本文主要是介绍实战Kaggle泰坦尼克数据集,玩转Pandas透视表 | 强烈推荐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据透视表(Pivot Table)是常用的数据汇总工具,可以通过控制数据的排列灵活地进行数据分析,进而挖掘出数据中最有价值的信息。掌握数据透视表,已经成为数据分析从业者必备的一项技能。
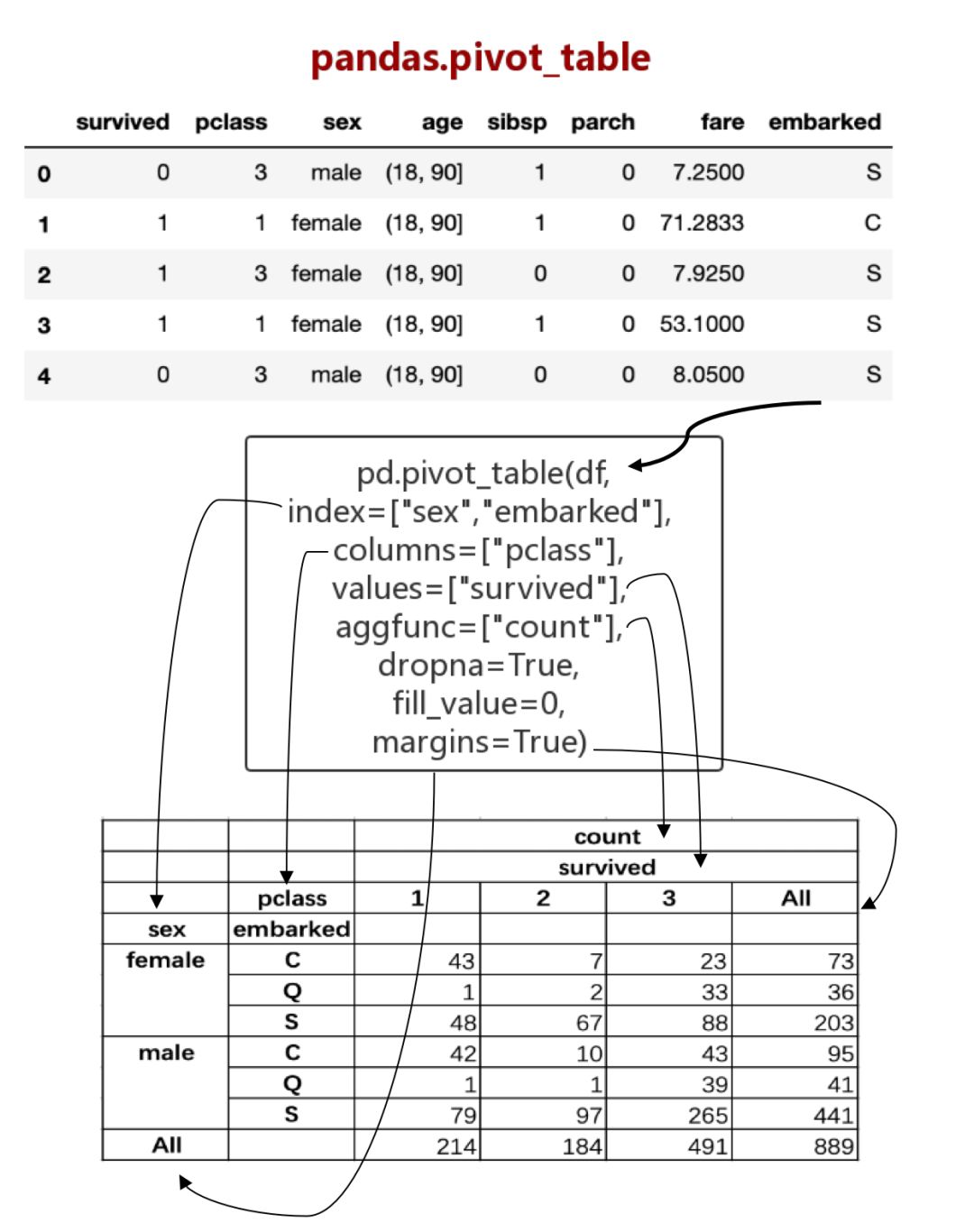
在python中我们可以通过pandas.pivot_table函数来实现数据透视表的功能。本篇文章介绍了pandas.pivot_table具体的使用方法,在最后还准备了一个备忘单,希望能够帮助你记住如何使用pandas的pivot_table。
本文结构
1. 实例数据加载及预处理
本文采用kaggle赛题”泰坦尼克号“中的数据,案例背景是,船要沉了,我们根据各种影响因素,判断船上成员的存活率,比如头等舱的人存活率是不是会更高呢?或者女人比男人活下来的概率更高呢?
# 加载数据
import numpy as np
import pandas as pd
import seaborn as sns
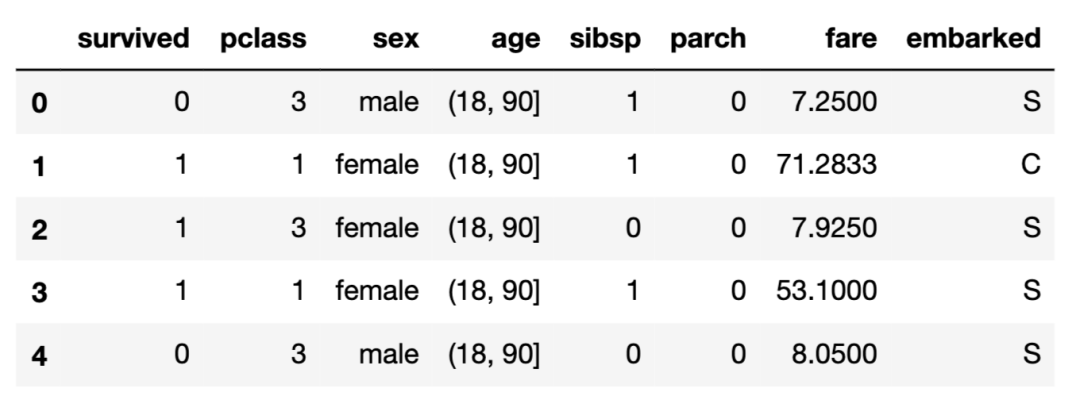
df = sns.load_dataset('titanic')# 删除不重要的列
df.drop(columns =["who","adult_male","deck","embark_town","alive","alone","class"],inplace=True)# 缺失值处理
df = df[df["embarked"].notnull()]
df["age"].fillna(df["age"].mean(),inplace=True)# age离散化
df["age"] = pd.cut(df["age"], [0, 18, 90])df.head()
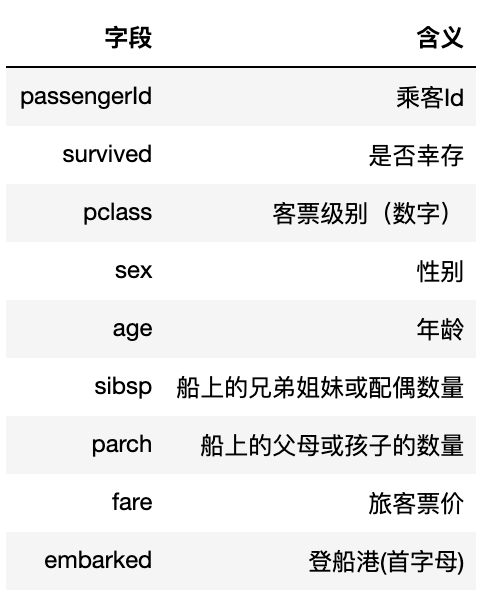
主要字段的含义如下:
2. 第一个透视表
# 查看不同性别的存活率
table = pd.pivot_table(df, index=["sex"], values="survived")
print(table)
survived
sex
female 0.740385
male 0.188908
可见女性的存活率很高,说明当时船上的男人们还是很绅士的哈哈~~
参数说明:
df是要传入的数据;
index是 Values to group by in the rows,也就是透视表建立时要根据哪些字段进行分组,我们这里只依据性别分组;
values是指对哪些字段进行聚合操作,因为我们只关心不同性别下的存活率情况,所以values只需要传入一个值"survived";
将所有乘客按性别分为男、女两组后,对"survived"字段开始进行聚合,默认的聚合函数是"mean",也就是求每个性别组下所有成员的"survived"的均值,即可分别求出男女两组各自的平均存活率。
3. 添加列索引
# 添加一个列级分组索引:pclass-客票级别,共有1,2,3三个级别,1级别最高。
table = pd.pivot_table(df, index=["sex"], columns=["pclass"], values="survived")
print(table)
pclass 1 2 3
sex
female 0.967391 0.921053 0.500000
male 0.368852 0.157407 0.135447
可以发现,无论是男性还是女性,客票级别越高的,存活率越高。
4. 多级行索引
# 添加一个行级分组索引:pclass-客票级别
table = pd.pivot_table(df, index=["sex","pclass"], values="survived")
print(table)
survived
sex pclass
female 1 0.9673912 0.9210533 0.500000
male 1 0.3688522 0.1574073 0.135447
添加一个行级索引"pclass"后,现在透视表具有二层行级索引,一层列级索引。仔细观察透视表发现,与上面【3】中的"添加一个列级索引",在分组聚合效果上是一样的,都是将每个性别组中的成员再次按照客票级别划分为3个小组。
不同点就在于,看你是想让表格的行数多一点,还是想让列数多一点~~
5. 多级列索引
# 构造两层列级索引:"pclass"和"age"
table = pd.pivot_table(df, index=["sex"], columns=["pclass","age"], values="survived")
print(table)
pclass 1 2 3
age (0, 18] (18, 90] (0, 18] (18, 90] (0, 18] (18, 90]
sex
female 0.909091 0.975309 1.0 0.903226 0.511628 0.495050
male 0.800000 0.350427 0.6 0.086022 0.215686 0.121622
添加两层列级索引后,分析透视表,可以发现,一级客票的成年女性存活率高达97.5%,存活率最低的是三级客票的未成年男孩。
当然,行索引和列索引都可以再设置为多层,不过,行索引和列索引在本质上是一样的,大家需要根据实际情况合理布局。
6. 添加多个聚合列
# 按客票级别分组,每组对两个列进行聚合:“是否存活”和“船票价”
table = pd.pivot_table(df, index=["pclass"], values=["survived","fare"])
print(table)
fare survived
pclass
1 84.193516 0.626168
2 20.662183 0.472826
3 13.675550 0.242363
可以发现,船票级别越高,票价越高,存活率也越高。。。
需要注意的是,如果不传入values参数,将对除index和columns之外的所有剩余列进行聚合。
# 不传入values参数,剩余的所有列均做聚合(默认是均值聚合)。
table = pd.pivot_table(df, index=["pclass"])
print(table)
# 因为没有指定聚合函数,离散列又不能求均值,因此离散列在下面不会列出。
fare parch sibsp survived
pclass
1 84.193516 0.359813 0.420561 0.626168
2 20.662183 0.380435 0.402174 0.472826
3 13.675550 0.393075 0.615071 0.242363
7. 自定义聚合函数
# 指定聚合函数
table = pd.pivot_table(df, index=["pclass"], values=["survived", "fare"], aggfunc=["mean", sum, "count"])
print(table)
mean sum count fare survived fare survived fare survived
pclass
1 84.193516 0.626168 18017.4125 134 214 214
2 20.662183 0.472826 3801.8417 87 184 184
3 13.675550 0.242363 6714.6951 119 491 491
聚合函数支持常见的统计函数,如"mean", "sum", count, np.mean, np.std, np.corr等,支持字符串等多种格式。
如果传入参数为list,则每个聚合函数对每个列都进行一次聚合。
如果传入参数为dict,则每个列仅对其指定的函数进行聚合,此时values参数可以不传。
示例如下:
# aggfunc传入字典类型,自定义每个列要适用的聚合函数
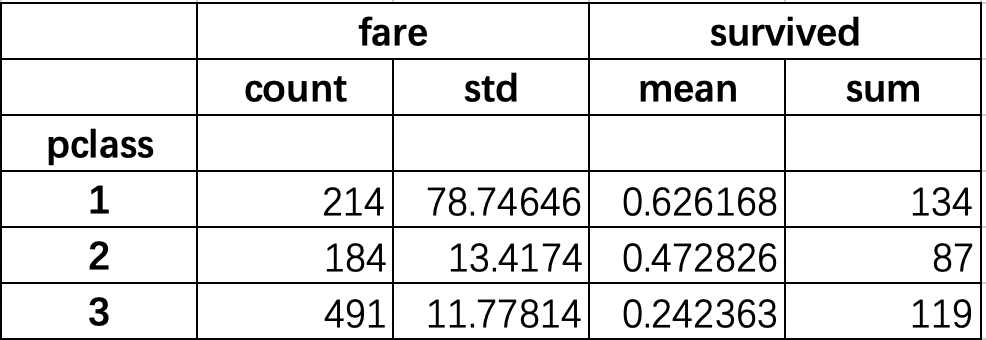
table = pd.pivot_table(df, index=["pclass"], aggfunc={"survived": ["mean", sum], "fare": ["count", np.std]})
print(table)
fare survived count std mean sum
pclass
1 214 78.746457 0.626168 134.0
2 184 13.417399 0.472826 87.0
3 491 11.778142 0.242363 119.0
8. 添加汇总项
# 按行、按列进行汇总,指定汇总列名为“Total”,默认名为“ALL”
table1 = pd.pivot_table(df, index="sex", columns="pclass", values="survived", aggfunc= "count", margins=True, margins_name="Total")
print(table1)
pclass 1 2 3 Total
sex
female 92 76 144 312
male 122 108 347 577
Total 214 184 491 889
9. 保存透视表
数据分析的劳动成果最后当然要保存下来了,我们一般将透视表保存为excel格式的文件,如果需要保存多个透视表,可以添加到多个sheet中进行保存。
save_file = "./titanic_analysis.xlsx"
with pd.ExcelWriter(save_file) as writer: table.to_excel(writer, sheet_name='汇总-演示', encoding="utf-8")table1.to_excel(writer, sheet_name='自定义聚合函数-演示', encoding="utf-8")
excel保存格式如下:
10. 备忘单
为了试图总结所有这一切,本文创建了一个备忘单,希望它能够帮助你记住如何使用pandas的pivot_table。
往
期
回
顾
1一文带你了解人工智能:学科介绍、发展史、三大学派 2《机器学习》西瓜书,17个精炼笔记来了!3Matplotlib绘制六种可视化图表,值得收藏

长按扫码可关注
点个在看![]()
这篇关于实战Kaggle泰坦尼克数据集,玩转Pandas透视表 | 强烈推荐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






