本文主要是介绍B站视频“多模态大模型,科大讯飞前NLP专家串讲”记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 多模态:
- 对齐 -- align
- 迁移学习和zero-shot
- Clip
- Blip
多模态:
图片、文字、视频、语音等不同的表征。
表示信息的方式有多种,但是不同的表示方式携带的信息不完全相同。

对齐 – align
如第一个图中,文字内容的描述和图片内容对应。
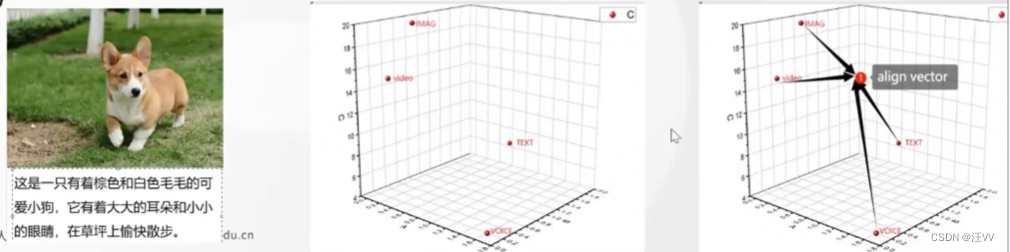
用不同单模态的模型将四种不同形式的”dog“表征成一个空间向量,可以发现虽然内容是同一个但是距离很远,所以想要用某种方式让四个点靠近一个点去,如果能变成一个点最好。
迁移学习和zero-shot
迁移学习:机器学习 – 首先在一个大数据集中跑模型,然后将预训练模型在自己的小数据集上进行微调。
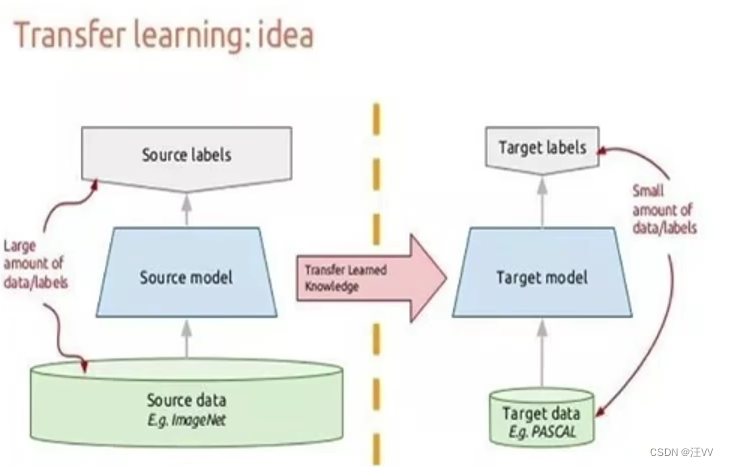
zero-shot:通过学习类别之间的关系和属性,使得模型能够在没有见过的类别上进行准确的分类。
解决了传统机器学习中的一个重要问题,即在没有足够标记样本的情况下,如何对新类别的样本进行分类。传统的监督学习算法需要大量标记样本来训练模型,但在现实世界中,获取大量标记样本可能是困难、耗时和昂贵的。这种能力对于处理大规模、多类别的问题非常有用,可以扩展模型的应用范围和适应性。
Clip
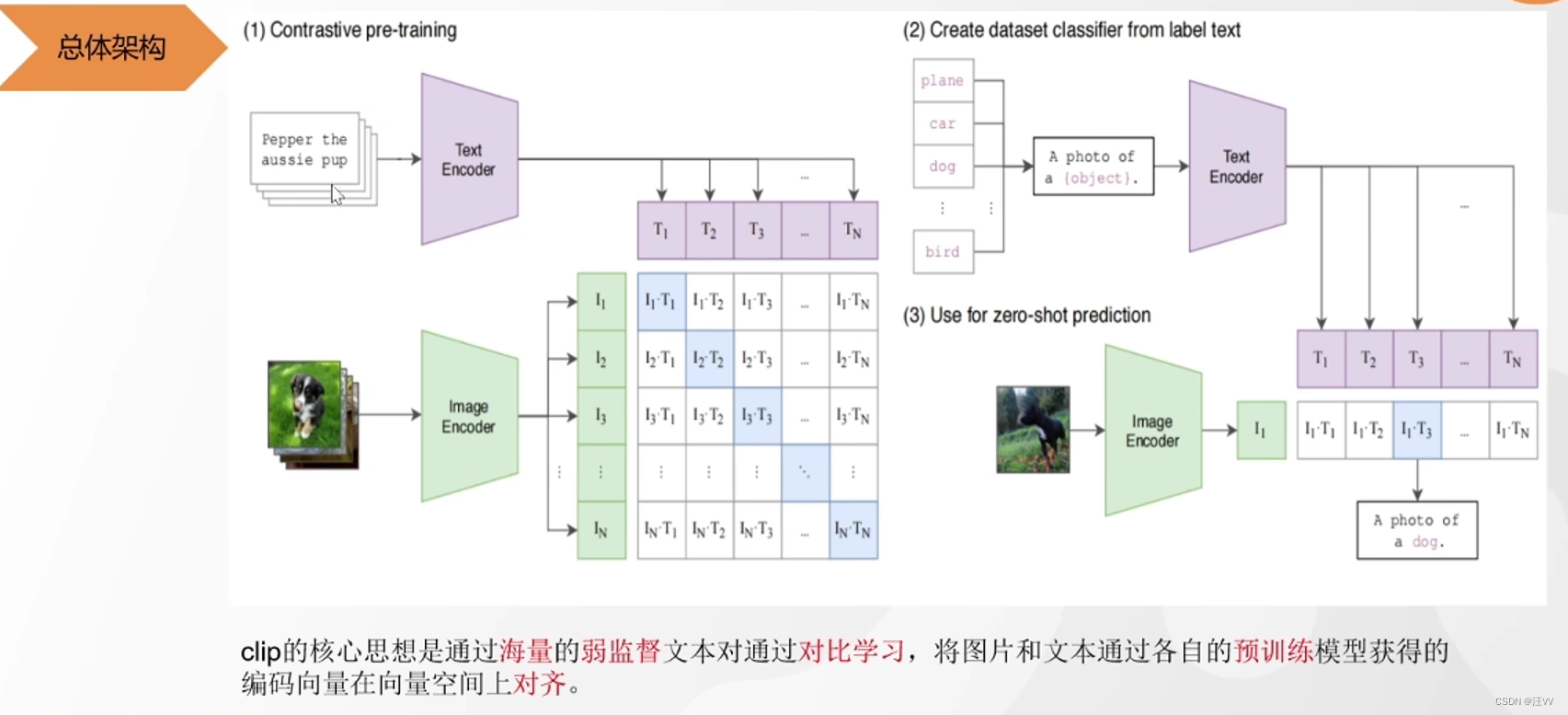
左侧训练时,通过一个对角为1的标签方阵,在大量正向传播和反向传播时逼着image encoding和text encoding优化,使两个编码后的向量对齐。有两个问题:
- 数据是没有经过处理的,可能有噪声,弱对齐
- 比如文本描述的是dog,但是可能不只有一个图片含有dog,按理来说标签矩阵不应该只是对角线有1
所以需要很大的数据集和很大的批次加速模型收敛。(该模型使用批次30000)
右侧使用时,对于 zero-shot 预测时,在分类中添加所有可能的类别,使用训练好的两个编码器,进行编码,计算相似度,即可预测出图像。
相对于以往模型的优点
- 训练完之后不需要微调,直接使用两个编码器
- 分类的类别加多少都可以,不像以往的分类只能在预测前确定好
作用:可以用文本推理图片,或者图片推理文本,图片搜图片,文本匹配文本
例如:1. 输入图片,匹配文字

2.文本匹配文本

Blip
既能完成图文匹配,又能完成文本生成。
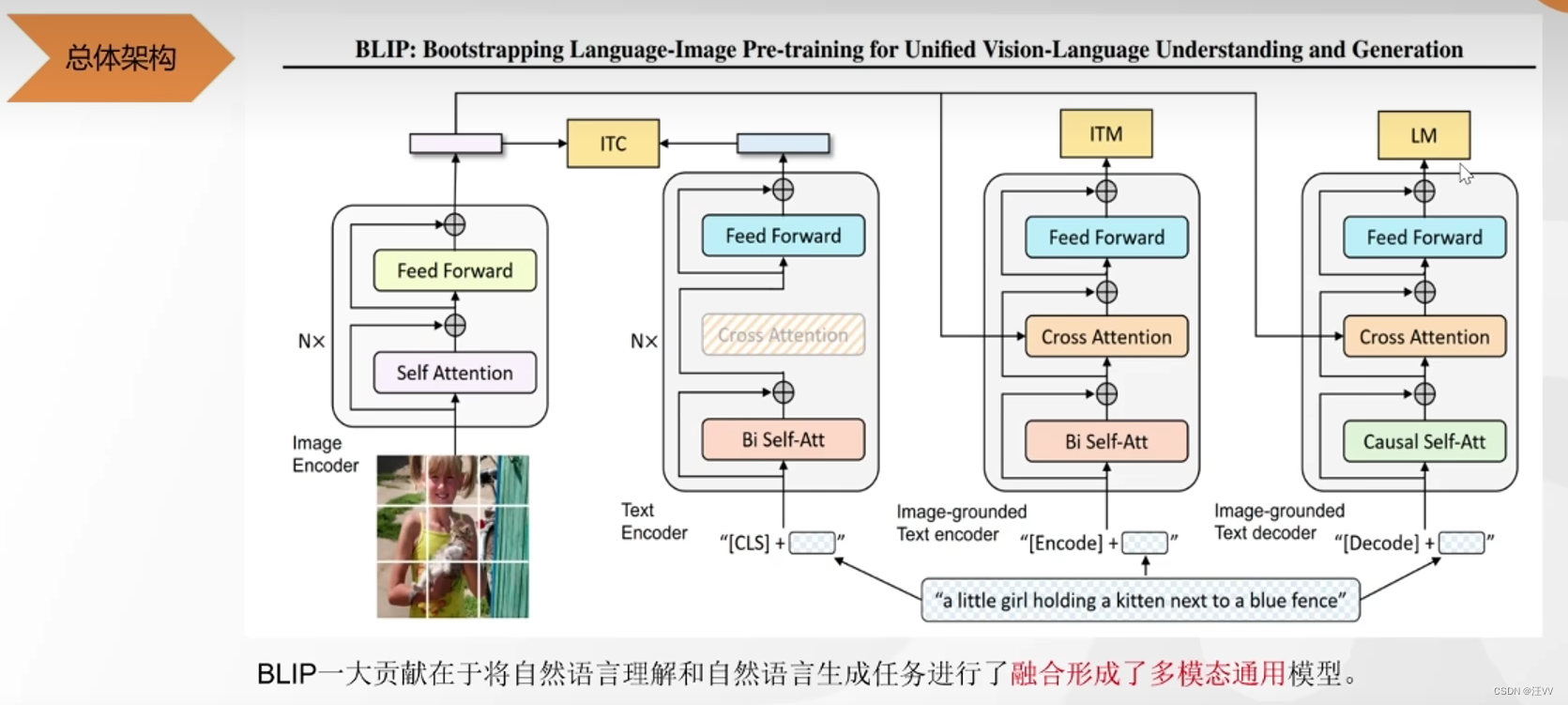
第一个:图片编码后输入,经过类似于transform编码器结构输出词向量 --》相对齐的文本编码后经过类似于bert的双向编码注意力机制,经过feed forward (也是类似于transform的encoder)得到文本向量 --》 二者做对比学习,使两个编码器得到的向量对齐
第二个:与第一个相同的模块,中间加了一个 transform解码器中与编码器输出共同做注意力的模块,融合文本和图像的特征 --》 最后做二分类任务,此处的二分类需要输入的负样本较难(即与正样本难以区分),所以此处的负样本是在第一个中对比学习中分类分错的。输入到第二个中判断文本和图像是不是说的同一件事(二分类)。相对于第一个更细粒度。
第三个:掩码输入,结合图像特征生成下一个对于图像的描述的词。causal self-att 是一个单向的,类似于GPT。
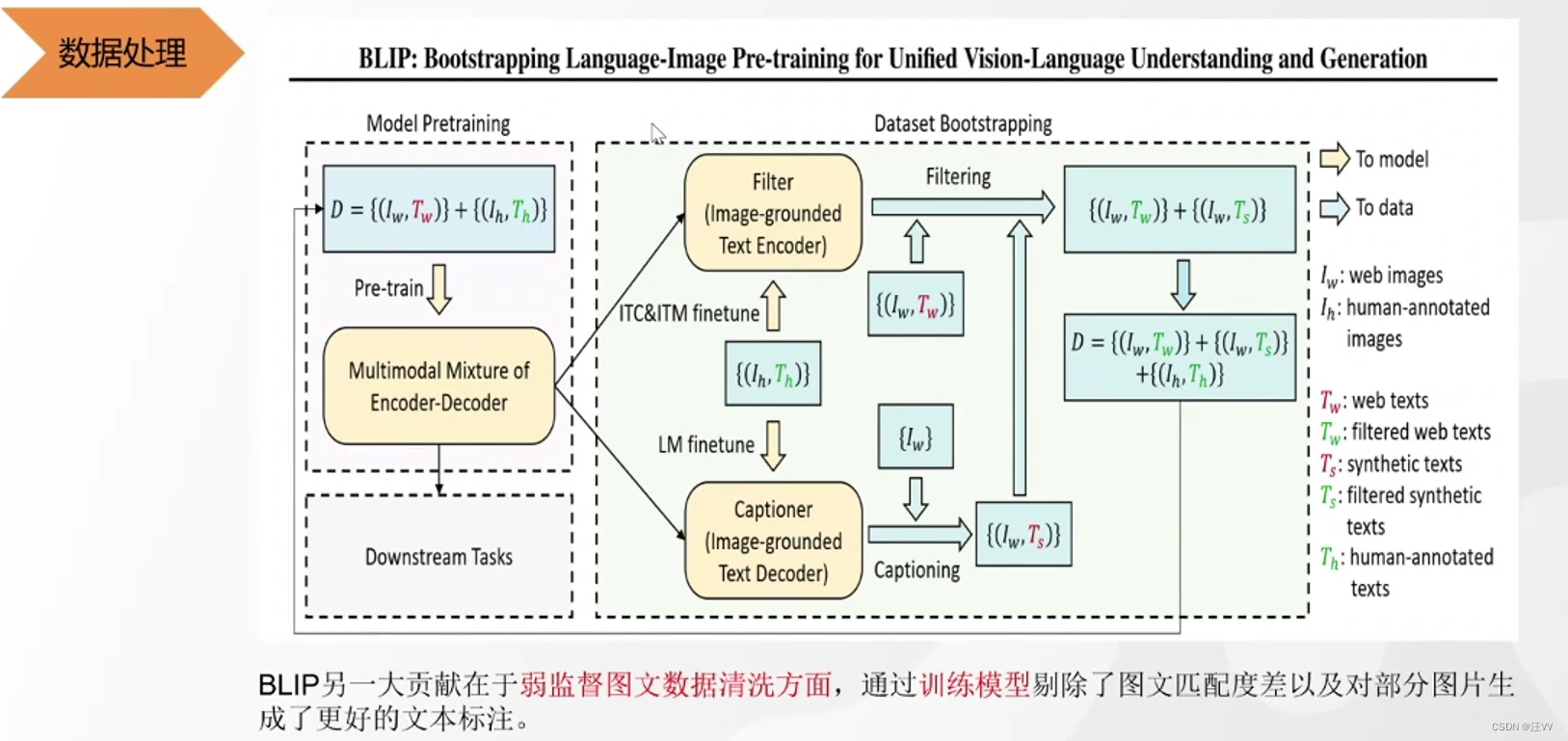
可以对数据进行清洗, I I I代表图像, T T T代表文本, w w w表示在网上爬下来的数据,若监督的, h h h表示人工标注好的,正确匹配的, T s T_s Ts表示生成的文本。
弱监督和强监督传入模型进行训练,然后分为两个模型:
对于图文匹配的模型,将正对的文本对传入再进行训练,使模型更正确,然后将弱监督对传入,判断是不是匹配,如果不匹配,则抛弃。
对于文本生成模型,也将正确的样本传入进行再训练,然后对未知文本的图像进行生成文本,然后扔到匹配模型里判断是否匹配,如果不匹配则扔掉,最后的数据集里包括的则是原来的正确数据集和预测后的匹配图像文本对。
得到的就是清洗后的图像文本对。

这篇关于B站视频“多模态大模型,科大讯飞前NLP专家串讲”记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




