本文主要是介绍数据科学库(HM)学习笔记(自用),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据分析是用适当的方法对收集来的大量数据进行分析,帮助人们作出判断,以便采取适当行动。
matplotlib
折线图 plt.plot(x,y)
最流行的Python底层绘图库,做能将数据可视化,更直观呈现,使数据更加客观,说服力。
from matplotlib import pyplot as plt
#导入pyplot,as重命名plt
fig=plt.figure(figsize=(20,8),dpi=80)
#设置图片大小,dpi参数让图片更清晰
x=range(2,26,2)
#x轴的取值,从2到24,步长为2
y=[15,13,14.5,17,20,25,26,26,24,22,18,15]
#y轴数
plt.plot(x,y)
#传入x和y,通过plot绘制出折线图
plt.xticks(range(2,25))
#设置x刻度
plt.savefig("./sig_size.png")
#保存图片, svg矢量格式,放大不会有锯齿。
plt.xlabel("time")
plt.ylabel("℃")
plt.title("Temperature changes")
#设置坐标轴信息
plt.show()
#执行程序时展示图形
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")
y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_2 = [1,0,3,1,2,2,3,3,2,1 ,2,1,1,1,1,1,1,1,1,1]
x = range(11,31)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.plot(x,y_1,label="自己",color="#F08080")
plt.plot(x,y_2,label="同桌",color="#DB7093",linestyle="--")
#设置x轴刻度
_xtick_labels = ["{}岁".format(i) for i in x]
plt.xticks(x,_xtick_labels,fontproperties=my_font)
# plt.yticks(range(0,9))
#绘制网格
plt.grid(alpha=0.4,linestyle=':')
#添加图例
plt.legend(prop=my_font,loc="upper left")
#展示
plt.show()

散点图 plt.scatter(x,y)
#导入pylot,导入中文包
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置字体,windows下的文字路径
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
x_3 = range(1,32)
x_10 = range(51,82)
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
#使用scatter方法绘制散点图,和之前绘制折线图的唯一区别
plt.scatter(x_3,y_3,label="3月份")
plt.scatter(x_10,y_10,label="10月份")
#调整x轴的刻度
_x = list(x_3)+list(x_10)
_xtick_labels = ["3月{}日".format(i) for i in x_3]
_xtick_labels += ["10月{}日".format(i-50) for i in x_10]
plt.xticks(_x[::3],_xtick_labels[::3],fontproperties=my_font,rotation=45)
#添加图例
plt.legend(loc="upper left",prop=my_font)
#添加描述信息
plt.xlabel("时间",fontproperties=my_font)
plt.ylabel("温度",fontproperties=my_font)
plt.title("标题",fontproperties=my_font)
#展示
plt.show()
条形图 plt.barh()
#绘制横着的条形图
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
#绘制条形图
plt.barh(range(len(a)),b,height=0.3,color="orange")
#设置字符串到x轴
plt.yticks(range(len(a)),a,fontproperties=my_font)
plt.grid(alpha=0.3)
# plt.savefig("./movie.png")
plt.show()
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")a = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]bar_width = 0.2x_14 = list(range(len(a)))
x_15 = [i+bar_width for i in x_14]
x_16 = [i+bar_width*2 for i in x_14]#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(a)),b_14,width=bar_width,label="9月14日")
plt.bar(x_15,b_15,width=bar_width,label="9月15日")
plt.bar(x_16,b_16,width=bar_width,label="9月16日")
#设置图例
plt.legend(prop=my_font)
#设置x轴的刻度
plt.xticks(x_15,a,fontproperties=my_font)
plt.show()
直方图 plt.bar()
from matplotlib import pyplot as plt
from matplotlib import font_managerinterval = [0,5,10,15,20,25,30,35,40,45,60,90]
width = [5,5,5,5,5,5,5,5,5,15,30,60]
quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47]print(len(interval),len(width),len(quantity))
#设置图形大小
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(12),quantity,width=1)
#设置x轴的刻度
_x = [i-0.5 for i in range(13)]
_xtick_labels = interval+[150]
plt.xticks(_x,_xtick_labels)plt.grid(alpha=0.4)
plt.show()
numpy
一个在Python中做科学计算的基础库,重在数值计算,也是大部分PYTHON科学计算库的基础库,多用于在大型、多维数组上执行数值运算

常见的更多数据类型

数据类型的操作




广播原则

怎么理解呢? 可以把维度指的是shape所对应的数字个数 那么问题来了: shape为(3,3,3)的数组能够和(3,2)的数组进行计算么? shape为(3,3,2)的数组能够和(3,2)的数组进行计算么? 有什么好处呢? 举个例子:每列的数据减去列的平均值的结果
轴(axis)
在numpy中可以理解为方向,使用0,1,2...数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴 有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值 那么问题来了: 在前面的知识,轴在哪里? 回顾np.arange(0,10).reshape((2,5)),reshpe中2表示0轴长度(包含数据的条数)为2,1轴长度为5,2X5一共10个数据
二维数组的轴

三维数组的轴

数组的切片
numpy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
numpy读取数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

现在这里有一个英国和美国各自youtube1000多个视频的点击,喜欢,不喜欢,评论数量(["views","likes","dislikes","comment_total"])的csv,运用刚刚所学习的只是,我们尝试来对其进行操作

转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据




numpy中数值的修改

numpy中布尔索引

numpy中三元运算符

numpy中的clip(裁剪)

numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:1.当我们读取本地的文件为float的时候,如果有缺失,就会出现nan 2.当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf) 比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)

numpy中的nan的注意点

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响? 比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行 那么问题来了: 如何计算一组数据的中值或者是均值 如何删除有缺失数据的那一行(列)[在pandas中介绍]
numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)
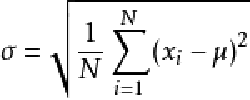
标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值 反映出数据的波动稳定情况,越大表示波动越大,越不稳定。默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
数组的拼接

数组的行列交换

numpy更多好用的方法
获取最大值最小值的位置 np.argmax(t,axis=0)
np.argmin(t,axis=1)
创建一个全0的数组: np.zeros((3,4))
创建一个全1的数组:np.ones((3,4))
创建一个对角线为1的正方形数组(方阵):np.eye(3)
numpy生成随机数

numpy的注意点copy和view
a=b 完全不复制,a和b相互影响
a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
a = b.copy(),复制,a和b互不影响
pandas
numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
pandas是一个开放源码的bsd许可库,为Python编程语言提供了高性能、易用的数据结构和数据分析工具。
常用数据类型
Series 一维,带标签数组
DataFrame 二维,Series容器
Series


Series切片和索引


Series的索引和值
对于一个陌生的series类型,我们如何知道他的索引和具体的值呢?

DataFrame

DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1

还有更多的经过pandas优化过的选择方式:
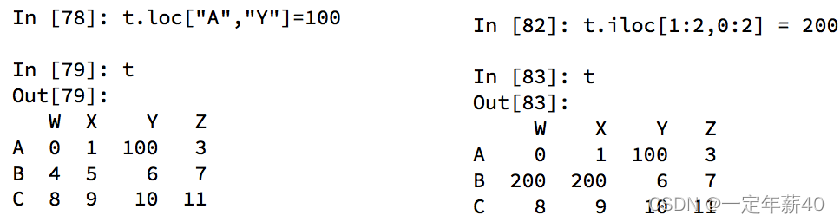
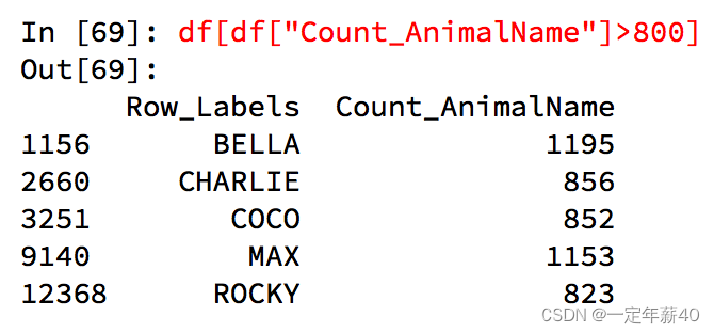
df.loc 通过标签索引行数据
df.iloc 通过位置获取行数据



字符串方法

缺失数据的处理
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,
t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
常用统计方法

数据合并之join
join:默认情况下他是把行索引相同的数据合并到一起

merge:按照指定的列把数据按照一定的方式合并到一起
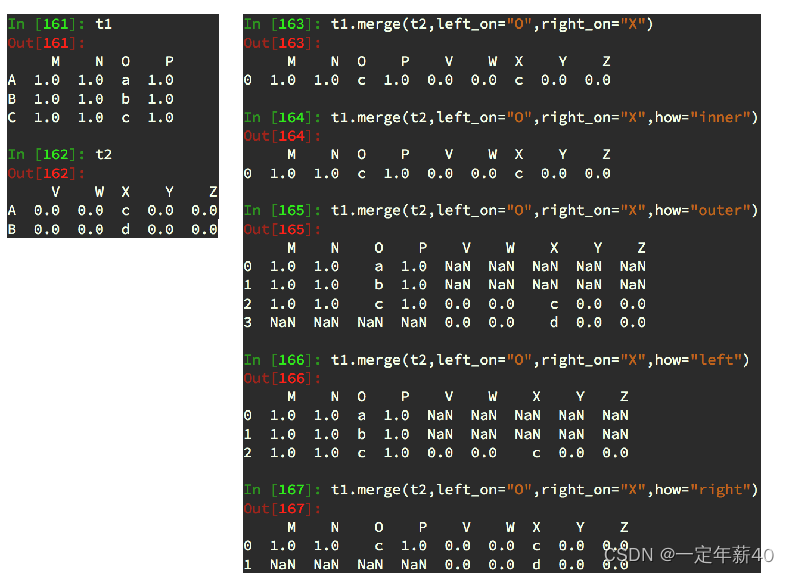
默认的合并方式inner,并集
merge outer,交集,NaN补全
merge left,左边为准,NaN补全
merge right,右边为准,NaN补全




生成一段时间范围
pd.date_range(start=None, end=None, periods=None, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
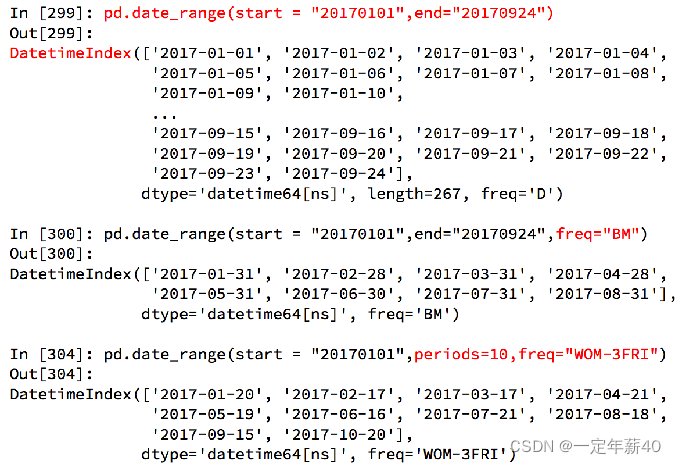
频率的更多缩写

这篇关于数据科学库(HM)学习笔记(自用)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






