本文主要是介绍第一张黑洞照片的背后 :数据科学与开放式科研,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相信大家还记得不久前,北京时间4月10日晚9时许,全球观众都激动的守在屏幕前,等待人类史上第一张黑洞的“真容”。照片显示的是位于星系M87中心的黑洞,距离地球约5500万光年。尽管它有太阳的400万倍,但它的距离是如此之远以致于极难观测,在地球上观测这个黑洞,相当于站在纽约去测量一个位于洛杉矶的高尔夫球洞。
现在,热度和兴奋过去了,我们是时候谈谈这张人类有史以来第一张黑洞照片的背后,数据科学和开放式科研到底起到了什么样重要的作用。
EHT是一个专门用于获取黑洞影像的实验项目,通过联合全球多地的8组天文望远镜,构建一个口径等同于地球直径的“虚拟”望远镜,从而收集海量数据,并勾勒出黑洞的模样。
这个科研项目的背后,还藏着另一支神秘的数据团队
黑洞照片和普通拍照不同,为了获取这张照片,需要分布在全球各地的许多天文望远镜在同一时间“按下快门”,收集宇宙中传来的各种无线电数据,包括关于黑洞的数据信息。
本来,根据射电望远镜数据还原天体图像需要人类天文学家完成。然而面对如此大量稀疏、嘈杂的数据,想靠传统的人力方法从中找出图像太难了,但天文学家们自身并没有算法建模和机器学习的能力。于是,他们找到了Katie Bouman所在的算法团队,将装着大量数据的硬盘交给他们,通过机器学习,把数据过滤、筛选并拼到一起,重建出图像。以自己的专业数据知识,为成像算法找到正确的方向。
Katie Bouman 今年29岁,当时她是一名MIT在读的博士,Katie来自计算机科学专业,当时的她对于天文方面一窍不通。即使这样,她还是带领了这只算法团队,成功构建出了这张黑洞照片,也成了第一批“看到”黑洞的人类之一。

开放式数据科学团队合作,渗入各领域科研
黑洞照片的成功洗出,很大程度上得益于数据科学和机器学习技术的发展,但数据科学不仅仅为天文科学提供机会,它为各领域的科研都提供了更大可能。
2017年,就读与University of North Texas 的一名生物学博士Sheela,研究不同治疗方法对生育的影响,她用了好几年的时间,终于采集到了104 个样本,每个样本包括29 个特征变量。但是当她试图采用回归和方差分析的手段,来构造模型时,却发现结果和和原因一点儿显著关系都没有,这几年的心血就要付之东流。
于是Sheela找到了他们学校的一个数据分析团队,叫做DSA数据科学与分析部门(Data Science and Analysis),DSA中的成员对数据进行了整体的分析和,得出了基于决策树的监督学习+遗传算法,然后采用BIC 做模型选择。在得到的图中,几种不同疗法,在不同的条件下,对应的效果差别一目了然,还给出了决策树模型。最后,Sheela 不仅顺利毕业,而且还把论文发在了一份很好的期刊上面。
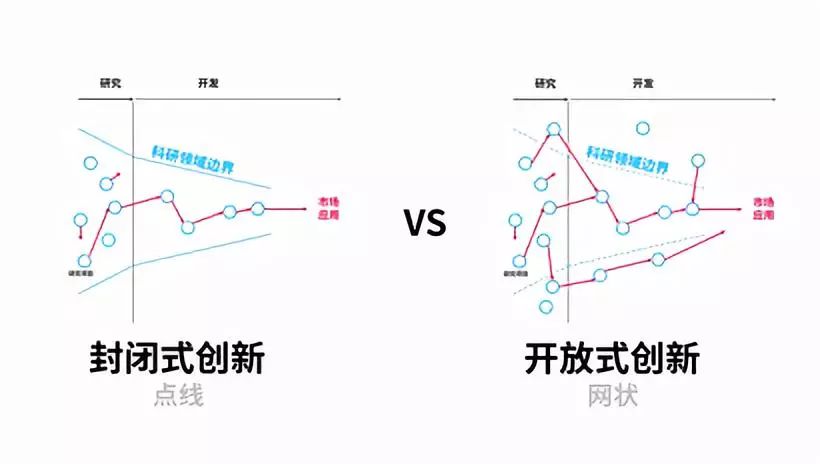
提升科研效率的秘诀,引入外部数据科学力量
Sleena面对的问题,也是是大多数科研人员面临的问题,因为他们已经把自己的全部精力用在了不断追赶自身领域前沿上,并没有余力去提高自己的数据分析技能。
数据科学是专业领域,所以如果能引入科研团队外部专业数据科学家的力量推进自己的科研中的数据分析环节,无疑是科研为科研之路的极大助力,可以让更多人应用数据科学的门槛大幅降低。更可宝贵的,是这种一站式咨询与合作方式,不仅可以帮助有困难的科研团队解决燃眉之急,更有助于形成良性互动循环,使得科研项目做大做强。
数据科学协同研发平台,获得专属的数据科学解决方案
随着数据科学的需求水涨船高,在国外已经诞生了不少数据科学或科研服务众包平台,例如Gigster、Crowdicity、Presants、Numar.AI、Science Exchange等平台,国内有heywhale和鲸社区,上面汇集了一大批数据科学家和数据科学项目。这些平台以众包方式解决科研中数据共享、协同创新等问题,在国外这已经是常态化的方式,国内虽然起步较晚,但也已经被越来越多的高校、科研机构、企业所接受。许多科研团队和企业将自身项目中需要数据科学解决的问题发布在平台上,吸引各领域的专业数据人才,通过协同研发的方式提供解决方案。
中国的数据科学平台和数据科学社区目前还正在快速发展期,HeyWhale和鲸科技是目前国内最大的第三方数据科学协同创新平台,其社区拥有5万多数据科学家用户。今年和鲸社区开放了协同研发版块,致力于帮助人才不足的团队与企业解决数据问题。和鲸协同研发基于高质量的数据AI团队、精细的过程管理规划和强大的算法分析研发工具Kescilab,三大基石为客户服务提供了全面支持,并使用多重手段确保数据安全。
和鲸协作研发业务发布流程非常简洁,首先提出问题及需求,其次准备解决好对应问题的数据集,最后在和鲸社区主页任务上发布即可。和鲸会根据企业的具体需求给出实施方案;待任务发布后,通过算法匹配和多重筛选机制,找到合适人才;精细管理让各团队同时推进,及时知晓进度;交付验收时,基于科学的评测机制,以赛马机制成果选优方案。
在开放协同众包服务后,清华大学的一个历史科研团队将自己的数据分析项目发布在和鲸平台上,短时间内便有数支擅长数据分析的队伍参与,为该提供了数据分析方案,迅速推进了科研项目进度。目前,和鲸协同研发已经服务了来自清华大学、上海交通大学等顶级高校的科研团队。
当技术发展到今天,协同创新平台在科研中扮演越来越重要的作用。在像和鲸这样的平台上,科研工作者一方面可以继续在“孤单”中埋头苦干、精耕细作;另一方面也可以和全球的同行联合开展研究项目,共同推动科研成果与市场的对接。
在社交网络的丛林中,科研社交与众包平台就像一块远离喧嚣的宝地,聚集着来自全球的科研人员,交流学术成果、协作科学研究,并共同与市场建立起更紧密的联系。科学研究是一项具有鲜明双重属性的活动:一方面,科研工作者需要高度专注、耐得住寂寞与孤单,哪怕一辈子只发现了一种化学元素,一辈子只解答了一个科学猜想;另一方面,即使有保密和竞争需要,科研工作者仍然离不开跨国界、跨科学的交流。高质量的碰撞、沟通与协同,会产生更美丽的火花,甚至跨时代的发现与发明。

「END」
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于第一张黑洞照片的背后 :数据科学与开放式科研的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





