本文主要是介绍plink分析100个性状的批量gwas分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是邓飞。
GWAS分析时,3~5个性状是正常操作,要分析100个性状呢,手动修改参数,工作量是够了,但是程序员的修养体现在哪里了???
如果还是按照每个性状一个文件夹,每个文件夹中一个脚本,不断地修改脚本,一点也不高端,所以,遇到这种情况,批量处理就派上用场了。
之所以之前一直不用,因为10个性状一下,没有必要,费心思想还不如直接动手操作了,但是100个性状真的吓到我了,不满足才能有进步。就看了一下参数说明,然后五分钟搞定了。虽然五分钟搞定的事情,但是写博客20分钟记录一下还是有必要的,独乐乐不如众乐乐。
开始介绍。
plink中其实没有多性状模型的参数,但是它有一个--mpheno,指定性状所在的列,我们可以借用。
数据来源,GWAS Cookbook的GWAS-dat2,用下面代码生成表型数据:
library(data.table)dd = fread("phe.txt")
head(dd)set.seed(123)
xx = rnorm(150000)
nn = matrix(xx,1500,100) %>% as.data.frame()
nn[1:10,1:10]dd1 = cbind(dd,nn)
dd1[1:10,1:10]fwrite(dd1,"mphe.txt",col.names = F,quote = F,sep = " ")1. 表型数据
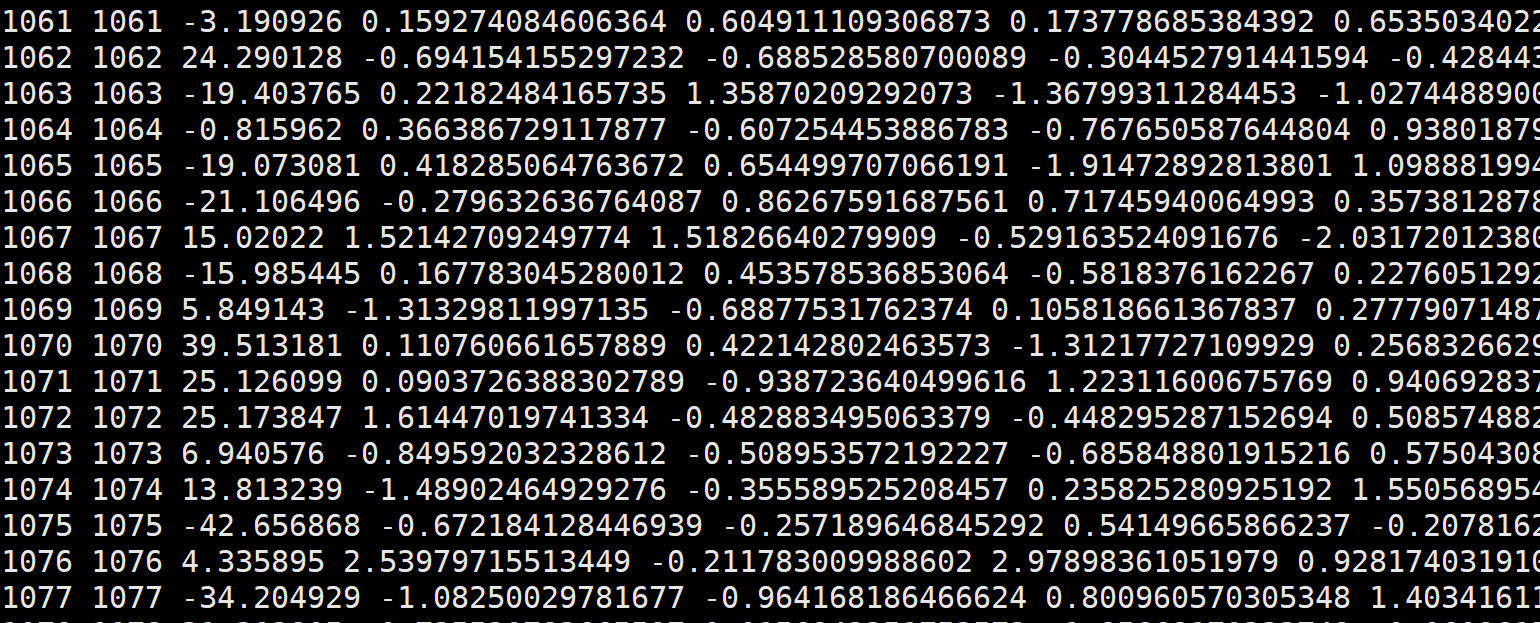
表型数据:模拟100个性状,整理为txt,第一列FID,第二列ID,第三列以后为性状
2. 基因型数据
3. 单个性状建模
用linear模型(GLM):
plink --file b --pheno mphe.txt --linear --allow-no-sex --out re1
结果文件:
$ ls re1*
re1.assoc.linear re1.log re1.nosexGWAS分析结果:
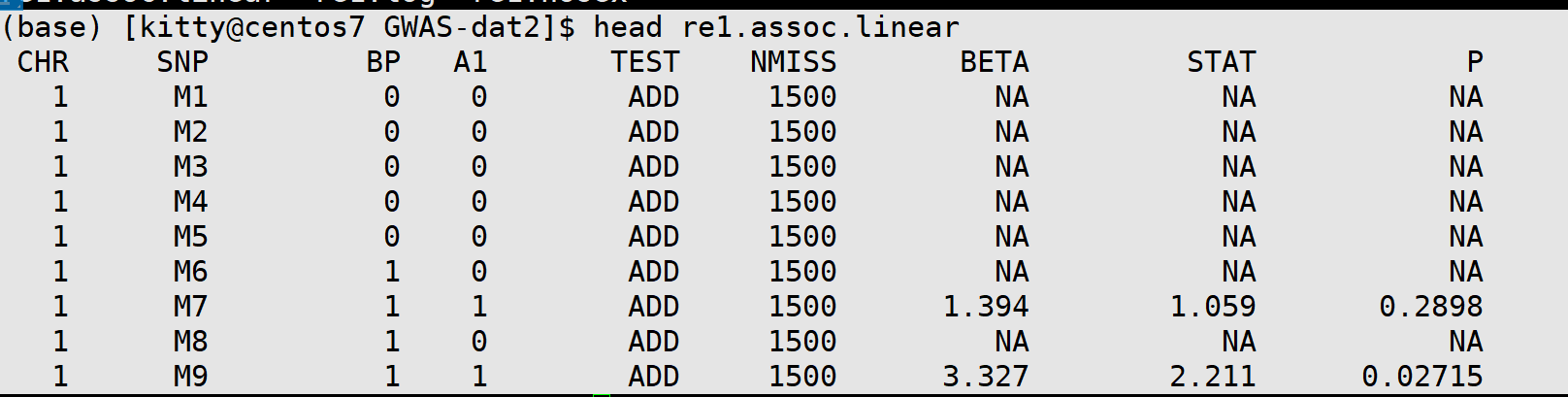
注意,上面基因型没有质控,所以有P值为NA的情况,正常质控的数据不会存在这种情况。
4. plink批量分析多性状gwas
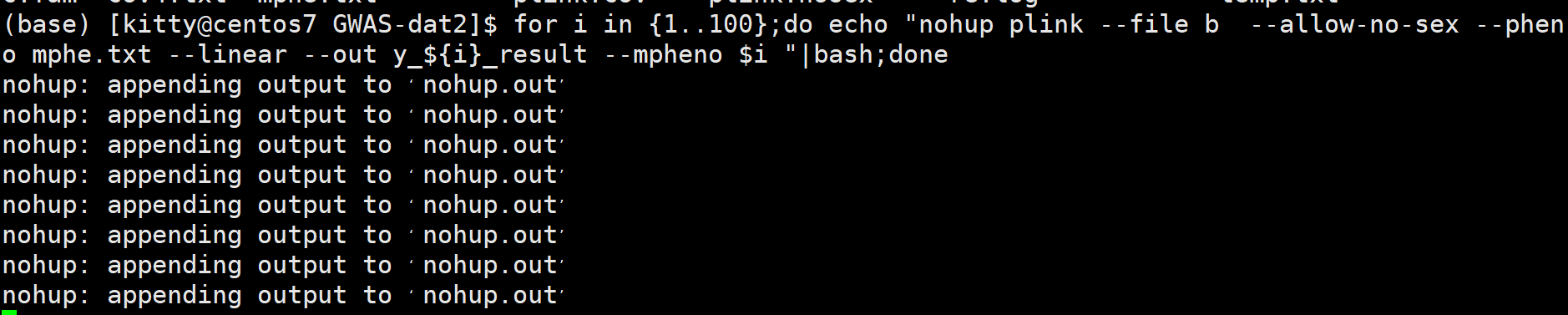
for i in {1..100};do echo "nohup plink --file b --allow-no-sex --pheno mphe.txt --linear --out y_${i}_result --mpheno $i "|bash;done
上面代码就是多性状gwas分析,代码解析:
- for 循环,1~100,表示100个性状,分别运行
- 正常进行gwas分析
- –mpheno 后面参数$i,是分别运行100次gwas分析
- –out 结果文件中,分别保存100个性状的gwas分析
- |bash;done,是用管道符的形式运行nohup
运行过程:
运行的结果:
随便找一个性状结果:
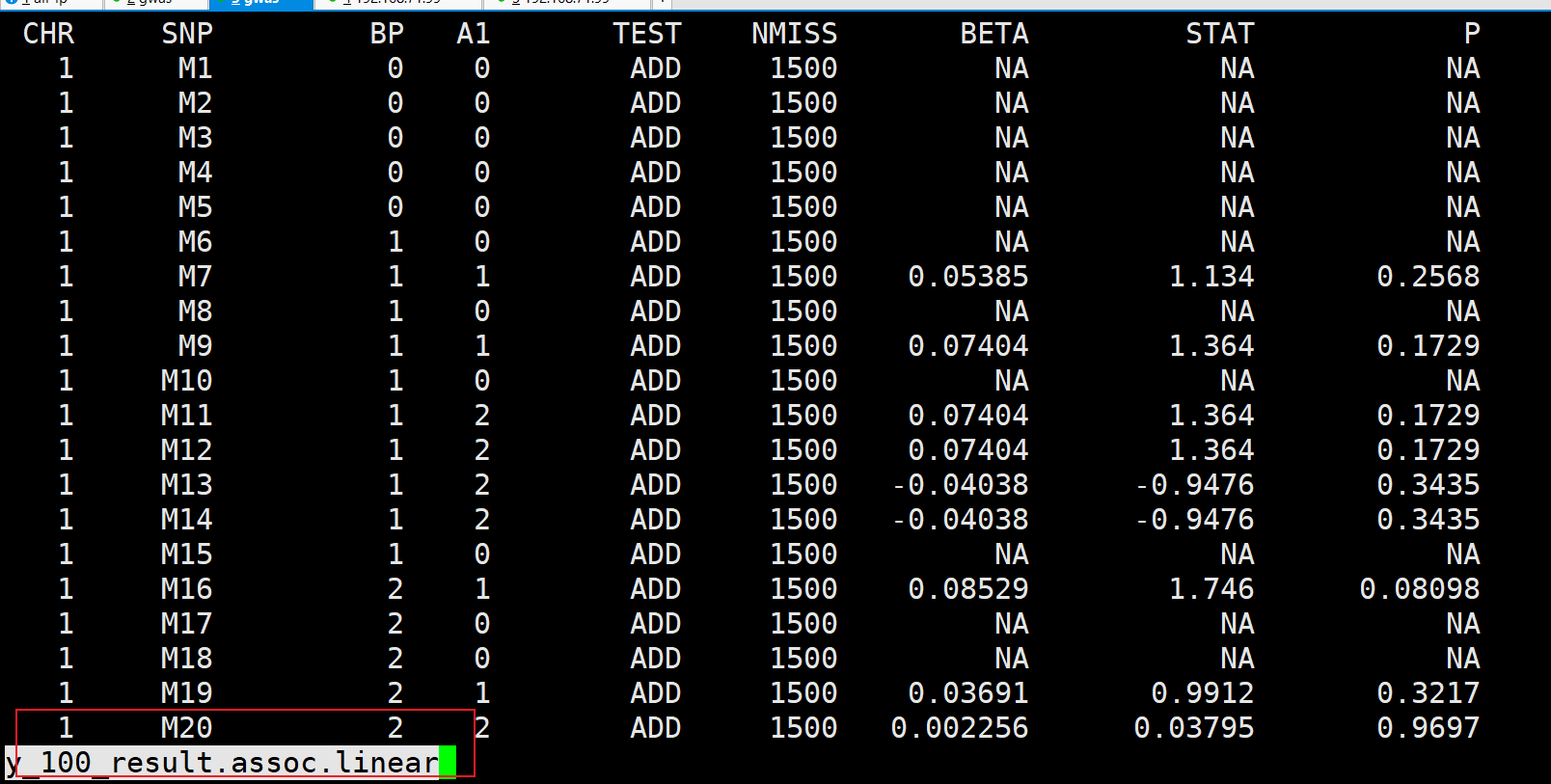
完全没问题。搞定!!!
上面的批量运行程序,不但可以是plink,也可以是gemma,gcta,GAPIT等软件,都可以按照这种写法,非常666!
这篇关于plink分析100个性状的批量gwas分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






