本文主要是介绍阿里专家刘应耀:探索阿里数据藏宝图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

▲2013 Hadoop中国技术峰会
Hadoop中国技术峰会由China Hadoop Summit专家委员会主办,由IT168、ITPUB、ChinaUnix协办,渠达传媒负责承办。本届大会将秉承“效能、应用、创新”为主题,旨在通过开放、广泛的分享和交流,着力于促进中国企业用户提高应用Hadoop的能力和水平,降低Hadoop技术应用门槛和投资预算门槛,推广大数据的应用价值。

▲阿里巴巴高级技术专家刘应耀
在下午的一场分论坛演讲中,来自阿里巴巴高级技术专家刘应耀发表了题为《探索阿里数据藏宝图——数据地图》的主题演讲,其主要介绍了我们面对大数据,应该关注些什么?阿里巴巴有多少数据?是如何进行存储的?数据与数据之间存在什么关系?大数据的未来是什么?
谈到阿里的大数据,刘应耀老师特别强调说,“阿里的数据非常复杂,复杂到集团里没有人可以说清楚,阿里到底有多少数据,我们这些数据都存储在哪里,我们这些数据都有什么价值,又如何来挖掘这些价值。”
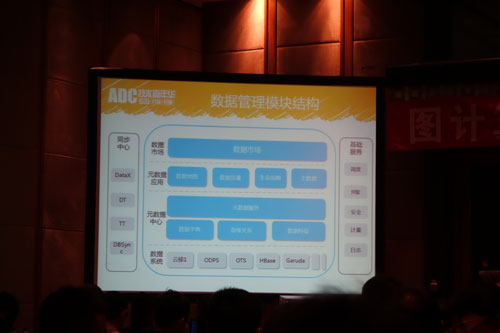
阿里的目标是成为一家数据公司,所以一定要解决一个非常关键的问题,“我们要解决这些数据的存放、管理、关系、以及具体的价值。”为此,阿里进行了一个关于数据管理的项目——数据地图。
在数据地图项目中,阿里使用到了Hadoop,但刘应耀老师表示,Hadoop并不是万能的,尽管它适合做大数据的存储与分析,但当数据的规模到达一定程度的时候,Hadoop会表现出它的瓶颈,包括计算处理、跨集群的问题等等。此外,Hadoop还有一些先天的缺陷,比如安全、对外开放、搭建企业级的平台。

除了Hadoop外,由于阿里数据的复杂性,他们还开发了很多数据系统,比如ODPS、OTS等等,但在这么多数据系统的前提下,如果有效的管理数据,已经成为阿里技术团队所面临的巨大挑战。
从刘应耀老师展示的这张结构图中,我们可以看到,每个数据系统都有一个显著的特征:都有原仓。“那么我们首先就把所有的数据都收集起来,数据系统之间的流动,是通过我们的同步工具——同步中心。这一系列同步工具所产生的数据的流向,我们做了详细的记录。”
同时,像数据处理过程中的一些基础服务,比如调度、预警、数据的安全等级、数据生产的消耗的CPU的IO、数据大量的行为日志等等,把这些全部收集起来,作为数据的特征,再加上数据字典和血缘关系,这样就形成了数据的资源池,元数据中心。阿里的元数据中心提供了一系列的数据服务,包括各种数据应用,其中就包括了数据地图这个项目。
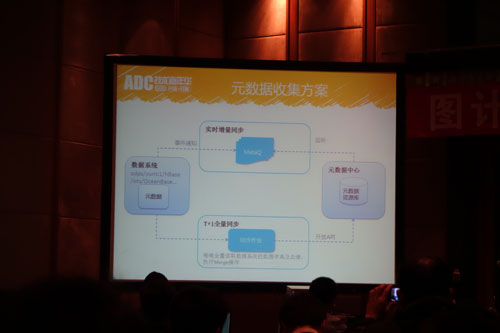
此外,刘应耀还介绍了数据生命周期管理。“大家知道,Hadoop是一个非常灵活的数据系统,当然除此之外还有很多。开放人员在上面做了什么可能只有他自己知道,如果没有一个很好的管理体制,很难产生好的效果。”

数据生命周期管理的作用就在于,来记录数据什么时候产生的、什么时候该用,什么时候销毁,以及解决了根据数据的重要层级,不同的级别的数据采用不同的备份策略。
作者:王晓东
来源:IT168
原文链接:阿里专家刘应耀:探索阿里数据藏宝图
这篇关于阿里专家刘应耀:探索阿里数据藏宝图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





