本文主要是介绍数字中国建设全面铺开,这块数据应用“压舱石”你有了吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

近日,中共中央、国务院印发了《数字中国建设整体布局规划》,明确提出“数字基础设施高效联通,数据资源规模和质量加快提升,数据要素价值有效释放”。有专家解读,未来投资重点将从“新基建”走向“新应用”,应用端的创新必须高度精准化才能真正触达有效市场。结合当前各行各业上云实践来看,要“边打好地基边建房”,即在夯实云基础设施底座的同时,完成数据上云、应用上云,最大程度地释放数据潜能,创造新的业务价值。
数据要素化助推数字化转型
从宏观的国家政策层面分析,推动数字经济的发展已成为重中之重。从“十四五”规划到数字中国建设,激活数据要素价值,以数字化促进社会生产、生活和治理方式的改变,深化数据创新应用,构筑起新的竞争优势已成为当务之急。
从微观的企业数字化转型实践来看,抢抓数字化发展机遇,夯实数据要素基础支撑,加快推动数据要素流通和变现,实现数智融合、数实融合,是企业在数字化时代立足的基础和前提。以金融行业为例,数据能力无疑是重塑金融企业核心竞争力的关键能力之一,通过有效的数据治理与管理,不断提升数据质量与数据生产服务能力,不仅可以实现业务绩效的提升,而且可以在商业模式上实现更大的创新。
数字化转型是一段相对漫长的旅程,其中偶尔闪现的机会点在客观上可能成为企业加速转型升级的“助推器”。根据Gartner公开数据,传统数据库受制于原有架构,云转型步伐相对比较缓慢。随着业务的升级与拓展,部署海外产品的成本将愈发高昂。此外,Gartner预测,到2025年,中国分析型数据库市场来自海外厂商的将只剩下30%,交易型数据库市场海外厂商市场也只会剩下50%左右。
在这种背景和趋势下,创新根技术,在基础架构、核心平台、关键部件等领域“更新换代”、更快更好地实现国产化,是加速数字产业发展的必然需要,也是深化企业数字化转型的核心诉求,更是数字化技术和服务提供商的共同心声。

数据仓库要“破圈”
当前,几乎所有的企业级数据、终端数据和边缘设备数据都需要通过数据库管理系统的管理和分析才能够赋能上层应用或企业决策,发挥其最大的价值。作为根技术之一,数据仓库与芯片、操作系统、中间件等一样,也是亟需实现核心能力突破的一个重要领域。据中金公司测算,大数据基础软件国产替代空间广阔,年均将释放约150亿元的市场空间。数据仓库是数字经济时代当之无愧的软件底座。
数据仓库是一种分析型数据库,主要用于数据查询、分析,既承担着与核心业务系统及其他各业务系统的数据ETL功能,又承担着整合数据、分析挖掘数据等重要的数据处理功能,在金融、能源等数据量大、数据处理和分析要求高的行业尤显重要。
数据仓库市场长期被国外厂商所掌控。“咨询+硬件+软件”的上一代数据分析解决方案曾经是业界主流和被模仿的对象。但是随着移动互联网时代的到来,特别是数据量的爆发式增长,传统数据仓库产品的弊端逐渐显现,比如架构固定、成本高昂、应用门槛高、实时性差等。
云计算、AI技术的兴起,为数据仓库“破圈”提供了契机。“云+数据仓库”成为主航道,AI大模型+实时计算也从理想照进现实。交通银行软件开发中心总经理刘雷表示,在做数据仓库技术选型时,一定要注重数智融合,将数据仓库、数据管理能力与AI平台流程生命周期管理相结合。
另外,中国的行业用户对于数据仓库的性能和安全性尤为重视,因此对数据仓库厂商的产品性能、稳定性和自主可控能力提出了更高要求。
上述因素的综合作用,加速了数据仓库市场的“改朝换代”,具备开放、融合、云化、实时、全场景分析能力的新一代云数据仓库精彩登场。Gartner预测,未来将有75%的数据库跑在云平台之上。工信部《“十四五”软件和信息技术服务业发展规划》中明确提出,“加速分布式数据库产品研发和应用,突破分布式数据处理与任务调度架构、大规模并行图数据处理等关键技术,推动高性能数据库在重点行业关键业务系统中的应用”。这无疑为新一代云数据仓库的加快发展提供了最好的背书。
新一代云数仓胜在哪?
中国信通院预测,2021-2025年,中国数据库市场营收规模的年复合增长率为23.4%,2025年整体规模将达到688亿元。金融行业是部署数据仓库最早也是应用最广泛的行业之一。金融信息化研究所等多家单位共同发布的《金融数据仓库发展报告(白皮书)》显示,银行、证券、保险等金融机构已普遍建设了数据仓库,除部门区域性城商行外,国有大行、股份制银行等拥有数据仓库,证券与保险业建设数据仓库的比例也接近90%。
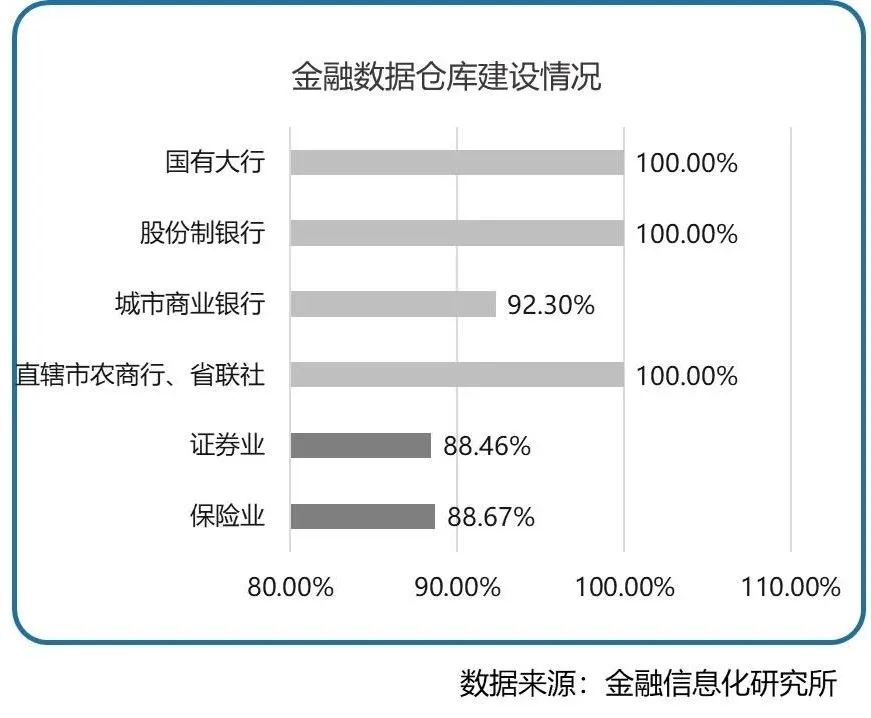
在云原生、分布式、开源等技术的推动下,越来越多的企业开始从传统数据仓库向云数据仓库迁移。那么新一代云数据仓库具备哪些特质,才能更好地支撑千行百业的数字化转型升级呢?
对行业客户使用数据仓库的需求调查显示,数据处理快,数据处理范围广,数据共享,数据要形成资产体系并产生持续的价值是最核心的诉求。而这正是云数据仓库的优势所在。
下面,我们以华为云GaussDB(DWS)数据仓库为例,具体分析一下新一代云数据仓库如何更好地满足政企数字化转型的需求。
众所周知,传统数据仓库产品大多是软硬件相结合的,而这种一体机模式的短板正在于扩展性差,扩容成本高,且兼容差,很难满足用户对高性能与灵活性的需求。分布式与云原生是当今软件领域的关键趋势,在数据仓库领域也不例外。十多年前华为云GaussDB(DWS)从起步开始就采用分布式架构,保证了数据仓库的高性价比和良好的扩展性,在走向云原生后,基于存算分离又实现了更高的弹性。华为云GaussDB(DWS)基于超大规模MPP分布式架构,实现了高并发百万QPS毫秒级点查询、万亿数据分析秒级响应,以及云数仓Serverless化分钟级弹性伸缩。华为云GaussDB(DWS)还是首个通过信通院认证的单集群可达2048节点超大规模的数据仓库,树立了业界新标杆。
例如,兴业银行基于华为云GaussDB(DWS)建设了新一代数字底座MPP基础平台,构建了一套包括数据整合加工、平台运营管理、数据灵活查询、API服务等功能的综合数据服务体系,高可用空间增长21倍,点查询单集群并发能力增长24倍。
数智融合是大势所趋,即数与智相辅相成,而传统数据仓库正是欠缺了AI这一左膀右臂。华为云近几年一直在湖仓一体与数智融合方面持续探索。新一代云原生架构数据仓库华为云GaussDB(DWS)将高并发、高性能、交互式的查询体验带入湖仓融合的数据栈,使能数据生产线与AI生产线的无缝高效配合,实现了全场景一站式数据分析,以湖仓一体/数智融合支持无限算力的扩展。
比如,明源云基于华为云GaussDB(DWS)构建的数仓分析平台能够提供一站式、全场景、智能BI、多模数据分析服务,更好地实现了辅助决策、预知趋势、防范风险的价值,沉淀企业数据资产。
国际形势风云变幻,市场不确定性不断增加,这些都让中国用户清醒地认识到,供应链风险、技术安全风险不容忽视,必须增强自主可控能力。《金融数据仓库发展报告(白皮书)》显示,国有大行基本都在使用我国的数据仓库产品或采取自研数据仓库模式,占比高达83.33%,股份制银行采用我国数据仓库产品的比例也高达66.67%。

华为云GaussDB(DWS)在国有大行和股份制银行中的部署比例达到55.6%,是中国金融数仓市场本地部署第一,引领着金融行业数仓标准发展。华为云GaussDB(DWS)具备高度自研能力,是国内厂商中唯一通过数仓类国际CC安全等级认证的产品,确保了安全可靠与自主可控,并且在工商银行、招商银行、光大银行等金融业高标准、大规模的业务严苛考验和工程应用中验证了其行业领先的高可靠性和先进性能。
举例来说,招商银行已完成了向华为云GaussDB(DWS)的全部迁移,并成功建立了国内首个大规模金融云数仓,批量数据处理完成进度整体提前2小时以上,业务用户查询时长缩短75%,有效支撑了“人人用数”大数据发展战略落地。
另外,传统数据仓库产品的运维门槛较高,原厂服务响应周期长,个性化定制支持度较低。华为云则提供了数仓服务与开发者认证体系,以本土化端到端的服务体系快速响应用户需求,并且协助用户培养技术人才梯队,有效降低数据仓库的应用门槛。

突破“卡脖子” 迎来新机遇
从基础架构上云,到数据库上云,应用现代化的节奏越来越快。新一代云数据仓库凭借其云原生、敏捷化、智能化、安全开放等优势快速崛起。在此背景下,自研数据仓库产品突破了关键技术领域“卡脖子”的问题,并且有效促进了企业的数智融合。
在今年全国“两会”期间,以数实融合为抓手,加快推动数字经济发展又将是热点之一。在夯实数字基础设施与数据资源体系两大基础,强化数字技术创新体系和数字安全屏障两大能力建设的过程中,数据仓库建设作为重要一环也将迎来新的发展机遇。
「往 • 期 • 精 • 选」
云原生数据库的进化逻辑
国产数据库“向未来”
openGauss汇聚创新力量,推动数据库跨越式发展
这篇关于数字中国建设全面铺开,这块数据应用“压舱石”你有了吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







