本文主要是介绍使用 LF Edge eKuiper 将物联网流处理数据写入 Databend,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:韩山杰
Databend Cloud 研发工程师
https://github.com/hantmac

LF Edge eKuiper
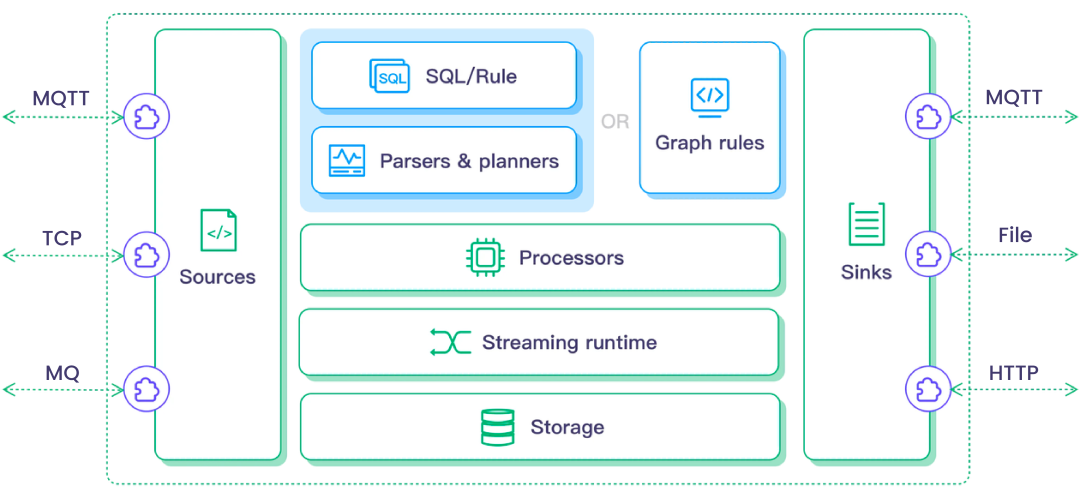
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架(类似于 Apache Flink (opens new window))。eKuiper 的规则引擎允许用户提供基于 SQL 或基于图形(类似于 Node-RED)的规则,在几分钟内创建物联网边缘分析应用。具体介绍可以参考 [LF Edge eKuiper - 超轻量物联网边缘流处理软件(https://ekuiper.org/docs/zh/latest/)。
Databend Sql Sink
eKuiper 支持通过 Golang 或者 Python 在源 (Source),SQL 函数, 目标 (Sink) 三个方面的扩展,通过支持不同的 Sink,允许用户将分析结果发送到不同的扩展系统中。Databend 作为 Sink 也被集成到了 eKuiper plugin 当中,下面通过一个案例来展示如何使用 eKuiper 将物联网流处理数据写入 Databend。
编译 eKuiper 和 Databend Sql Plugin
eKuiper
git clone https://github.com/lf-edge/ekuiper & cd ekuiper
makeDatabend Sql Plugin
go build -trimpath --buildmode=plugin -tags databend -o plugins/sinks/Sql.so extensions/sinks/sql/sql.go编译后的 sink plugin 拷贝到 build 目录:
cp plugins/sinks/Sql.so _build/kuiper-1.11.1-18-g42d9147f-darwin-arm64/plugins/sinksDatabend 建表
在 Databend 中先创建目标表 ekuiper_test:
create table ekuiper_test (name string,size bigint,id bigint);启动 eKuiperd
cd _build/kuiper-1.11.1-18-g42d9147f-darwin-arm64
./bin/kuiperd服务正常启动:

创建流(stream) 和 规则 (rule)
eKuiper 提供了两种管理各种流、规则,目标端的方式,一种是通过 ekuiper-manager 的 [docker image](https://hub.docker.com/r/lfedge/ekuiper) 启动可视化管理界面,一种是通过 CLI 工具来管理。这里我们使用 CLI。
创建 stream
流是 eKuiper 中数据源连接器的运行形式。它必须指定一个源类型来定义如何连接到外部资源。这里我们创建一个流,从 json 文件数据源中获取数据,并发送到 eKuiper 中。
首先配置文件数据源,连接器的配置文件位于 /etc/sources/file.yaml。
default:# 文件的类型,支持 json, csv 和 linesfileType: json# 文件以 eKuiper 为根目录的目录或文件的绝对路径。# 请勿在此处包含文件名。文件名应在流数据源中定义path: data# 读取文件的时间间隔,单位为ms。如果只读取一次,则将其设置为 0interval: 0# 读取后,两条数据发送的间隔时间sendInterval: 0# 是否并行读取目录中的文件parallel: false# 文件读取后的操作# 0: 文件保持不变# 1: 删除文件# 2: 移动文件到 moveTo 定义的位置actionAfterRead: 0# 移动文件的位置, 仅用于 actionAfterRead 为 2 的情况moveTo: /tmp/kuiper/moved# 是否包含文件头,多用于 csv。若为 true,则第一行解析为文件头。hasHeader: false# 定义文件的列。如果定义了文件头,该选项将被覆盖。# columns: [id, name]# 忽略开头多少行的内容。ignoreStartLines: 0# 忽略结尾多少行的内容。最后的空行不计算在内。ignoreEndLines: 0# 使用指定的压缩方法解压缩文件。现在支持`gzip`、`zstd` 方法。decompression: ""使用 CLI 创建 steam 名为 stream1:
./bin/kuiper create stream stream1 '(id BIGINT, name STRING,size BIGINT) WITH (DATASOURCE="test.json", FORMAT="json", TYPE="file");'
Json 文件的内容为:
[{"id": 1,"size":100, "name": "John Doe"},{"id": 2,"size":200, "name": "Jane Smith"},{"id": 3,"size":300, "name": "Kobe Brant"},{"id": 4,"size":400, "name": "Alen Iverson"}
]创建 Databend Sink Rule
一个规则代表了一个流处理流程,定义了从将数据输入流的数据源到各种处理逻辑,再到将数据输入到外部系统的动作。eKuiper 有两种方法来定义规则的业务逻辑。要么使用 SQL / 动作组合,要么使用新增加的图 API。
这里我们通过指定 sql 和 actions 属性,以声明的方式定义规则的业务逻辑。其中,sql 定义了针对预定义流运行的 SQL 查询,这将转换数据。然后,输出的数据可以通过 action 路由到多个位置。
规则由 JSON 定义,下面是准备创建的规则 myRule.json:
{"id": "myRule","sql": "SELECT id, name from stream1","actions": [{"log": {},"sql": {"url": "databend://databend:databend@localhost:8000/default?sslmode=disable","table": "ekuiper_test","fields": ["id","name"]}}]
}执行 CLI 创建规则:
./bin/kuiper create rule myRule -f myRule.json
可以查看所创建规则的运行状态:
./bin/kuiper getstatus rule myRule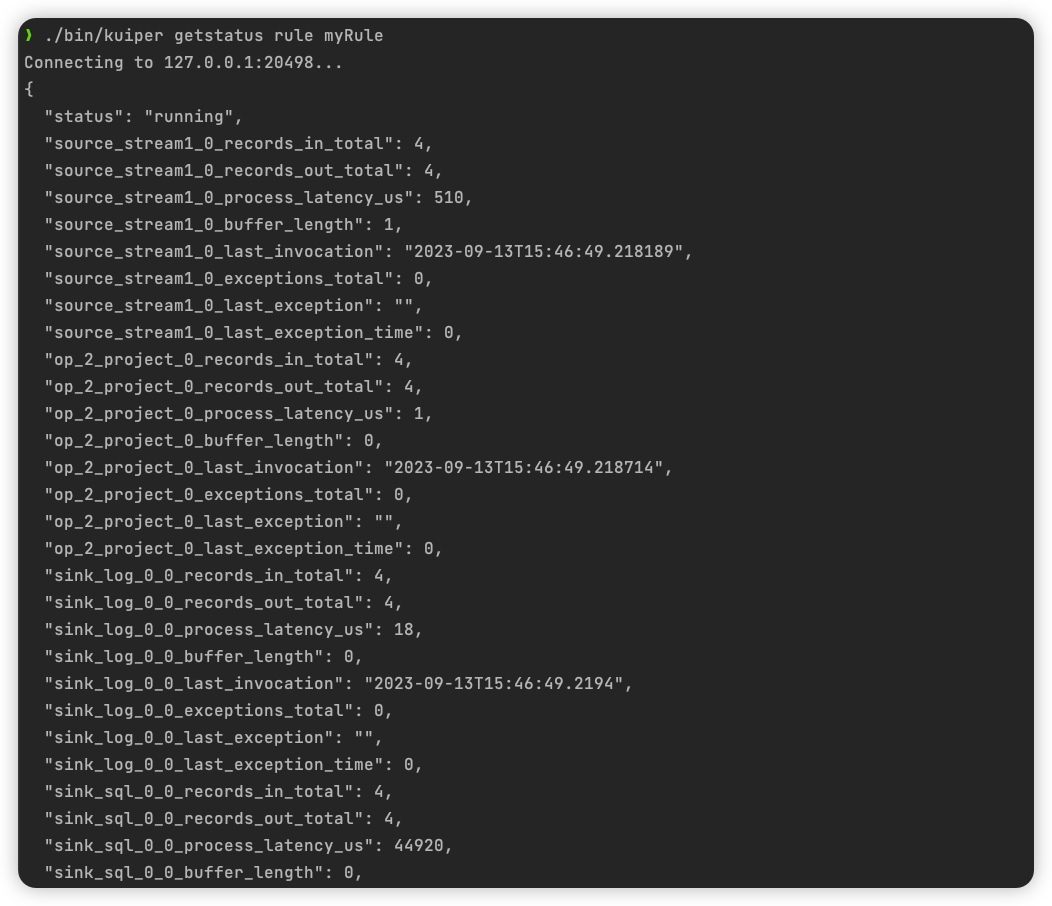
规则创建后,会立即将符合规则条件的数据发送到目标端,此时我们查看 Databend 的 ekuiper_test 表,可以看到文件数据源中的数据已经被写入到 Databend:
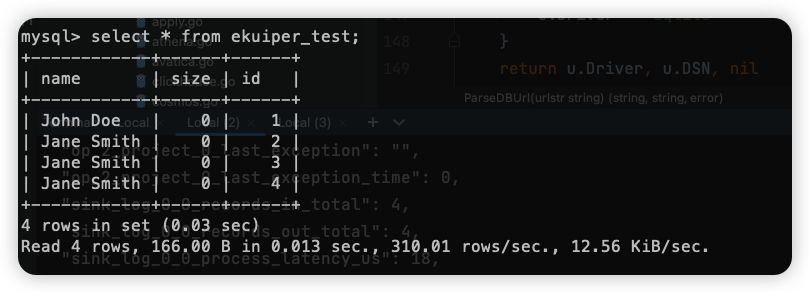
可以看到由于我们的规则 SQL 中只指定了 id, name 字段,所以这里只有这两个字段被写入。
结论
eKuiper 是 EMQ 旗下的一款流处理软件,其体积小、功能强大,在工业物联网、车辆网、公共数据分析等很多场景中得到广泛使用。本文介绍如何使用 eKuiper 将物联网流处理数据写入 Databend。
这篇关于使用 LF Edge eKuiper 将物联网流处理数据写入 Databend的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




