本文主要是介绍烧脑的内存序Memory Order,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列服务器开发
文章目录
- 系列服务器开发
- 前言
- 一、Memory Order是什么?
- 二、使用步骤
- 1.memory_order_relaxed
- 2.memory_order_acquire 和memory_order_release
- 3.memory_order_consume
- 4.memory_order_acq_rel
- 5.memory_order_seq_cst
- 总结
前言
本文是讲解C++内存序,现代cpu架构如下:
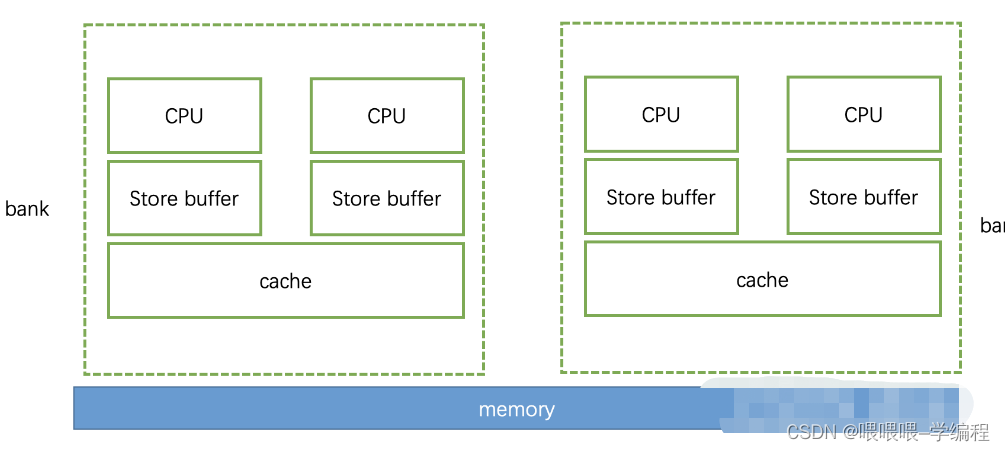
上述提供了一个粗略的现代CPU架构,上述中CPU标注的块,代表着一个Core,此处说明一下。
在上述4core系统中,每两个core构成一个bank,并共享一个cache,且每个core均有一个store buffer。
在多线程编程中经常需要在不同线程之间共享一些变量,然而对于共享变量操作却经常造成一些莫名奇妙的错误,除非老老实实加锁对访问保护,否则经常出现一些(看起来)匪夷所思的情况。
乱序执行技术是处理器为提高运算速度而做出违背代码原有顺序的优化.
内存乱序访问一般分为两种:编译乱序和执行乱序。
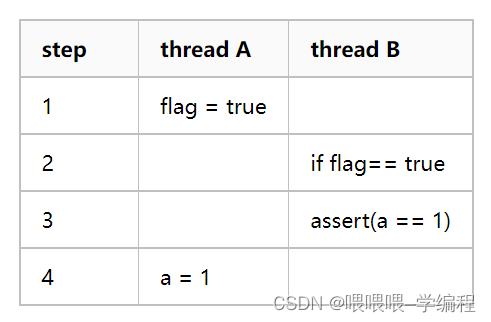
指令重排问题
int a = 0;
bool flag=false;
void thread1()
{a = 1;flag=true;
}void thread2()
{if (flag == true){assert(a == 1);}
}
我们期待的执行顺序,

实际可能产生的内存顺序,这种重排有可能会导致一个线程内相互之间不存在依赖关系的指令交换执行顺序,以获得更高的执行效率。
解决办法:
一个比较稳妥的办法就是对于共享变量的访问进行加锁,加锁可以保证对临界区的互斥访问、如果觉得加锁操作过重太麻烦而不想加锁呢?C++11提供了一些原子变量与原子操作来支持。请学习下面章节。
什么时候用内存屏障
编译器开发者和cpu厂商都遵守着内存乱序的基本原则,简单归纳如下:
(1)不能改变单线程程序的执行行为 ,即单线程程序总是满足Program Order(所见即所得)。在此原则指导下,写单线程代码的程序员不需要关心内存乱序的问题。
(2)在多线程编程中,由于使用互斥量,信号量和事件都在设计的时候都阻止了它们调用点中的内存乱序(已经隐式包含各种内存屏障),内存乱序的问题同样不需要考虑了。
(3)只有当使用无锁(lock-free)技术时,即内存在线程间共享而没有任何的互斥量,内存乱序的效果才会显露无疑,这样我们才需要考虑在合适的地方加入合适的memery barrier。或者你希望编写诸如无锁数据结构,那么内存屏障还是很有用的。
CPU内存乱序访问发生的原因
(1)编译优化,指令重排导致乱序
由于编译器在编译代码时不感知多线程并发执行情况。所以,编译器对代码的优化是基于单线程执行情况,优化的结果就是导致多线程执行环境下CPU内存访问乱序问题。
(2)CPU运行,指令执行乱序
多核CPU并发执行,访问乱序。
在单核CPU 上,不考虑编译器优化导致乱序的前提下,多线程执行不存在内存乱序访问的问题。
一、Memory Order是什么?
内存顺序描述了计算机 CPU 获取内存的顺序,内存的排序既可能发生在编译器编译期间,也可能发生在 CPU 指令执行期间。
为了尽可能地提高计算机资源利用率和性能,编译器会对代码进行重新排序, CPU 会对指令进行重新排序、延缓执行、各种缓存等等,以达到更好的执行效果。当然,任何排序都不能违背代码本身所表达的意义,并且在单线程情况下,通常不会有任何问题。当然这些乱序指令都是为了同一个目的,优化执行效率。happens-before:按照程序的代码序执行。
但是在多线程环境下,比如无锁(lock-free)数据结构的设计中,指令的乱序执行会造成无法预测的行为。所以我们通常引入内存栅栏(Memory Barrier)这一概念来解决可能存在的并发问题。
这里解释下两个词的含义:
happens-before:按照程序的代码序执行
synchronized-with:不同线程间,对于同一个原子操作,需要同步关系,store操作一定要先于 load,也就是说 对于一个原子变量x,先写x,然后读x是一个同步的操作,读x并不会读取之前的值,而是写x后的值。
Memory Barrier
内存栅栏是一个令 CPU 或编译器在内存操作上限制内存操作顺序的指令,通常意味着在 barrier 之前的指令一定在 barrier 之后的指令之前执行。
在 C11/C++11 中,引入了六种不同的 memory order,可以让程序员在并发编程中根据自己需求尽可能降低同步的粒度,以获得更好的程序性能。
relaxed, acquire, release, consume, acq_rel, seq_cst
std::memory_order_relaxed(__ATOMIC_RELAXED)
std::memory_order_acquire (__ATOMIC_ACQUIRE)
std::memory_order_release (__ATOMIC_RELEASE)
std::memory_order_acq_rel (__ATOMIC_ACQ_REL)
std::memory_order_consume(__ATOMIC_CONSUME)
std::memory_order_seq_cst (__ATOMIC_SEQ_CST)
6种memory_order 主要分成3类:
relaxed(松弛的内存序):没有顺序一致性的要求,也就是说同一个线程的原子操作还是按照happens-before关系,但不同线程间的执行关系是任意。
sequential_consistency(内存一致序)
这个是以牺牲优化效率,来保证指令的顺序一致执行,相当于不打开编译器优化指令,按照正常的指令序执行(happens-before),多线程各原子操作也会Synchronized-with,(譬如atomic::load()需要等待atomic::store()写下元素才能读取,同步过程),当然这里还必须得保证一致性,读操作需要在“一个写操作对所有处理器可见”的时候才能读,适用于基于缓存的体系结构。
acquire-release(获取-释放一致性)
这个是对relaxed的加强,relax序由于无法限制多线程间的排序,所以引入synchronized-with,但并不一定意味着,统一的操作顺序
二、使用步骤
1.memory_order_relaxed
不对执行顺序做保证,没有happens-before的约束,编译器和处理器可以对memory access做任何的reorder,这种模式下能做的唯一保证,就是一旦线程读到了变量var的最新值,那么这个线程将再也见不到var修改之前的值了。
假设线程t1运行在CPU1,线程t2运行在CPU3,std::memory_order_relaxed在此处可以理解为仅仅保持原子性,没有其他的作用。因此线程1虽然更新x,y为true,但由于无法保证 两者都同时对其他CPU可见(每个CPU可能在任何时刻将其store buffer中的值写入cache或者memory,此时才有机会被其他CPU看见)。
因此上述可能存在如下执行顺序:
标记1标记2,x为true,y为true,CPU1将y写入cache或者memory,CPU3可以看见改值
标记3执行,y为true,标记4执行,cache中的x为false,z为0
void write_x_then_y() {x.store(true, std::memory_order_relaxed); // 1y.store(true, std::memory_order_relaxed); // 2
}
void read_y_then_x() {while (!y.load(std::memory_order_relaxed)) { // 3}if (x.load(std::memory_order_relaxed)) { //4++z;}
}
2.memory_order_acquire 和memory_order_release
memory_order_acquire保证本线程中,所有后续的读操作必须在本条原子操作完成后执行。memory_order_release保证本线程中,所有之前的写操作完成后才能执行本条原子操作。
acquire/release与顺序一致性内存序相比是更宽松的内存序模型,其不具有全局序,性能更高。核心是:同一个原子变量的release操作同步于一个acquire操作.。
通常的做法是:将资源通过store+memory_order_release的方式”Release”给别的线程;别的线程则通过load+memory_order_acquire判断或者等待某个资源,一旦满足某个条件后就可以安全的“Acquire”消费这些资源了。即释放获得顺序。
由于write_x和write_y是在不同的线程,所以x,y变量之间的store操作没有order限制,这会导致出现如下可能
1、线程c看见x为true, y仍然为false
2、线程d看见y为true,x仍然为false
故会导致z为0
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {x.store(true, std::memory_order_release);
}
void write_y() {y.store(true, std::memory_order_release);
}
void read_x_then_y() {while (!x.load(std::memory_order_acquire));if (y.load(std::memory_order_acquire)) {++z;}
}
void read_y_then_x() {while (!y.load(std::memory_order_acquire));if (x.load(std::memory_order_acquire)) {++z;}
}
由于acquire/release语义,对原子变量y进行了release的store操作,因此y变量之前的store/load操作不能排序到y之后,故在线程a中,y为true时,x一定为true。
由于acquire/release语义,对原子变量y进行acquire的load操作,因此变量y之后的store/load操作不能排序到y之前,故在线程b中,y为true时,x一定为true,此时z为1
std::atomic<bool> x, y;
std::atomic<int> z;void write_x_then_y() {x.store(true, std::memory_order_relaxed);y.store(true, std::memory_order_release);
}void read_y_then_x() {while (!y.load(std::memory_order_acquire));if (x.load(std::memory_order_relaxed)) {++z;}
}
3.memory_order_consume
这个内存屏障与memory_order_acquire的功能相似,而且大多数编译器并没有实现这个屏障,而且正在修订中,暂时不鼓励使用 memory_order_consume 。
std::memory_order_consume具有弱的同步和内存序限制,即不会像std::memory_order_release产生同步与关系。
由于std::memory_order_consume具有弱的同步关系,因此无法保证a的值为99,仅能保证x的值,所以可能触发断言。
struct X {int i_;std::string s_;
};std::atomic<int> a;
std::atomic<X*> p;void create_x() {X* x = new X;x->i_ = 42;x->s_ = "hello";a.store(99, std::memory_order_relaxed);p.store(x, std::memory_order_release);
}void use_x() {X* x;while (!(x = p.load(std::memory_order_consume)));assert(x->i_ == 42);assert(x->s_ == "hello");assert(a.load(std::memory_order_relaxed) == 99);
}
4.memory_order_acq_rel
双向读写内存屏障,相当于结合了memory_order_release、memory_order_acquire。可以看见其他线程施加 release 语义的所有写入,同时自己的 release 结束后所有写入对其他施加 acquire 语义的线程可见
表示线程中此屏障之前的的读写指令不能重排到屏障之后,屏障之后的读写指令也不能重排到屏障之前。此时需要不同线程都是用同一个原子变量,且都是用memory_order_acq_rel
5.memory_order_seq_cst
通常情况下,默认使用 memory_order_seq_cst
如果是读取就是 acquire 语义,如果是写入就是 release 语义,如果是读取+写入就是 acquire-release 语义
同时会对所有使用此 memory order 的原子操作进行同步,所有线程看到的内存操作的顺序都是一样的,就像单个线程在执行所有线程的指令一样。
如果std::memory_order_seq_cst 同时存在store(写)和load(读)那么顺序一致性模型,保证写必须在读之前发生,因此当x先store后,如果y = false 那么顺序一致性保证 x.store->x.load ->y.load->y.store->y.load
无论选择何种执行顺序,顺序一致性均保证所有线程的执行语句全局一致,不会存在重排。
std::atomic<bool> x, y;
std::atomic<int> z;void write_x() {x.store(true, std::memory_order_seq_cst);
}void write_y() {y.store(true, std::memory_order_seq_cst);
}void read_x_then_y() {while (!x.load(std::memory_order_seq_cst)) {}if (y.load(std::memory_order_seq_cst)) {++z;}
}void read_y_then_x() {while (!y.load(std::memory_order_seq_cst));if (x.load(std::memory_order_seq_cst)) {++z;}
}
总结
以上就是今天要讲的内容,本文仅仅简单介绍了内存徐的使用,希望你有所启发。
这篇关于烧脑的内存序Memory Order的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





