本文主要是介绍格点数据可视化(美国站点的日降雨数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取美国站点的日降雨量的格点数据,并且可视化
导入模块
from datetime import datetime, timedelta
from urllib.request import urlopenimport cartopy.crs as ccrs
import cartopy.feature as cfeature
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
from metpy.units import masked_array, units
from netCDF4 import Dataset
读取数据
nc = Dataset('20200309_conus.nc')
prcpvar = nc.variables['observation']
data = masked_array(prcpvar[:], units(prcpvar.units.lower())).to('mm')
x = nc.variables['x'][:]
y = nc.variables['y'][:]
proj_var = nc.variables[prcpvar.grid_mapping]
设置投影
globe = ccrs.Globe(semimajor_axis=proj_var.earth_radius)
proj = ccrs.Stereographic(central_latitude=90.0,central_longitude=proj_var.straight_vertical_longitude_from_pole,true_scale_latitude=proj_var.standard_parallel, globe=globe)
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1, projection=proj)# 绘制海岸线、国界线、州界线
ax.coastlines()
ax.add_feature(cfeature.BORDERS)
ax.add_feature(cfeature.STATES)# 设置降雨量等级间隔
clevs = [0, 1, 2.5, 5, 7.5, 10, 15, 20, 30, 40,50, 70, 100, 150, 200, 250, 300, 400, 500, 600, 750]
# In future MetPy
# norm, cmap = ctables.registry.get_with_boundaries('precipitation', clevs)
# 单独设置cmap
cmap_data = [(1.0, 1.0, 1.0),(0.3137255012989044, 0.8156862854957581, 0.8156862854957581),(0.0, 1.0, 1.0),(0.0, 0.8784313797950745, 0.501960813999176),(0.0, 0.7529411911964417, 0.0),(0.501960813999176, 0.8784313797950745, 0.0),(1.0, 1.0, 0.0),(1.0, 0.6274510025978088, 0.0),(1.0, 0.0, 0.0),(1.0, 0.125490203499794, 0.501960813999176),(0.9411764740943909, 0.250980406999588, 1.0),(0.501960813999176, 0.125490203499794, 1.0),(0.250980406999588, 0.250980406999588, 1.0),(0.125490203499794, 0.125490203499794, 0.501960813999176),(0.125490203499794, 0.125490203499794, 0.125490203499794),(0.501960813999176, 0.501960813999176, 0.501960813999176),(0.8784313797950745, 0.8784313797950745, 0.8784313797950745),(0.9333333373069763, 0.8313725590705872, 0.7372549176216125),(0.8549019694328308, 0.6509804129600525, 0.47058823704719543),(0.6274510025978088, 0.42352941632270813, 0.23529411852359772),(0.4000000059604645, 0.20000000298023224, 0.0)]cmap = mcolors.ListedColormap(cmap_data, 'precipitation')
norm = mcolors.BoundaryNorm(clevs, cmap.N)cs = ax.contourf(x, y, data, clevs, cmap=cmap, norm=norm)# 添加colorbar
cbar = plt.colorbar(cs, orientation='horizontal')
cbar.set_label(data.units)
# 设置标题
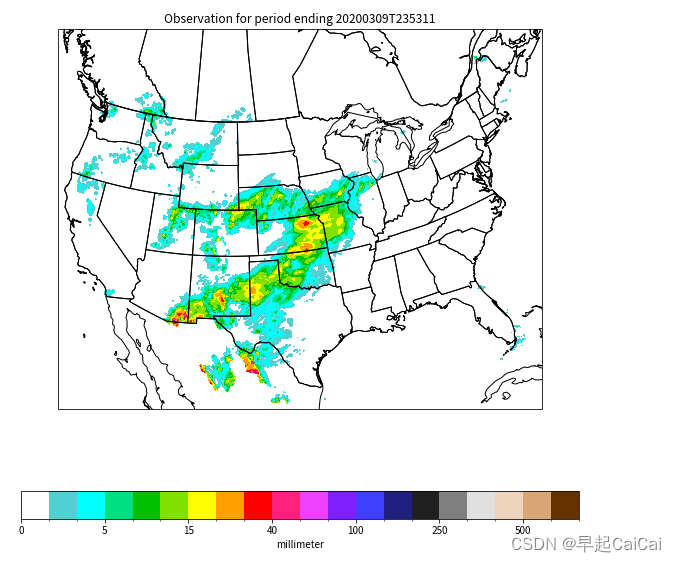
ax.set_title(prcpvar.long_name + ' for period ending ' + nc.creation_time)
plt.show()
数据怎样获取
dt = datetime.utcnow() - timedelta(days=1) # 获取过去1天的时间
url = ('http://water.weather.gov/precip/downloads/{dt:%Y/%m/%d}/nws_precip_1day_''{dt:%Y%m%d}_conus.nc'.format(dt=dt))
data = urlopen(url).read()
nc = Dataset('data', memory=data)
显示数据
import xarray as xr
from xarray.backends import NetCDF4DataStore
data = xr.open_dataset(NetCDF4DataStore(nc))
data
保存为nc数据
data.to_netcdf('{dt:%Y%m%d}_conus.nc'.format(dt=dt),'w')
这篇关于格点数据可视化(美国站点的日降雨数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





