本文主要是介绍pytorch nn.utils.rnn.pack_padded_sequence 分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pack_padded_sequence
在nlp模型的forward方法中,可能有以下调用令读者疑惑
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths, batch_first=True, enforce_sorted=False)
为什么要使用pack_padded_sequence?
参考
- Pytorch中的RNN之pack_padded_sequence()和pad_packed_sequence()
- Pytorch中pack_padded_sequence和pad_packed_sequence的理解
当我们训练RNN时,如果想要进行批次化训练,由于句子的长短不一,所以需要截断和填充。
- 为什么要截断?对于那些太长的句子,一般选择一个合适的长度来进行截断。
- 为什么要填充?对于那些太短的句子,需要以 填充字符(比如
<pad>)填充,使得该批次内所有的句子长度相同。
但是,填充会带来其它问题:
- 增加了计算复杂度。假设一个批次内有2个句子,长度分别为5和2。我们要保证批次内所有的句子长度相同,就需要把长度为2的句子填充为5。这样喂给RNN时,需要计算 2 × 5 = 10 2 \times 5 =10 2×5=10次,而实际真正需要的是 5 + 2 = 7 5+2=7 5+2=7次。
- 得到的结果可能不准确。我们知道RNN取的是最后一个时间步的隐藏状态做为输出,虽然在填充时,一般是以全0的词向量填充,RNN神经元的权重乘以零不会影响最终的输出,但还有偏差 b b b,如果 b ≠ 0 b \neq 0 b=0,还是会影响到最后的输出。
当然这个问题不大,主要是第1个问题,毕竟批次大小很大的时候影响还是不小的。
我们用图解进一步说明这个问题。假设某句子“Yes”只有一个单词,但是填充了多余的pad符号,这样会导致LSTM对它的表示通过了非常多无用的字符,这样得到的句子表示就会有误差

那么我们正确的做法应该是怎么样呢?在上面这个例子,我们想要得到的仅仅是LSTM过完单词"Yes"之后的表示,而不是通过了多个无用的“Pad”得到的表示,如下图:
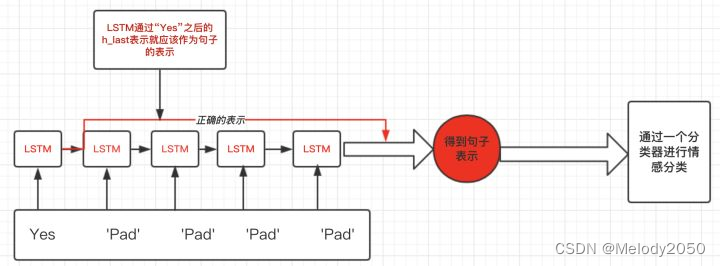
所以,Pytorch提供了pack_padded_sequence方法来压缩填充字符,加快RNN的计算效率。
pack_padded_sequence是如何压缩的?
那么它是如何做压缩的呢?举个例子,假如一个batch里有5个句子,长度分别是5、4、3、3、2、1。将它们按列压缩,在这个过程中删除了pad字符。所以你可以想象这样的训练过程:
- 第一个batch有5个单词,[I, I, This, No, Yes],它们被送入LSTM。
- 第二个batch有4个单词被送入LSTM。
- 以此类推,之后的batch长度逐渐减小,分别是3、3、2、1
在这个过程中,pad字符被自然地忽略掉了。

pack_padded_sequence的参数含义
必备参数是句子向量embedded,以及每个句子长度的变量text_lengths。前者通常包含3个维度,即[批次大小、句子最大长度、单词向量长度](前两者顺序可换);后者通常是list类型,或者一维Tensor类型,包含了每个句子的长度。
batch_first表示输入的向量是batch维度优先的。enforce_sorted代表输入的句子是否已经按照长度顺序排好,如果为False,那么函数估计会先按照长度排好,进行计算,再还原回原来的顺序。
这篇关于pytorch nn.utils.rnn.pack_padded_sequence 分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





