本文主要是介绍超级品牌,都在打造数据飞轮,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
导语
「收钱吧到账15元。」
从北京大栅栏的糖葫芦铺子,到南京夫子庙的鸭血粉丝汤馆,再到广州珠江畔的早茶店,不知不觉间,收钱吧的到账声已经成为不少人一日三餐的前奏——通过收钱吧提供的收款码和硬件设备完成快速、精准收款,正日渐成为国内商户习以为常的经营环节。
正式迈入第十年发展的收钱吧,截至2023年6月最新数据显示,日服务人次已经近5000万,累计服务人次超过500亿次。
惊人的数字背后,是企业数字化能力建设和应用在做支撑。
收钱吧通过自建和与第三方厂商合作等方式,开展自身的数字化建设。在业务应用上,经过多次比较第三方厂商方案后,收钱吧选择和火山引擎数智平台(VeDI)合作,双方将聚焦商户在收钱吧APP内生命旅程洞察、构建统一的消费者和商户标签画像体系,以及针对BD岗位员工负责销售的实时线索推送等场景深度共建。
今年4月,火山引擎重磅推出了企业数智化升级的新范式:数据飞轮,核心突出了数据消费的重要性——以数据消费为核心驱动力,使企业数据流融入业务流,实现数据资产和业务应用的飞轮效应,激发员工创造力,增强业务发展动力,提升组织生命力。
数据消费,亦是收钱吧内部运营的日常。作为生长于互联网科技土壤的企业,数据驱动业务运营已经融入收钱吧的企业基因,不论是项目管理还是运营决策,甚至是商户拓展,几乎每一项工作都涉及到数据消费(比如,查看数据、分析数据、利用数据工具实现决策执行),这也成为收钱吧能高速发展,并最终成为国内领先的数字化门店综合服务商的动力之一。
这一次,我们找到收钱吧,以及火山引擎数智平台(VeDI)聊了聊,看这家“超级品牌”如何用数据推动业务发展,在这个过程中,火山引擎「数据飞轮」又在扮演怎样的角色。
或许,能够给正在数字化实践的企业带来一些思考和参照。
一、几种付款方式,一种收款方式
数以万计的“小生意”承载了大众的日常消费生活,据统计,目前中国有超过7000万的小微商户,他们撑起了60%的中国经济。
但“小生意”背后带出的采购、生产、销售、收款环节却不少,仅在收款环节,一个商家就需要面对现金支付、电子支付方式,其中电子支付又包括支付宝支付、微信支付等多个支付平台形式。对商家来说,如果为每一个电子支付方式都匹配单独的收款码,不但种类繁多容易出错,在结束一天营业之后也难以快速统计当日营业额。
是不是能有一个二维码,能够适配当前市场主流支付平台的付款方式?商家们在想着的时候,收钱吧已经开始尝试。

2013年收钱吧推出了第一个聚合支付收款码,仅凭一张半个手掌大小的二维码,就可以解决商家日常需要应对的多个支付平台收款问题,正式开创国内聚合支付市场的「一站式收款时代」;随后,语音播报、智慧门店小程序、扫码点单、自营外卖、电子小票......收钱吧围绕让消费者付款更便捷、让商家收款更高效两方面,不断丰富服务体系,成为商家的开店生意帮手。
除了聚焦商户核心痛点,不断丰富硬件设备功能之外,收钱吧在通过数据网络构建精细化服务体系上,也下足了功夫。
二、专注收款,不止收款
收钱吧的业务贯穿商户端、消费者端和BD销售端,当庞大的业务数据汇聚到APP,如何高效运用就成了新的课题。
现阶段,收钱吧的数字化建设主要有自建和与第三方厂商共建两大类型,其中自建部分主要集中在数据资产层(底层设施),在业务应用层则倾向于与成熟的第三方厂商展开合作。
在综合评估国内主流厂商的解决方案之后,收钱吧选择了火山引擎数智平台(VeDI),双方聚焦「洞察用户在APP内生命旅程,实现精细化用户运营」开展合作,同时收钱吧也期望火山引擎数智平台能够在提升企业内部管理效率,如BD岗位高效管理商户场景等,提供产品能力支持,真正打造出从数据洞察到数据分析,再到智能运营的一体化解决方案。
收钱吧运用了火山引擎数智平台的哪些产品?
收钱吧技术团队介绍,目前收钱吧已经在使用火山引擎数智平台提供的「DataFinder+VeCDP+GMP」产品组合,涵盖APP用户洞察、日常数据分析,以及BD运营策略下发等多个业务场景,在流程上几乎构建出了面向收钱吧业务层的数据飞轮,在具体应用上:
1、APP用户洞察
通过增长分析平台DataFinder在收钱吧APP中各关键环节完成埋点部署,如老板圈页面发表动态、查看生意账本、店铺收入提现、积分商城兑换等,深度洞察用户在APP内的全生命周期旅程。同时,相关数据可实时沉淀、展现,并依靠DataFinder内置的留存分析、漏斗分析、用户路径分析、归因分析等十余种数据分析模型,支撑收钱吧产品和运营团队优化产品流程、改善用户体验、提升运营效率。

2、标签体系建设
通过客户数据平台VeCDP,收钱吧可以汇聚多源异构数据,并完成标签设计(既可沿用VeCDP自带的标签,也可根据自身需求设计标签)和管理,其中VeCDP的多主体标签功能还能支持收钱吧对商家(老板)、消费者、门店等不同主体构建对应的标签体系,极大满足了收钱吧在不同业务视角下的数据消费。
不久前,收钱吧APP内的核心板块「老板圈」刚完成两周年庆典活动。
老板圈是收钱吧APP提供的商家信息交流平台,来自天南地北的商家可以畅所欲言,从门店选址咨询到爆品经验分享……如今的「老板圈」日活已轻松突破10万,并逐渐成为收钱吧与其他聚合支付平台的差异化优势之一。

除了商家自由发挥,收钱吧也会在「老板圈」上线官方行动,如两周年庆典活动,因为需要涉及到选定活动参与人群、活动信息推送、活动参与数据分析等多项工作,如果依照传统的活动筹备链路,需要拉通多个团队进行协作,收钱吧技术团队表示至少需要筹备7天以上;但在运用「DataFinder+VeCDP」之后,由于用户洞察和标签圈人都能在线化一键实现,即便是运营岗位的员工也能轻松使用数据,这也大大缩短了活动上线的筹备期。
据了解,老板圈两周年庆典活动,在内容、物料设计完成后,只花了1小时便顺利在「老板圈」内完成上线。
3、运营策略触达
在BD岗位员工的工作中,及时唤醒沉睡商户是项重要工作。
收钱吧目前有上万名BD员工负责超过700万的商户关系维护,过去,收钱吧习惯以月度为单位拉取数据复盘非活跃商户,再将非活跃商户数据下发给BD员工,实效性差,且数据复盘、数据下发缺乏高效的数据产品,导致流程较长,BD促活响应速度慢。
但通过「DataFinder+VeCDP+GMP」产品组合的运用,收钱吧首先可以通过DataFinder即时洞察当天APP内的用户活跃情况,并针对非活跃用户完成数据分析及归因,基于客户数据平台VeCDP底层数据的互通性,VeCDP可以直接用DataFinder在APP内洞察到的数据构建用户标签,再通过VeCDP的多主体转换能力,实现「哪些沉睡客户对应到哪个BD」的精准匹配;之后,还可通过火山引擎GMP的智能营销能力实时发送需要加强维护的商户名单给对应的BD员工,加强联系,维护客情。
在收钱吧技术团队看来,与火山引擎数智平台合作的这一年多来,带来的最大改变在于降低了数据消费门槛,提升了数据消费频率。
虽然以前数据消费也频繁,但消费的前提是需要数据开发团队能够将繁杂的数据处理成可以被理解、可以被直接应用的形态,所以业务侧的“数据消费”需要排期等候;但火山引擎数智平台的系列数据产品帮助收钱吧重新构建了数据消费链路,通过产品化的工具,在取得授权条件下,让运营岗位、BD岗位的员工也能轻松使用数据,让“用数”实现了“不用等”,真正做到了数据消费在收钱吧内部的普惠。
让数据普惠,从而让数据消费能够在企业内部真正兴盛起来,也是火山引擎数据飞轮模式转动的原动力。
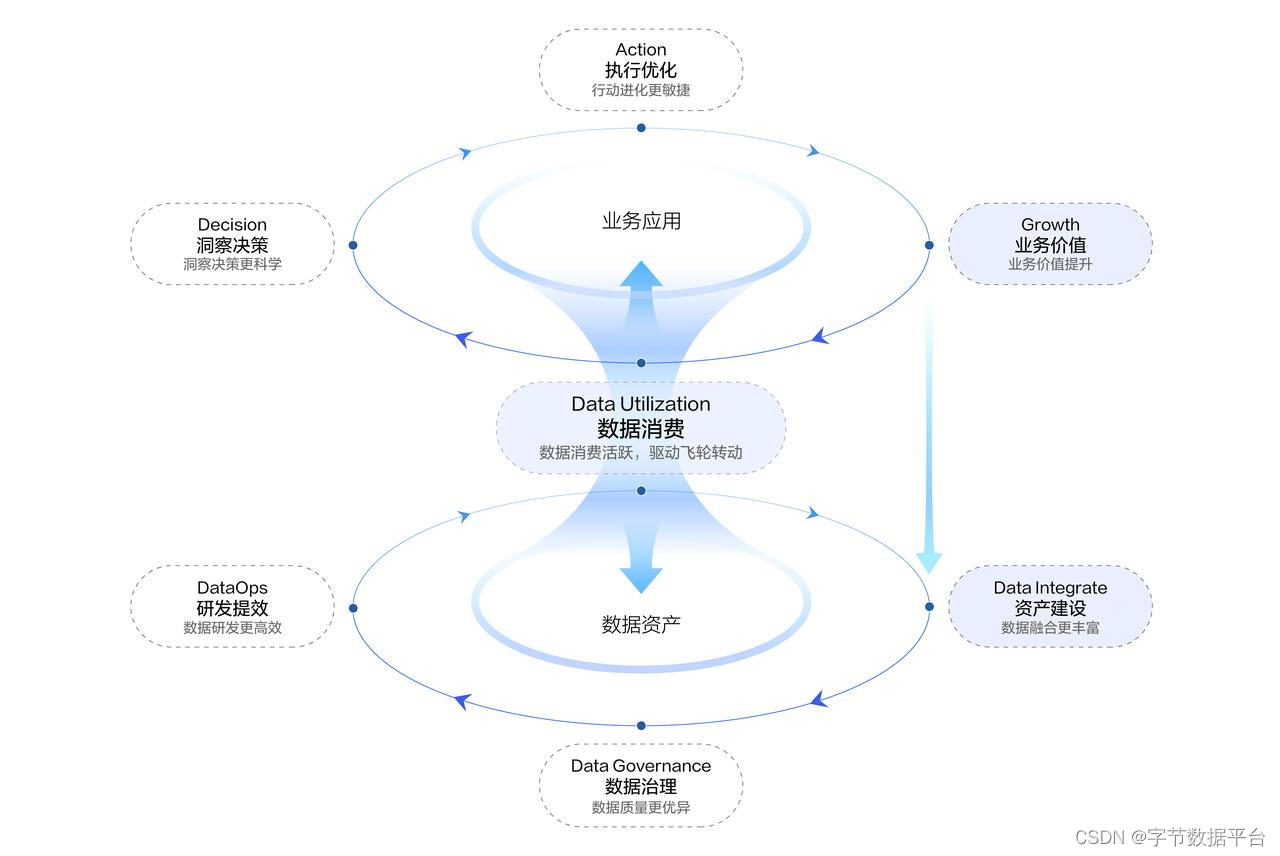
火山引擎数据飞轮模式示意图
从今年4月推出至今,数据飞轮模式已在多个行业进行实践落地,围绕「数据消费」向上(业务应用层)盘活洞察决策、执行优化,助推业务价值提升,形成以数据消费为起点,又流转至数据消费的飞轮闭环;向下(数据资产层)贯穿资产建设、数据治理和研发提效,依旧以数据消费为动力构建环环相扣的飞轮,帮助企业持续「用活数据,提升企业活力」。
从收钱吧现阶段的实践效果来看,不难发现数据飞轮在帮助企业降低数据消费门槛,让企业进一步“会用数”、“用好数”上,有着丰富的经验和标准化的数智产品矩阵;而在数据消费习惯养成之后,企业通过数据飞轮进一步的连带式转动,还能够将储藏在数据系统中的数据力转化成助推业务发展的增长力,真正盘活业务价值,实现业务增长。
这对正在积极寻求数智化升级正确道路的企业来说,是一次机会。
点击跳转火山引擎数智平台VeDI了解更多
这篇关于超级品牌,都在打造数据飞轮的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





