把访问频率最低的数据给淘汰掉。举个例子:A 十分钟内访问了十次,B 十分钟内访问了五次,哪怕 B 是最后一次被访问的,因为它访问频率低,所以会优先淘汰。
要想启用 LFU 淘汰策略,首先要配置最大内存:
maxmemory 100MB
然后配置淘汰策略:
maxmemory-policy volatile-lfu / allkeys-lfu
有俩选项,它俩区别是:
- allkeys-lfu:针对所有键值对的 LFU 淘汰策略
- volatile-lfu:仅针对设置了过期时间的键值对的 LFU 淘汰策略
这样就开启 LFU 淘汰策略了,但是,关于 LFU 还有两个配置你也要关心:
lfu-log-factor 10
lfu-decay-time 1
它们的作用分别是:
- lfu-decay-time:LFU 计数器衰减的时间单位,默认一分钟
- lfu-log-factor:LFU 计数器递增的系数,值越大,递增的难度越大
Redis LFU实现
和 LRU 一样,Redis 也没有提供严格的 LFU 实现,因为开销太大了,也是近似 LFU 算法。并且,LFU 算法复用了 LRU 算法用到的 RedisObject 里的 lru 字段。Redis 会根据不同的淘汰策略写入不同的值。
LRU 算法和 LFU 算法不能同时启用
我们知道,Redis 会为键值对创建 RedisObject 对象,并在对象里用 24 Bit 来记录 lru 字段。如果配置的是 LFU 淘汰算法,则写入的是 LFU 相关的信息。
要实现 LFU 算法需要统计两个维度的数据,才能计算访问频率:
- 访问的次数
- 访问的时间
但是 Redis 只有一个 lru 字段能用,不得已而为之,Redis 不得不把 lru 拆分成两部分:高 16 位记录时间戳,低 8 位记录计数器。
Redis 先获取 LFU 时间戳,然后左移 8 位,低 8 位用来保存计数器,计数器的默认值是 5。
#define LFU_INIT_VAL 5
robj *createObject(int type, void *ptr) {robj *o = zmalloc(sizeof(*o));o->type = type;o->encoding = OBJ_ENCODING_RAW;o->ptr = ptr;o->refcount = 1;if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {// 当前分钟级时间戳保留低16位 | 默认计数器的值5o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;} else {// 写入LRU时间戳o->lru = LRU_CLOCK();}return o;
}
LFU 时间戳是以 分钟 为单位的,因为只有 16 位,所以最多能表示 65535 分钟,约 45 天,超过这个时间就溢出了。
unsigned long LFUGetTimeInMinutes(void) {return (server.unixtime/60) & 65535;
}
之后每次访问 Key 都会修改 LFU 信息,方法是updateLFU() 。Redis 首先会计算衰减后的计数器值,再判断要不要递增,最后把新值重新写会对象。
void updateLFU(robj *val) {// 衰减并返回计数器unsigned long counter = LFUDecrAndReturn(val);// 根据规则递增计数器 不一定会递增counter = LFULogIncr(counter);// 重新写入时间戳和计数器val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
衰减并返回计数器的方法是LFUDecrAndReturn() ,为什么计数器还要衰减呢?
因为 LFU 是按照访问频率的高低来淘汰缓存的,当缓存太久没被访问,它的计数器就应该被衰减,这样才能真实反映数据的热度,如果不衰减,不就变回 LRU 算法了嘛。
衰减的策略很简单,计算缓存闲置的以分钟为单位的时间,除以配置的lfu_decay_time 衰减时间单位,结果就是要衰减的值,计数器最多减到 0。默认衰减时间单位是一分钟,例如一小时没被访问,计数器就会衰减 60。
unsigned long LFUDecrAndReturn(robj *o) {// 时间戳unsigned long ldt = o->lru >> 8;// 计数器unsigned long counter = o->lru & 255;// 计算衰减值 lfu_decay_time:衰减时间单位,默认1分钟 闲置时间/lfu_decay_timeunsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;// 返回衰减后的计数器if (num_periods)counter = (num_periods > counter) ? 0 : counter - num_periods;return counter;
}
计数器衰减以后,Redis 接下来要开始对计数器做递增操作了,但是不会轻易递增计数器。
为什么不是每次访问都递增计数器呢?你别忘了,计数器只有 8 Bit,最多也只能表示 255,如果每次访问 Key 都直接递增计数器,很容易一下就打满了,当所有 Key 的计数器都打满了,计数器就没有意义了,无法判断数据的热度了,因为大家都一样热。
所以,Redis 会有一套递增规则,方法是LFULogIncr() 。首先会取一个随机数,然后计算计数器与初始值的一个差值baseval ,用这个差值乘以一个递增系数lfu_log_factor +1 再求倒数记为阈值 p,只有当随机数小于阈值才会递增计数器。
uint8_t LFULogIncr(uint8_t counter) {if (counter == 255) return 255;// 获取随机数double r = (double)rand()/RAND_MAX;// 取一个基数,用来算更新阈值double baseval = counter - LFU_INIT_VAL;if (baseval < 0) baseval = 0;/*** 随机数小于阈值,计数器则加1,否则什么也不做* 1.counter越大,计数器增加的概率就越低* 2.lfu_log_factor越大,计数器增加的概率就越低 人为控制*/double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;return counter;
}
通过源码发现,随着计数器 counter 不断增大,递增的难度也随之增大,也就是越往后越难递增,这样就可以有效避免计数器很快被打满。
同时,Redis 还可以通过配置lfu_log_factor 递增系数,人为控制计数器递增的难度,值越大越难递增。默认系数是 10,大约命中 100 次,计数器加 10;命中 1000 次,计数器加 18。如下是不同系数下,命中率和计数器递增的关系。
+--------+------------+------------+------------+------------+------------+
| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
+--------+------------+------------+------------+------------+------------+
| 0 | 104 | 255 | 255 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 1 | 18 | 49 | 255 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 10 | 10 | 18 | 142 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 100 | 8 | 11 | 49 | 143 | 255 |
+--------+------------+------------+------------+------------+------------+
在缓存淘汰的处理上,LFU 和 LRU 的逻辑基本是一致的,Redis 会遍历数据库,然后随机采样一批 Key,衰减并返回计数器的值,以便更加真实的反映缓存的热度,然后按照计数器的值升序填充 EvictionPoolLRU 数组记为候选淘汰的 Key,然后优先淘汰计数器较小的 Key。
尾巴
Redis 支持三类缓存淘汰策略,分别是:随机、LRU 和 LFU。随机太简单粗暴,容易淘汰热数据,一般不用。LRU 只记录访问最新的时间戳,不能真实地反映数据的热度,所以也不能很好的淘汰掉真正冷的数据。LFU 是 LRU 的改进版本,它会按照数据的访问频率来淘汰数据,可以更真实的反映数据的热度。因为底层是复用的 lru 字段,所以 LFU 会把 lru 字段拆分成两部分,高 16 位记录访问时间戳,单位是分钟;低 8 位 记录计数器。因为记录的维度是访问频率,所以 Redis 会对计数器做衰减操作,越久不访问计数器衰减的越严重。同时,因为只有 8 位空间,最多能表示 255,所以 Redis 对计数器的递增策略采用对数递增的方式,不然每次访问都直接递增,计数器很容易一下被打满。
这篇关于Redis LFU缓存淘汰算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







