本文主要是介绍HBase海量数据入仓实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、方案背景
现阶段部分业务数据存储在HBase中,这部分数据体量较大,达到数十亿。大数据需要增量同步这部分业务数据到数据仓库中,进行离线分析,目前主要的同步方式是通过HBase的hive映射表来实现的。该种方式具有以下痛点:
-
需要对HBase表进行全表扫描,对HBase库有一定压力,同步数据同步速度慢。
-
业务方对HBase表字段变更之后,需要重建hive映射表,给权限维护带来一定的困难。
-
业务方对HBase表字段的变更无法得到有效监控,无法及时感知字段的新增,对数仓的维护带来一定的困难。
-
业务方更新数据时未更新时间戳,导致通过时间戳字段增量抽取时数据缺失。
-
业务方对表字段的更新新增无法及时感知,导致字段不全需要回溯数据。
基于以上背景,对HBase数据增量同步到数仓的场景,给出了通用的解决方案,解决了以上这些痛点。
二、方案简述
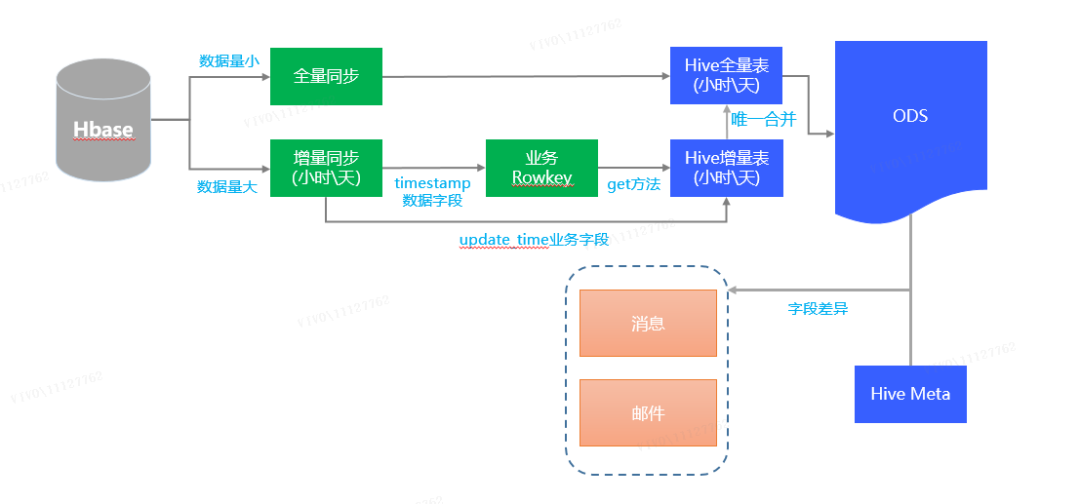
2.1 数据入仓构建流程
2.2 HBase数据入仓方案实验对比

分别对以上三种实现方案进行合理性分析。
2.2.1 方案一
使用HBase的hive映射表。此种方案实现方式简单,但是不符合数仓的实现机制,主要原因有:
-
HBase表虽然是Hadoop生态体系的NoSQL数据库,但是其作为业务方的数据库,直接通过hive映射表读取,就类比于直接读取业务方Mysql中的视图,可能会对业务方数据库造成一定压力,甚至会影响业务的正常运行,违反数仓尽可能低的影响业务运行原则。
-
通过hive映射表的方式,从实现方式上来讲,增加了与业务方的耦合度,违反数仓建设解耦原则。
所以此种方案在此实际应用场景中,是不应该采取的方案。
2.2.2 方案二
根据业务表中的时间戳字段,抓取增量数据。由于HBase是基于rowKey的NoSQL数据库,所以会存在以下几个问题:
-
需要通过Scan全表,然后根据时间戳(updateTime)过滤出当天的增量,当数据量达到千万甚至亿级时,这种执行效率就很低,运行时长很长。
-
由于HBase表更新数据时,不像MySQL一样,能自动更新时间戳,会导致业务方没有及时更新时间戳,那么在增量抽取数据的时候,会造成数据缺失的情况。
所以此种方案存在一定的风险。
2.2.3 方案三
根据HBase的timeRange特性(HBase写入数据的时候会记录时间戳,使用的是服务器时间),首先过滤出增量的rowKey,然后根据这些rowKey去HBase查询对应的数据。这种实现方案同时解决了方案一、方案二的问题。同时,能够有效监控业务方对HBase表字段的新增情况,避免业务方未及时通知而导致的数据缺失问题,能够最大限度的减少数据回溯的频率。
综上,采用方案三作为实现HBase海量数据入仓的解决方案。
2.3 方案选择及实现原理
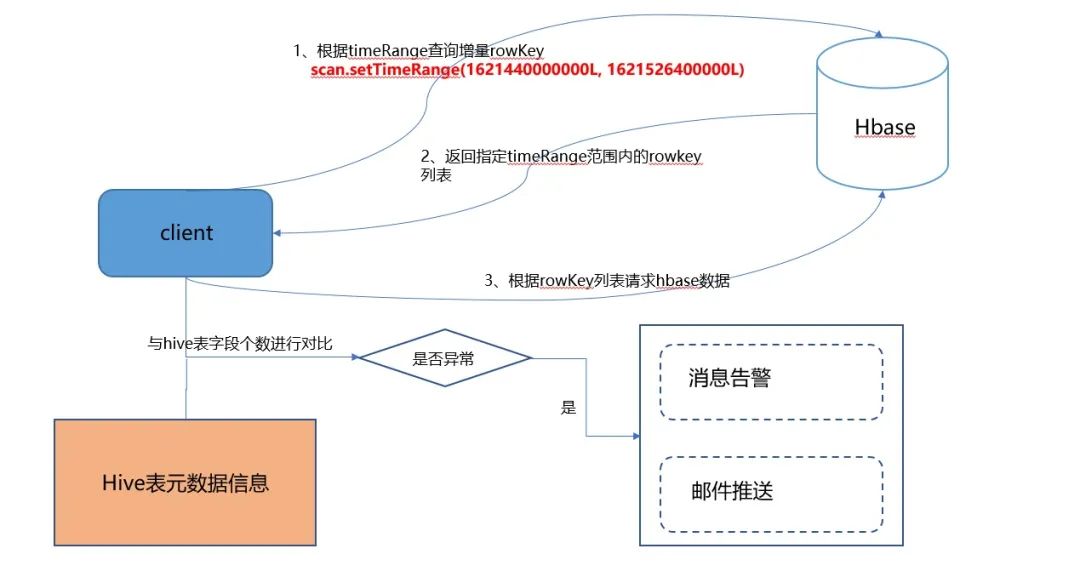
基于HBase数据写入时会更新TimeRange的特性,scan的时候如果指定TimeRange,那么就不需要扫描全表,直接根据TimeRange获取到对应的rowKey,然后再根据rowKey去get出增量信息,能够实现快速高效的获取增量数据。
为什么scan之后还要再去get呢?主要是因为通过timeRanme出来的数据,只包含这个时间范围内更新的列,而无法查询到这个rowkey对应的所有字段。比如一个rowkey有name,age两个字段,在指定时间范围内只更新了age字段,那么在scan的时候,只能查询出age字段,而无法查询出name字段,所以要再get一次。同时,获取增量数据对应的columns,跟hive表的meta数据进行比对,对字段的变更进行及时预警,减少后续因少同步字段内容而导致全量初始化的情况发生。其实现的原理图如下:
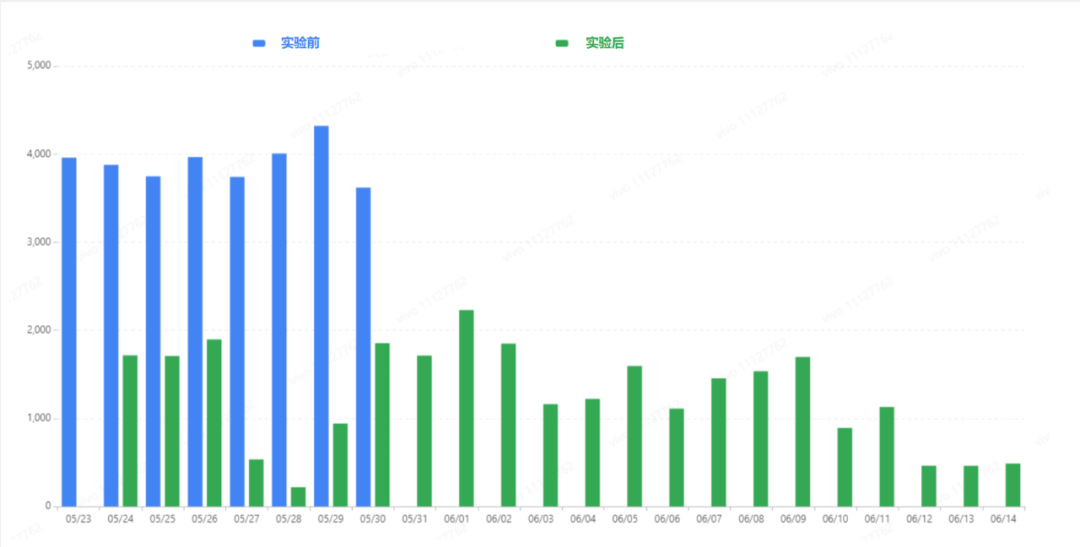
三、效果对比
运行时间对比如下(单位:秒):
四、总结与展望
数据仓库的数据来源于各方业务系统,高效准确的将业务系统的数据同步到数仓,是数仓建设的根本。通过该解决方案,主要解决了数据同步过程中的几大痛点问题,能够较好的保证数据入仓的质量问题,为后续的数仓建设打下一个较好的基础。
另外,通过多次实验对比,及对各种方案的可行性分析,将数据同步方案同步给一站式大数据开发平台,推动大数据开发平台支持基于timeRange的增量同步功能,实现此功能的平台化、配置化,解决了HBase海量数据入仓的痛点。
同时,除了以上这几种解决方案之外,还可以尝试结合Phoenix使用二级索引,然后通过查询Phoenix表的方式同步到数仓,这个将在后期进行性能测试。
这篇关于HBase海量数据入仓实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





