本文主要是介绍python爬取boss直聘数据(selenium+xpath),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、主要目标
- 二、开发环境
- 三、selenium安装和驱动下载
- 四、主要思路
- 五、代码展示和说明
- 1、导入相关库
- 2、启动浏览器
- 3、搜索框定位
- 创建csv文件
- 招聘页面数据解析(XPATH)
- 总代码
- 效果展示
- 六、总结
一、主要目标
以boss直聘为目标网站,主要目的是爬取下图中的所有信息,并将爬取到的数据进行持久化存储。(可以存储到数据库中或进行数据可视化分析用web网页进行展示,这里我就以csv形式存在了本地)

二、开发环境
python3.8
pycharm
Firefox
三、selenium安装和驱动下载
环境安装: pip install selenium
版本对照表(火狐的)
https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
浏览器驱动下载
https://registry.npmmirror.com/binary.html?path=geckodriver/
火狐浏览器下载
https://ftp.mozilla.org/pub/firefox/releases/
四、主要思路
- 利用selenium打开模拟浏览器,访问boss直聘首页(绕过cookie反爬)
- 定位搜索按钮输入某职位,点击搜索
- 在搜索结果页面,解析出现的职位信息,并保存
- 获取多个页面,可以定位跳转至下一页的按钮(但是这个跳转我一直没成功,于是我就将请求url写成了动态的,直接发送一个新的url来代替跳转)
五、代码展示和说明
1、导入相关库
# 用来将爬取到的数据以csv保存到本地
import csv
from time import sleep
# 使用selenium绕过cookie反爬
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
# 使用xpath进行页面数据解析
from lxml import etree2、启动浏览器
(有界面)
# 传入浏览器的驱动
ser = Service('./geckodriver.exe')
# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser)
# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)
# 让浏览器发起一个指定url请求
bro.get(urls[0])
(无界面)
# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])
3、搜索框定位
进入浏览器,按F12进入开发者模式
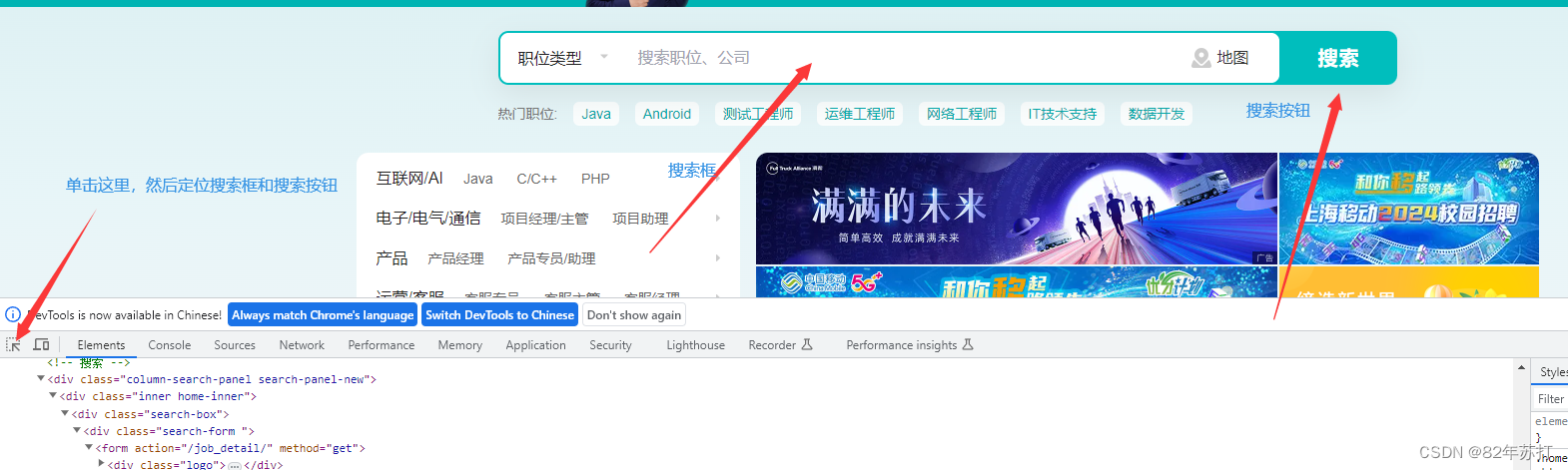
然后分析下图可知,搜索框和搜索按钮都有唯一的class值
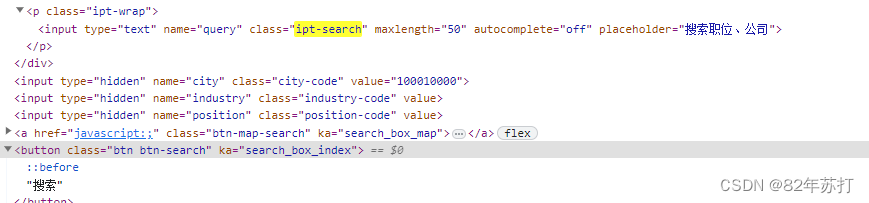
然后输入搜索内容,并跳转,代码如下
# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
创建csv文件
一开始编码为utf-8,但在本地打开内容是乱码,然后改成utf-8_sig就ok了
# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])招聘页面数据解析(XPATH)
通过分析可知,招聘数据全在ul标签下的li标签中
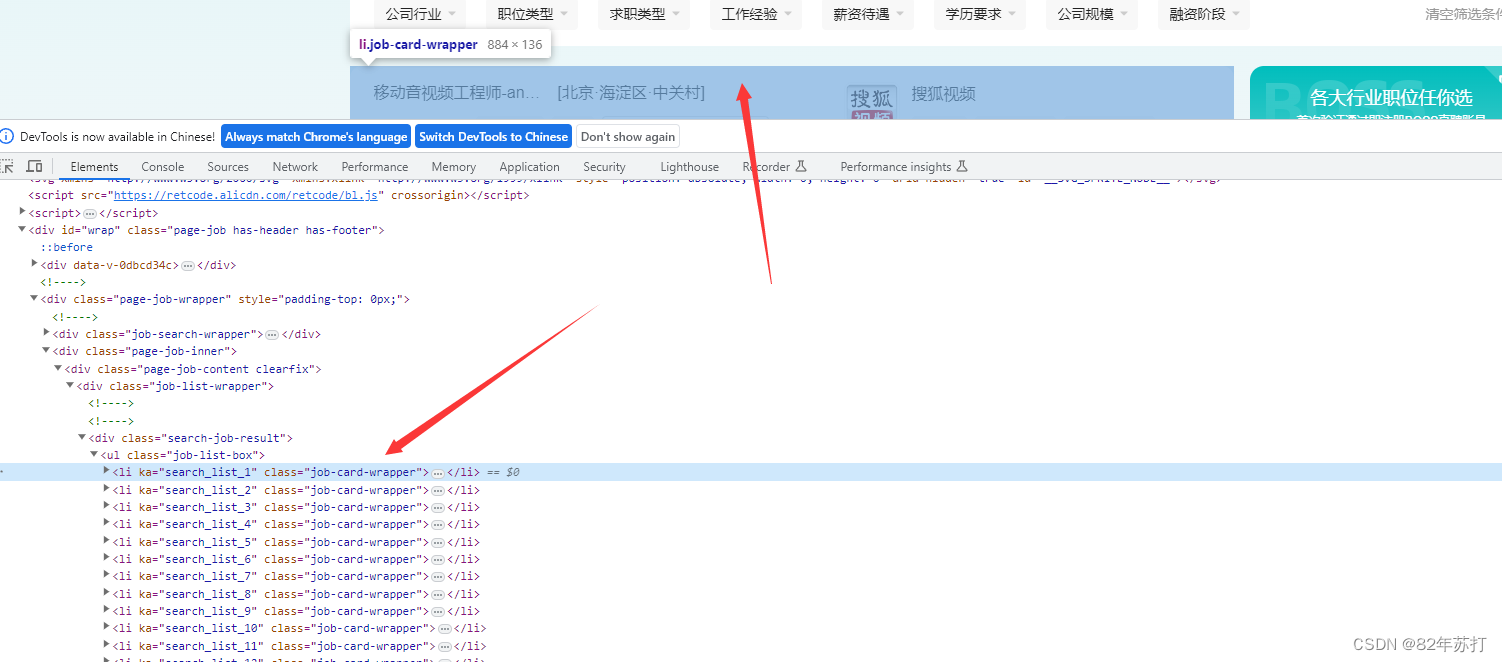
我们要获取的信息有这些,接下来就要进入li标签中,一个一个去分析
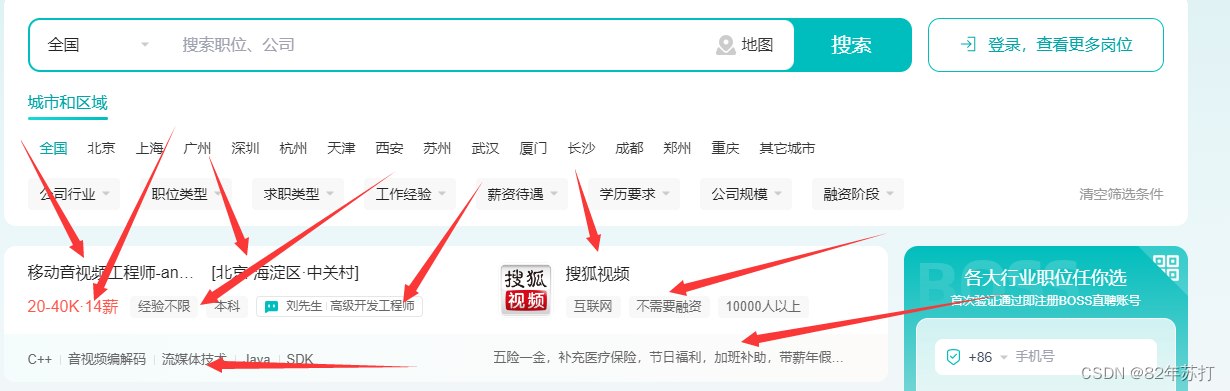
其中职位名称在span标签中,而span标签的class有唯一的值job-name
其它数据分析方式和这个相同
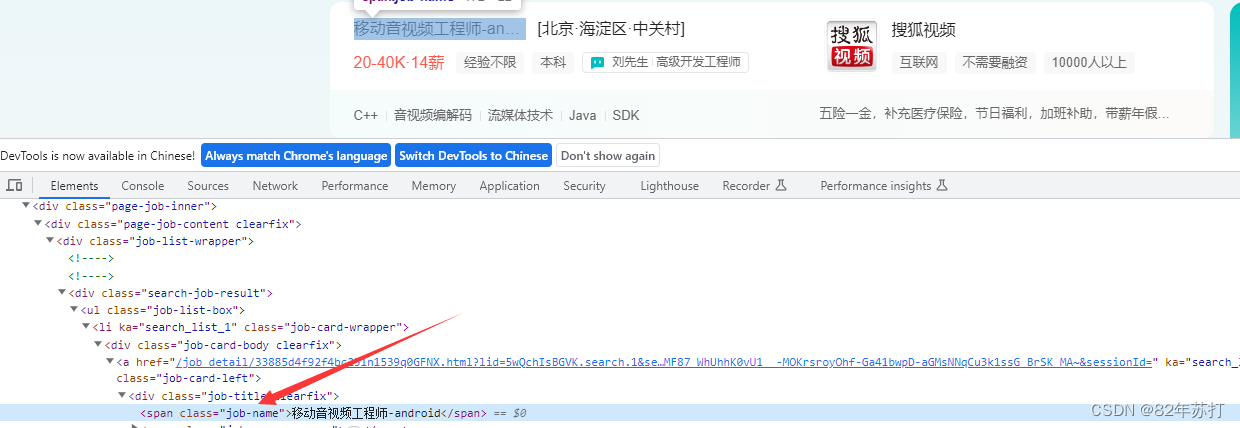
数据解析代码如下
def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}总代码
import csv
from time import sleep
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from lxml import etree# 指定url
urls = ['https://www.zhipin.com/', 'https://www.zhipin.com/web/geek/job?query={}&page={}']
prefix = 'https://www.zhipin.com'# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)
# bro = webdriver.Firefox(service=ser# 设置隐式等待 超时时间设置为20s
# bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])sleep(6)# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
sleep(15)# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
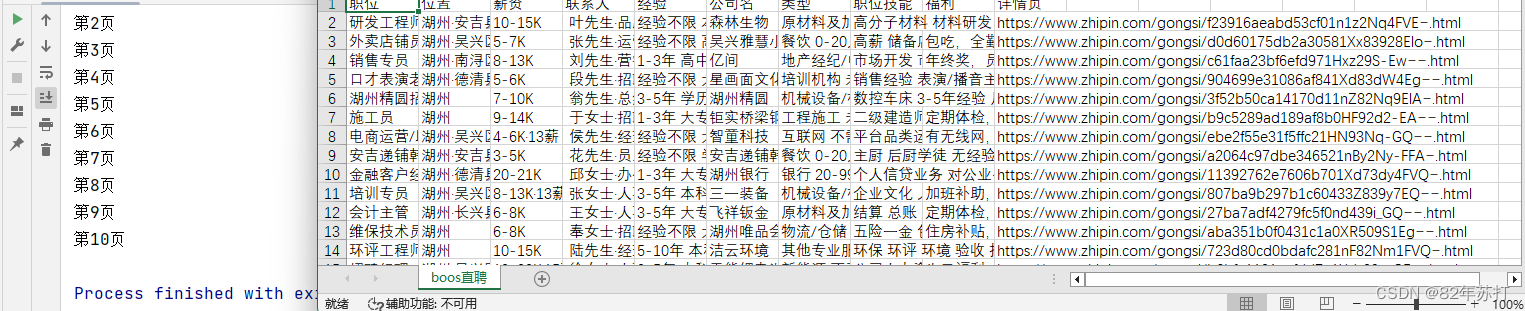
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}if __name__ == '__main__':# 访问第一页jobList = parse()query = ""# 访问剩下的九页for i in range(2, 11):print(f"第{i}页")url = urls[1].format(query, i)bro.get(url)sleep(15)jobList = parse()# 关闭浏览器bro.quit()效果展示
六、总结
不知道是boss反爬做的太好,还是我个人太菜(哭~)
我个人倾向于第二种
这个爬虫还有很多很多的不足之处,比如在页面加载的时候,boss的页面会多次加载(这里我很是不理解,我明明只访问了一次,但是他能加载好多次),这就导致是不是ip就会被封…
再比如,那个下一页的点击按钮,一直点不了,不知有没有路过的大佬指点一二(呜呜呜~)
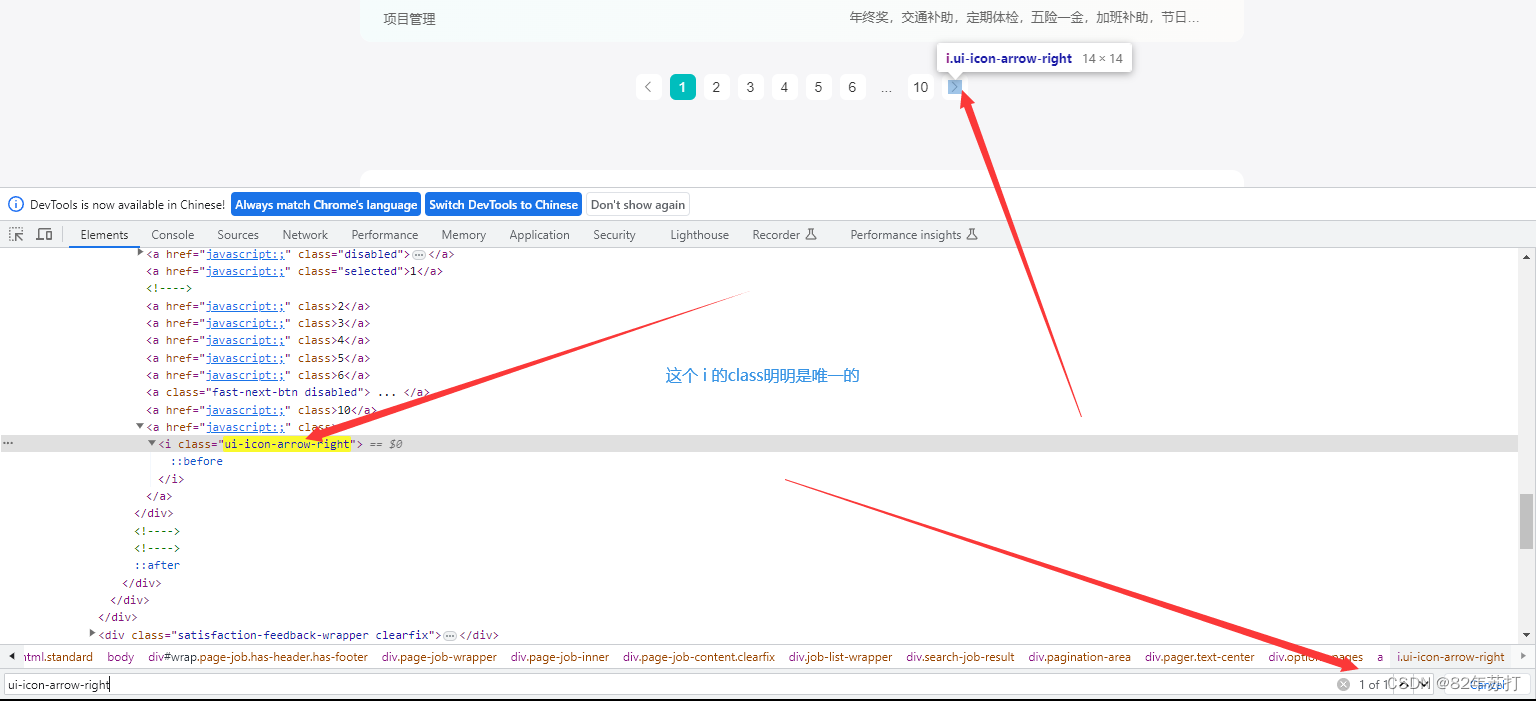
# 下一页标签定位 ui-icon-arrow-right
next_tag = bro.find_element(By.CSS_SELECTOR, value='.ui-icon-arrow-right')
# action = ActionChains(bro)
# # 点击指定的标签
# action.click(next_tag).perform()
# sleep(0.1)
# # 释放动作链
# action.release().perform()
总之boss的信息爬取,我还是无法做到完全自动化😭
这篇关于python爬取boss直聘数据(selenium+xpath)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





