本文主要是介绍2022.3.25-2022.3.27前程无忧—数据分析求职需求分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
from scipy.stats import norm,mode
import re
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号
warnings.filterwarnings('ignore') #忽略警告1.读取csv,并且添加header
df = pd.read_csv('data_analysis_job.csv',header=None,names=['city','position','salary','working_length','degrees','numbers','requirements','job_information','company_type','company_size','industry'],encoding='gb18030')
df.info
df.shape #数据大小 (12439, 11)
2.数据清洗
2.1对整体数据初步处理——去重
df.duplicated().sum() #重复值的个数 1801
df.drop_duplicates(keep='first',inplace=True)
2.2检查缺失值,并处理
df.isnull().any()
df.isnull().sum() #每一列缺失值个数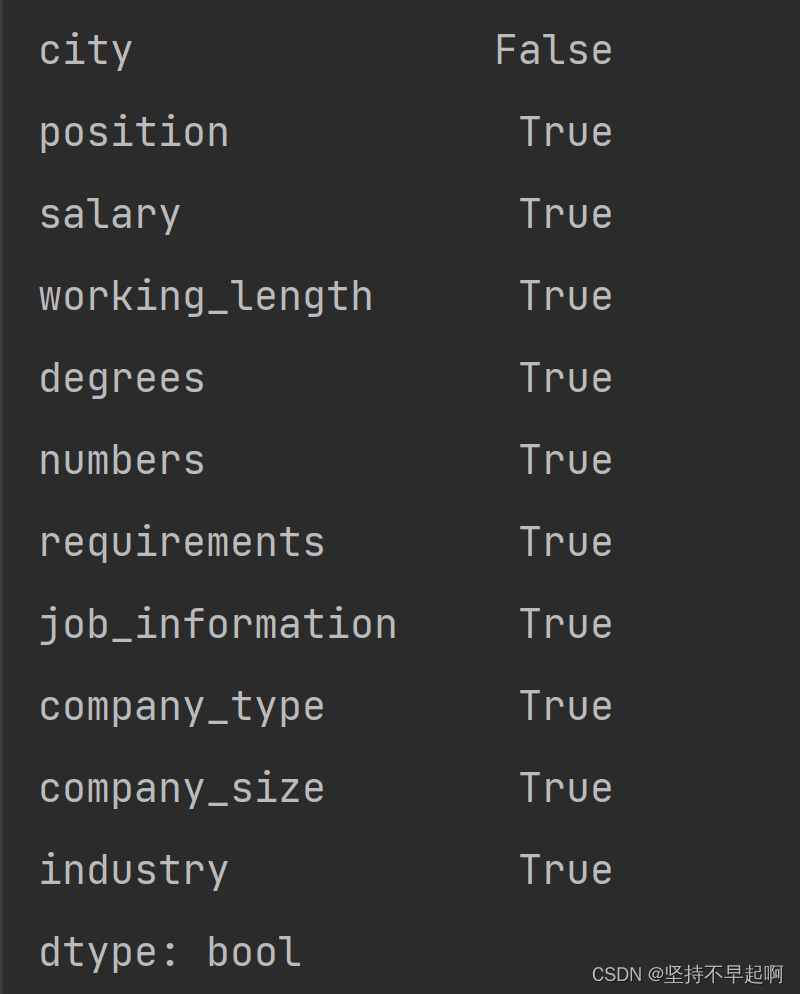
2.2.1 处理city
df['city'].unique()#查看字段是否需要清洗
#['广州' '深圳' '上海' '北京' '杭州' '重庆' '武汉' '天津' '南京' '苏州' '厦门' '长沙']2.2.2 处理salary
实习工资与全职计算不一样,所以去掉含有‘实习’的行,以方便统计
df= df[df['salary'].str.contains('\*')==False]
x=df['salary'].str.contains('实习')
df=df[~x]
df.reset_index(drop=True,inplace=True) #设置指引
查看salary拆分成两列,为最低和最高工资;年薪/12,变为月薪;时薪按每周上班5天变为月薪,并将数据类型转为float.
df['salary'].unique()
df['bottom']=df['salary'].str.extract('^(\d+).*').astype(float)
df['top']=df['salary'].str.extract('^.*?-(\d+).*').astype(float)
df['top'].fillna(df['bottom'],inplace=True) #如果最高缺失,利用最低填充
df.loc[df.salary.str.contains('年'), 'top'] = df['top'].map(lambda x: x/12)
df.loc[df.salary.str.contains('年'), 'bottom'] = df['bottom'].map(lambda x: x/12)
df.loc[df.salary.str.contains('时'), 'top'] = df['top'].map(lambda x: x*8*20)
df.loc[df.salary.str.contains('时'), 'bottom'] = df['bottom'].map(lambda x: x*8*20)
df.loc[df.salary.str.contains('天'), 'bottom'] = df['bottom'].map(lambda x: x*30/1000)
df.loc[df.salary.str.contains('天'), 'top'] = df['top'].map(lambda x: x*30/1000)
df.loc[df.salary.str.contains('万'), 'top'] = df['top'].map(lambda x: x*10)
df.loc[df.salary.str.contains('万'), 'bottom'] = df['bottom'].map(lambda x: x*10)计算出每个岗位的平均月薪资 avg_salary
df['avg_salary'] = (df['bottom']+df['top'])/2
df['avg_salary'] = df['avg_salary'].astype('int64')
df['avg_salary'].unique()插入表中
cols=list(df)
cols.insert(4,cols.pop(cols.index('bottom')))
cols.insert(5,cols.pop(cols.index('top')))
cols.insert(6,cols.pop(cols.index('avg_salary')))
df=df.loc[:,cols]
print(df['avg_salary'].unique())
print(df.describe())去掉一些极端值,这里设置平均值为2.5k-100k
df=df[(df.avg_salary>2.5)&(df.avg_salary<100)]
查看数据的统计信息
df.describe()
2.2.3 处理working_length
df['working_length'].unique()
df['working_length'].replace(np.nan,'无需经验',inplace=True)
2.2.4 处理degrees
df['degrees'].unique()
df['degrees'].replace(np.nan,'大专',inplace=True)#替换null为'大专'
2.2.5 处理industry
print(df['industry'].head(10))
print('-'*50) #查看数据
df['industry']=df['industry'].str.extract('(\S*)') #删除空格之后的描述(不影响分类)
print(df['industry'].unique())
#将相似行业合并为同一大类
df.loc[df.industry.str.contains('互联网'), 'industry'] = '互联网'
df.loc[df.industry.str.contains('计算机'), 'industry'] = '互联网'
df.loc[df.industry.str.contains('游戏'), 'industry'] = '互联网'
df.loc[df.industry.str.contains('新能源'), 'industry'] = '新能源'
df.loc[df.industry.str.contains('通信'), 'industry'] = '通信'
df.loc[df.industry.str.contains('电信'), 'industry'] = '通信'
df.loc[df.industry.str.contains('金融'),'industry'] = '金融'
df.loc[df.industry.str.contains('银行'),'industry'] = '金融'
df.loc[df.industry.str.contains('保险'),'industry'] = '金融'
df.loc[df.industry.str.contains('投资'),'industry'] = '金融'
df.loc[df.industry.str.contains('咨询'),'industry'] = '金融'
df.loc[df.industry.str.contains('证券'),'industry'] = '金融'
df.loc[df.industry.str.contains('影视'),'industry'] = '媒体'
df.loc[df.industry.str.contains('广告'),'industry'] = '媒体'
print(df['industry'].head(10))
#观察industry列,对数量较少且为传统行业的数据归入其他行业
df.loc[~df['industry'].isin(['互联网','快速消费品(食品、饮料、化妆品)','电子技术/半导体/集成电路 ','制药/生物工程','服装/纺织/皮革 ','贸易/进出口','医疗设备/器械','批发/零售','汽车','金融','通信','机械/设备/重工 ','房地产','仪器仪表/工业自动化','交通/运输/物流','医疗/护理/卫生','建筑/建材/工程','媒体','多元化业务集团公司','教育/培训/院校 ','新能源']),'industry']='其他行业'
print(df['industry'].value_counts()) 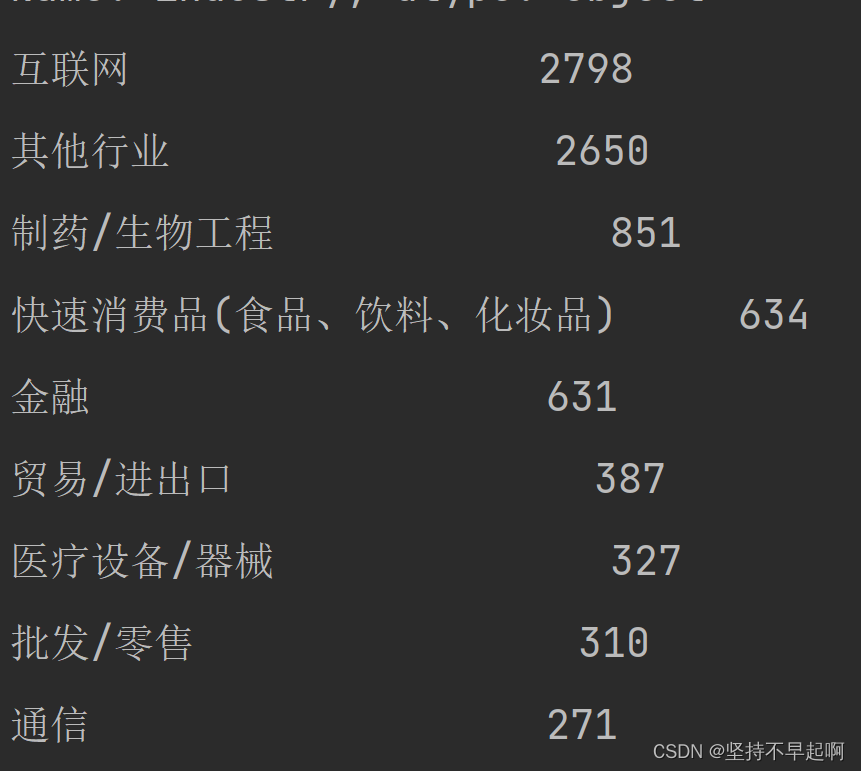
3.数据可视化和简单的分析
3.1 每个城市的平均薪资的中位数和平均数
df.avg_salary.groupby(df['city']).agg(['mean','median']).plot.bar(figsize=(16,8))
plt.show()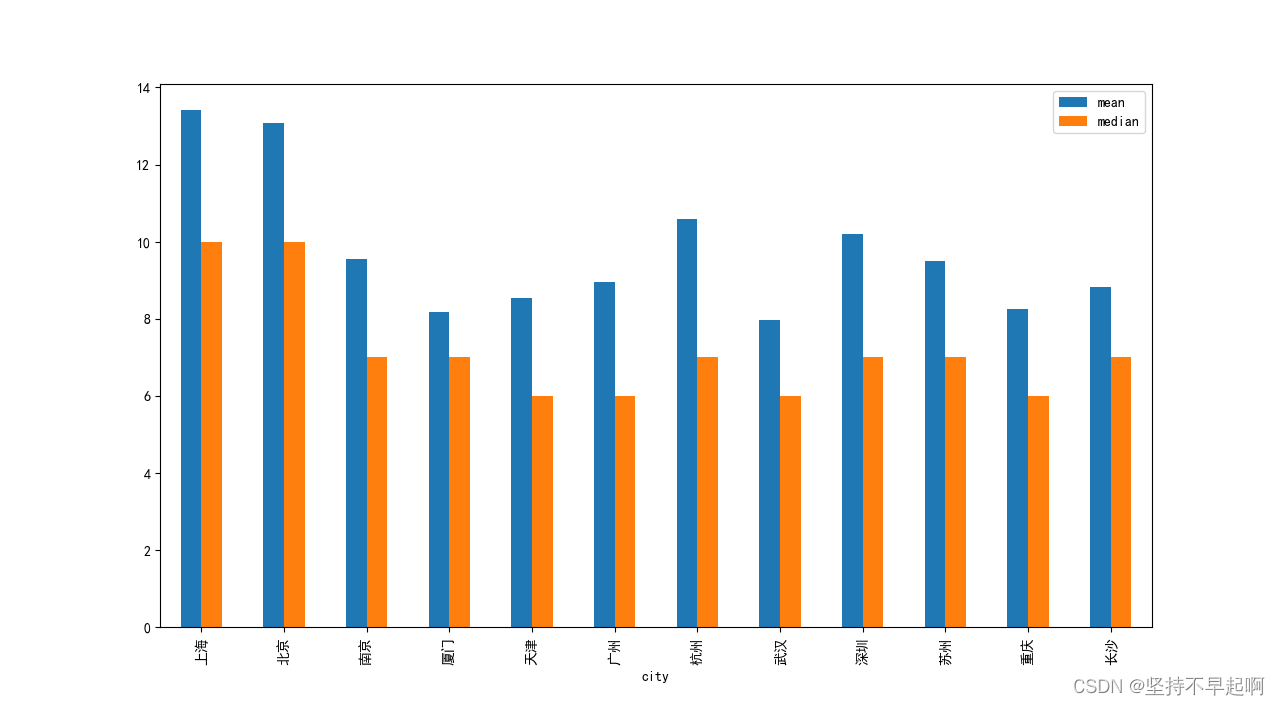
通过上图发现,北京、上海、杭州、深圳、南京工资较高于其他城市,武汉工资偏低。
3.2 薪资与岗位数之间的关系
fig=plt.figure(figsize=(12,6),dpi=80)
plt.hist(df['avg_salary'],bins=25,color='#f59311',alpha=0.3,edgecolor='k',log=True)
plt.ylabel('岗位数',fontsize=15)
plt.xlabel('薪资',fontsize=15)
plt.xticks(list(range(0,70,5)))
plt.show() 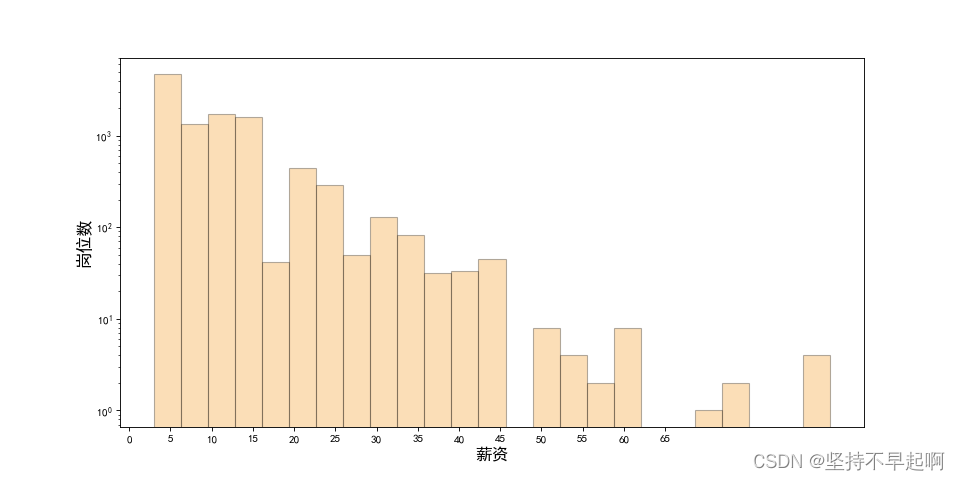
少部分人会拿到高工资,月薪4-5k的的岗位最多。
3.3薪资大于10K和小于10K各城市占比
plt.figure(figsize=(16,16),dpi=80)
plt.subplot(121)
temp = df[df.avg_salary<10].groupby('city').avg_salary.count()
plt.pie(temp,labels=temp.index,autopct='% .2f%%')
plt.title('薪资小于10K各城市占比')
plt.subplot(122)
temp = df[df.avg_salary>10].groupby('city').avg_salary.count()
plt.pie(temp,labels=temp.index,autopct='% .2f%%')
plt.title('薪资大于10K各城市占比')
plt.show() 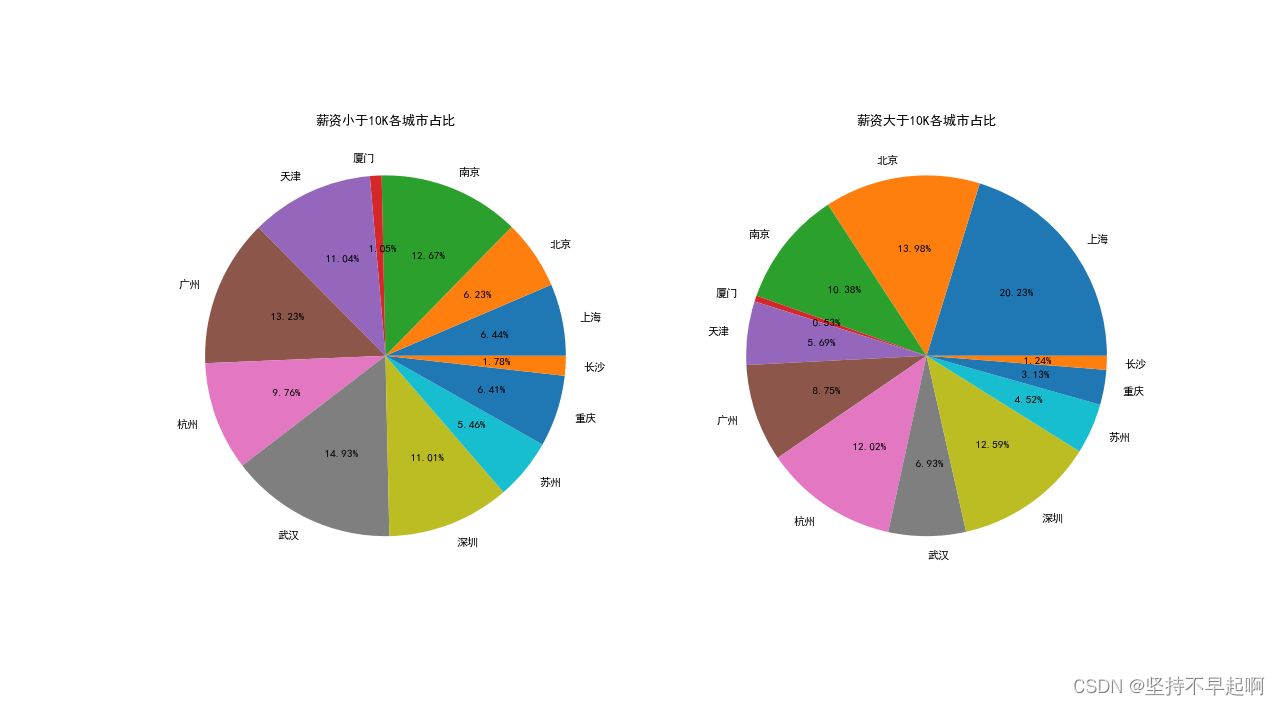
各个城市间薪资差距较大,低岗位主要在武汉、广州等城市。
3.4主要城市薪资水平的箱线图
data1=df[df.city=='北京']['avg_salary']
data2=df[df.city=='上海']['avg_salary']
data3=df[df.city=='广州']['avg_salary']
data4=df[df.city=='深圳']['avg_salary']
data5=df[df.city=='杭州']['avg_salary']
plt.figure(figsize=(12,6),dpi=80)
plt.boxplot([data1,data2,data3,data4,data5],labels=['北京','上海','广州','深圳','杭州'],flierprops={'marker':'o','markerfacecolor':'r','color':'k'},patch_artist=True,boxprops={'color':'k','facecolor':'#FFFACD'})
ax=plt.gca()
ax.patch.set_facecolor('#FFFAFA')
ax.patch.set_alpha(0.8)
plt.title('主要城市薪资水平箱线图',fontsize=15)
plt.ylabel('薪资(单位:k)',fontsize=12)
plt.show()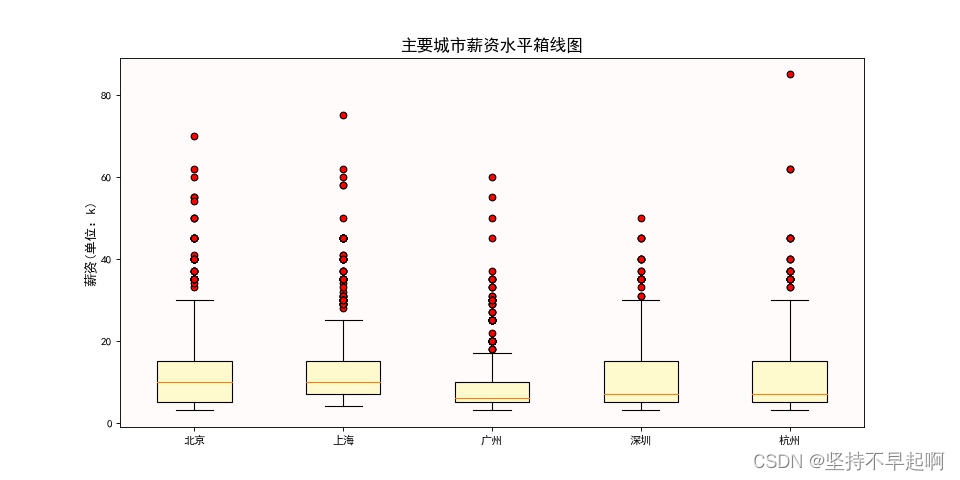
我们可以发现北京和上海的平均薪资水平差不多,广州的平均薪资较低且两级分化较小。
3.5各学历薪资均值和中位数
d = df['avg_salary'].groupby(df['degrees'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(14,8),dpi=80)
plt.bar(v,w,width=move,color='#eed777')
plt.bar([i+move for i in v],x,width=move,color='#334f65')
a = np.arange(0,6)+1.2
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各学历薪资均值及中位数比较图',fontsize=16)
plt.xlabel('学历',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()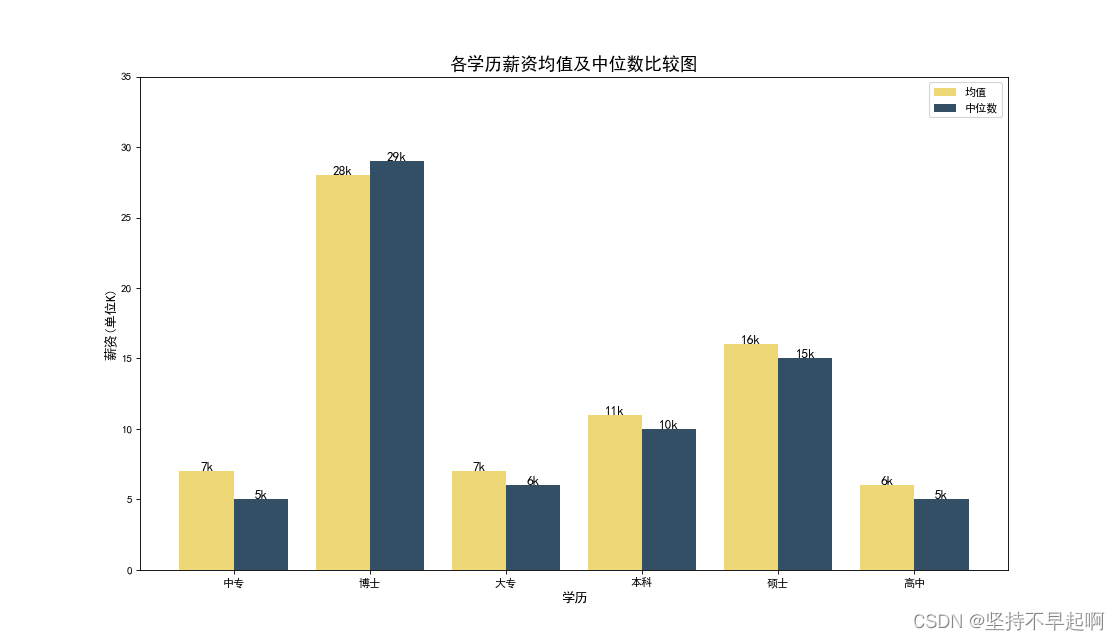
可以发现,本科以上学历的薪资明显升高,博士与硕士的薪资差距明显高于,硕士与本科的薪资差距。
3.6 市场对学历的需求
data = df['degrees'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()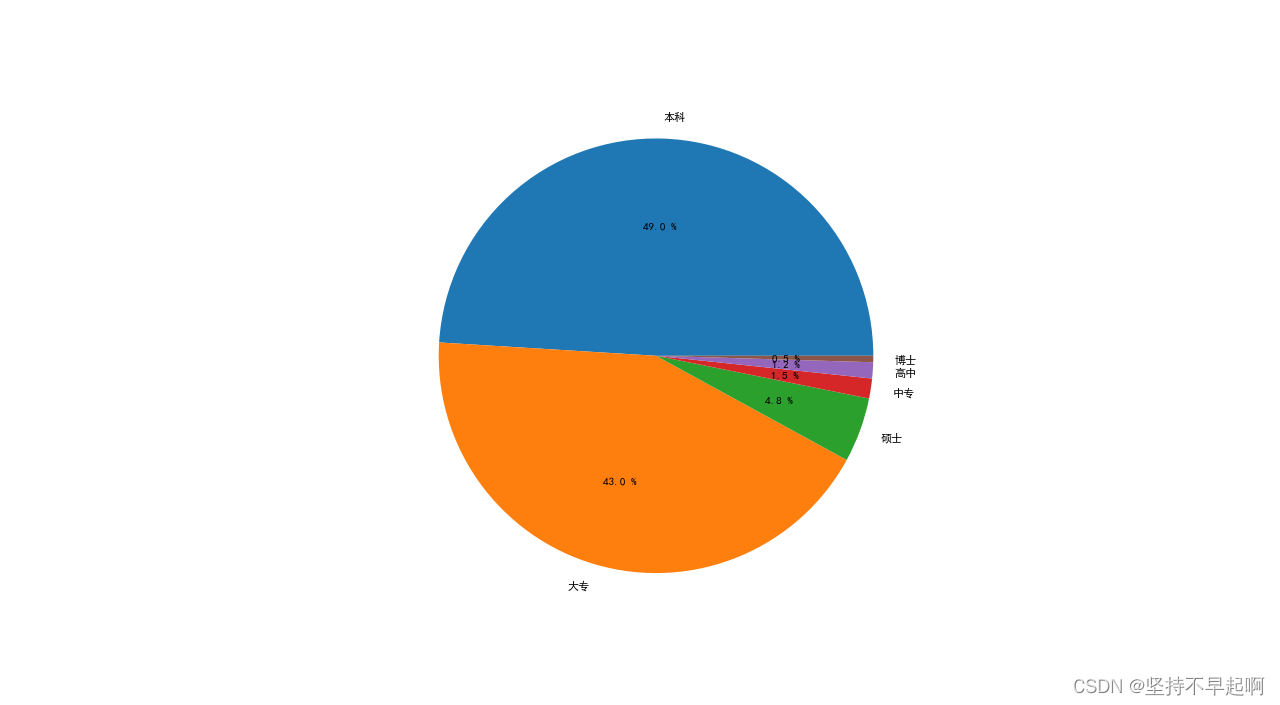
本科和大专占绝大多数,硕士较少,博士占极少数。
3.7工作年限薪资均值及中位数
d = df['avg_salary'].groupby(df['working_length'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(14,8),dpi=80)
plt.bar(v,w,width=move,color='#002c53')
plt.bar([i+move for i in v],x,width=move,color='#0c84c6')
a = np.arange(0,7)+1.2
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各工作年限薪资均值及中位数比较图',fontsize=16)
plt.xlabel('工作经验',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()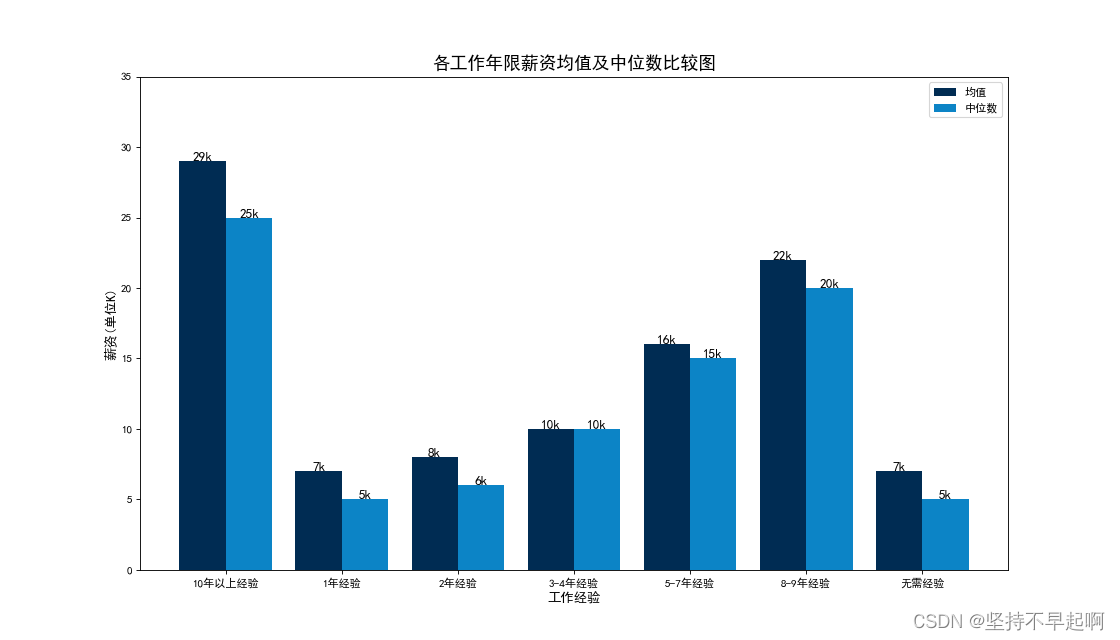
应届生工资较低,有5年以上的工作经验,工资明显增加。
3.8 市场对工作经验的需求
data = df['working_length'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()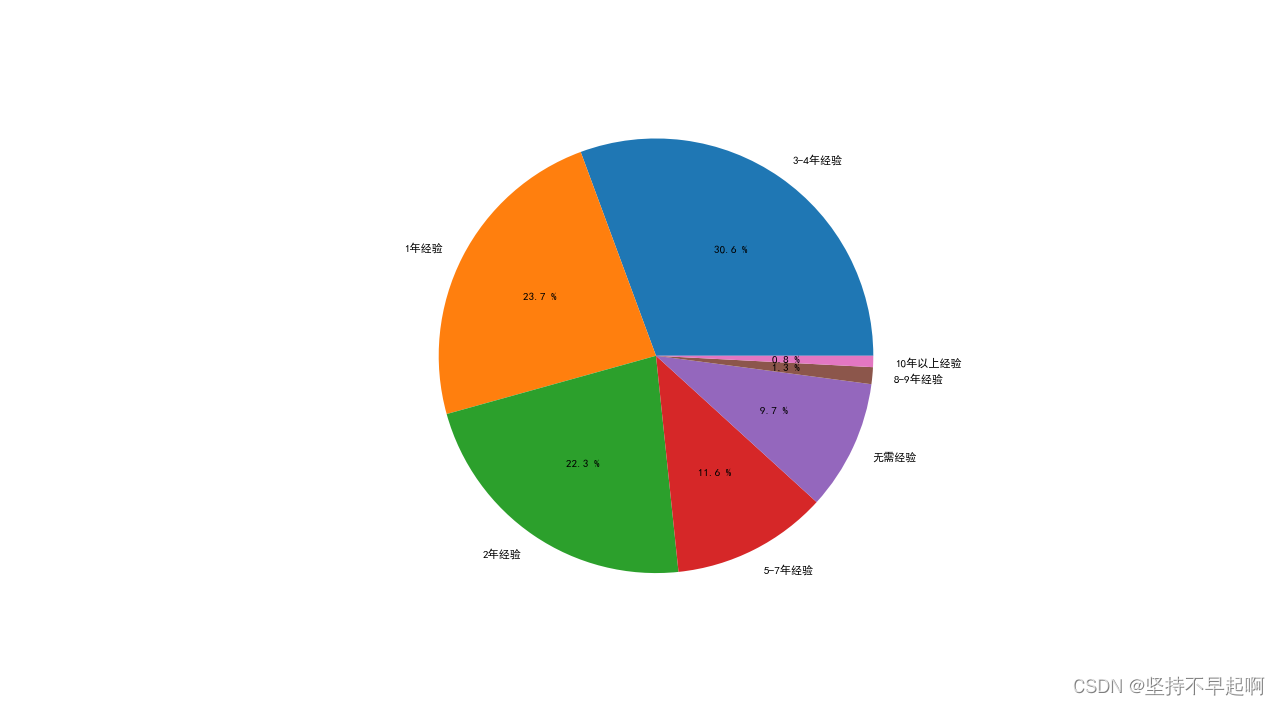
市场上对于工作经验的要求还是很强烈,1-4年的经验要求占绝大多数,工作经验是入职成功与否的关键因素。
3.9各个行业薪资均值及中位数
d = df['avg_salary'].groupby(df['industry'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(20,8),dpi=80)
plt.bar(v,w,width=move,color='#9de0ff')
plt.bar([i+move for i in v],x,width=move,color='#ffa897')
a = np.arange(0,18)+1.3
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各行业薪资均值及中位数比较图',fontsize=16)
plt.xlabel('行业',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()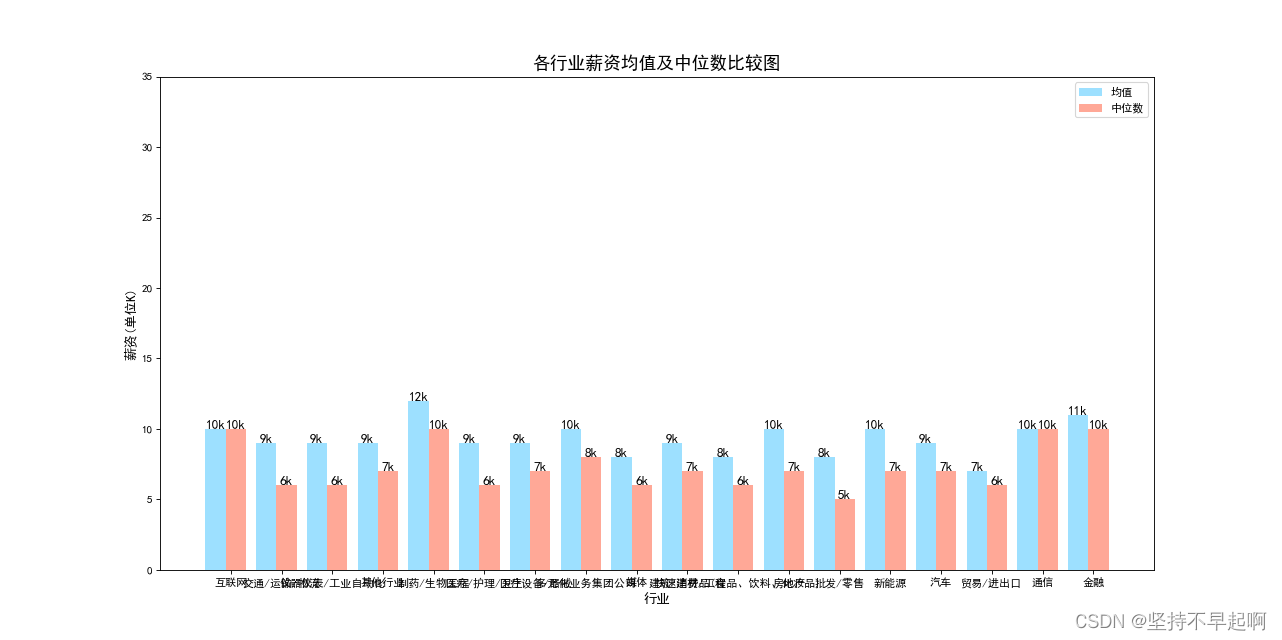
互联网、金融和生物制药行业相较于其他行业薪资较高。
3.10市场中各个行业的需求
data = df['industry'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()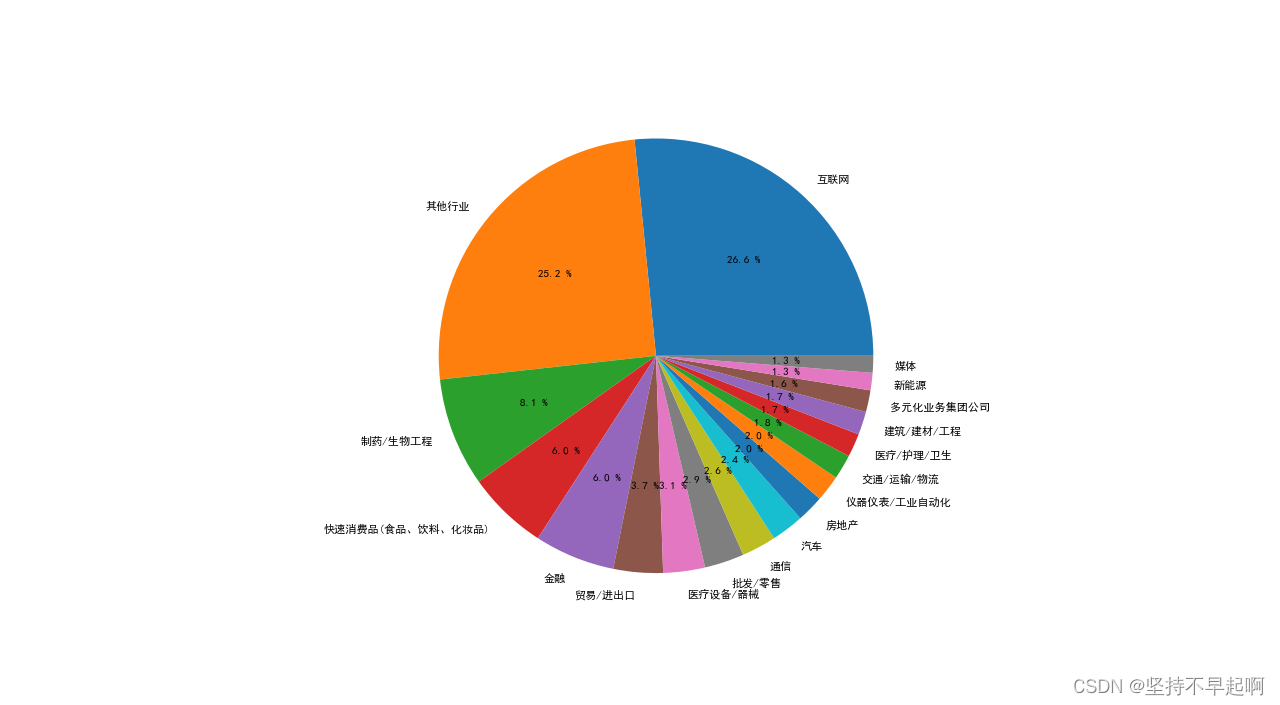
互联网、生物制药、快速消费品、金融等行业对该岗位需求较大。
4.总结
通过以上简要分析,如果想成功找到满意工作,应该往北京、上海、深圳、杭州、南京这几个城市考虑;而行业方面,互联网、生物制药、金融对该岗位需求较大,薪资普遍较高;工作经验对于该岗位而言比较重要,与薪资成正相关,在工作4-5年后,薪资会有较大的提升;对于学历,如果想进入这个行业,本科即可,但是博士会拿到更高的薪资,学历也与薪资水平呈正相关。
这篇关于2022.3.25-2022.3.27前程无忧—数据分析求职需求分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






