本文主要是介绍剖析深度学习中的epoch与batch_size关系、代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 1. 定义
- 2. 代码
前言
为了区分深度学习中这两者的定义,详细讲解其关系以及代码
1. 定义
在 PyTorch 中,“epoch”(周期)和 “batch size”(批大小)是训练神经网络时的两个重要概念
它们用于控制训练的迭代和数据处理方式。
一、Epoch(周期):
- Epoch 是指整个训练数据集被神经网络完整地遍历一次的次数。
- 在每个 epoch 中,模型会一次又一次地使用数据集中的不同样本进行训练,以更新模型的权重。
- 通常,一个 epoch 包含多个迭代(iterations),每个迭代是一次权重更新的过程。
- 训练多个 epoch 的目的是让模型不断地学习,提高性能,直到收敛到最佳性能或达到停止条件。
二、Batch Size(批大小):
- Batch size 指的是每次模型权重更新时所使用的样本数。
- 通过将训练数据分成小批次,可以实现并行计算,提高训练效率。
- 较大的 batch size 可能会加速训练,但可能需要更多内存和计算资源。较小的 batch size 可能更适合小型数据集或资源受限的情况。
- 常见的 batch size 值通常是 32、64、128 等。
三、如何理解它们的关系:
- 在训练过程中,每个 epoch 包含多个 batch,而 batch size 决定了每个 batch 中包含多少样本。
- 在每个 epoch 开始时,数据集会被随机划分为多个 batch,然后模型使用这些 batch 逐一进行前向传播和反向传播,从而更新权重。
- 一次 epoch 完成后,数据集会被重新随机划分为新的 batch,这个过程会重复多次,直到完成指定数量的 epoch 或达到停止条件。
总之,epoch 控制了整个训练的迭代次数,而 batch size 决定了每次迭代中处理的样本数量。这两个参数的选择取决于你的任务和资源,通常需要进行调优以获得最佳性能。
2. 代码
大致深度学习的代码中如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 创建一个包含数字1到10的数据集
X_train = torch.arange(1, 11, dtype=torch.float32)
y_train = X_train * 2 # 假设我们的任务是学习一个简单的线性关系,y = 2x# 转换数据为 PyTorch 张量
X_train = X_train.view(-1, 1) # 将数据转换为列向量
y_train = y_train.view(-1, 1)# 定义神经网络模型
model = nn.Sequential(nn.Linear(1, 1)
)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 创建 DataLoader 并指定 batch size
batch_size = 3
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)# 训练循环
num_epochs = 10
for epoch in range(num_epochs):total_loss = 0.0for i, (inputs, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()print("inputs:",inputs.numpy())average_loss = total_loss / len(train_loader)print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {average_loss:.4f}")
执行完的结果截图:
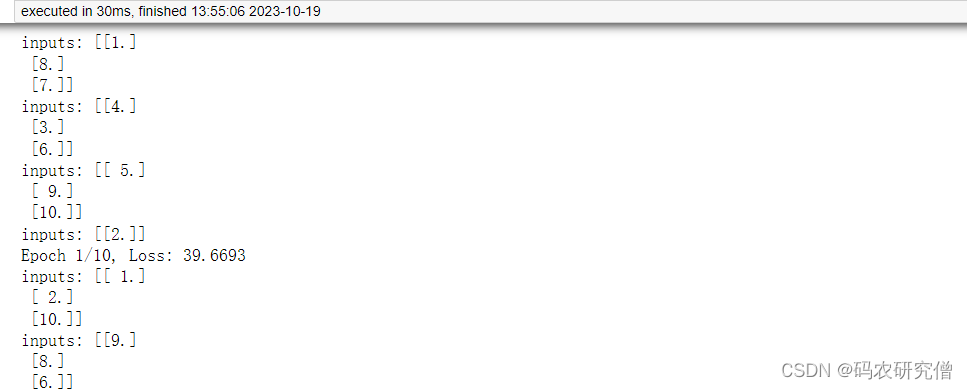
大致结果详细如下:
inputs: [[1.][8.][7.]]
inputs: [[4.][3.][6.]]
inputs: [[ 5.][ 9.][10.]]
inputs: [[2.]]
Epoch 1/10, Loss: 39.6693
inputs: [[ 1.][ 2.][10.]]
inputs: [[9.][8.][6.]]
inputs: [[5.][3.][7.]]
inputs: [[4.]]
Epoch 2/10, Loss: 0.1154
inputs: [[2.][1.][9.]]
inputs: [[10.][ 5.][ 4.]]
inputs: [[6.][8.][7.]]
inputs: [[3.]]
Epoch 3/10, Loss: 0.0317
inputs: [[7.][9.][1.]]
inputs: [[6.][3.][4.]]
inputs: [[10.][ 8.][ 5.]]
inputs: [[2.]]
Epoch 4/10, Loss: 0.0414
inputs: [[9.][6.][4.]]
inputs: [[2.][3.][1.]]
inputs: [[ 8.][10.][ 5.]]
inputs: [[7.]]
Epoch 5/10, Loss: 0.0260
inputs: [[6.][3.][4.]]
inputs: [[ 5.][10.][ 8.]]
inputs: [[2.][7.][9.]]
inputs: [[1.]]
Epoch 6/10, Loss: 0.0386
inputs: [[ 6.][10.][ 4.]]
inputs: [[5.][7.][8.]]
inputs: [[1.][9.][2.]]
inputs: [[3.]]
Epoch 7/10, Loss: 0.0254
inputs: [[6.][8.][2.]]
inputs: [[ 3.][10.][ 1.]]
inputs: [[9.][4.][5.]]
inputs: [[7.]]
Epoch 8/10, Loss: 0.0197
inputs: [[ 2.][ 3.][10.]]
inputs: [[9.][4.][5.]]
inputs: [[8.][1.][6.]]
inputs: [[7.]]
Epoch 9/10, Loss: 0.0179
inputs: [[ 7.][ 9.][10.]]
inputs: [[3.][2.][5.]]
inputs: [[4.][1.][8.]]
inputs: [[6.]]
Epoch 10/10, Loss: 0.0216
这说明一个epoch会把整个数据都训练完
这篇关于剖析深度学习中的epoch与batch_size关系、代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



