本文主要是介绍mysql数据库转码步骤_七步操作!教你正确更换MySQL数据库字符集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为资深的DBA程序员,在工作中是否会遇到更这样的情况呢?
原有数据库的字符集由于前期规划不足,随着业务的发展不能满足业务的需求。如原来业务系统用的是utf8字符集,后期有存储表情符号的需求,uft8字符集就不能满足此时的业务需求了。需要用utf8mb4字符集。
数据库迁移,源和目标数据库的字符集不一致,需要在迁移之前进行转换。
更换数据库字符集的时候明明很认(jian)真(dan),总是会出现各种各样的问题,导致更换之后数据库的数据出现乱码!

今天小编就同大家一起梳理下如何正确更换数据库的字符集,下文将简单讲解数据库不同字符集的转换过程。步骤转化,杜绝乱码!
常用字符集
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其***位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。支持简体中文及繁体中文。
utf8字符集:是一种UTF-8编码的Unicode字符集,每个字符占用1到3个字节。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。
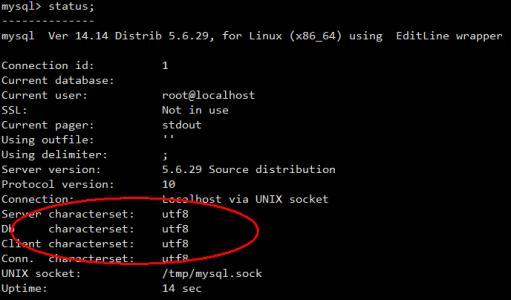
utf8mb4字符集:是一种UTF-8编码的Unicode字符集,每个字符占用1到4个字节。可以覆盖BMP范围内的字符和增补字符。BMP范围内的字符编码和utf8字符集中的编码是完全相同的,长度也是完全一样的,所以utf8mb4字符集可以兼容utf8字符集。
GB2312是GBK的子集,GBK是GB18030的子集。
big5支持繁体中文
转化过程
以下模拟的是将latin1字符集的数据库修改成GBK的过程 。其他字符集的转换过程类似。需要注意的是要转换的目标字符集一定是源字符集的超级或者目标字符集的范围包含源字符集的范围。
1. 导表结构
mysqldump -uroot -p--default-character-set=gbk-d databasename>createtb.sql
其中--default-character-set=gbk表示设置以什么字符集连接,-d表示只导出表结构,不导出数据。
2. 手工修改createtb.sql中表结构定义中的字符集为新的字符集。
3. 确保记录不再更新,导出所有记录
mysqldump -root -p --quick --no-create-info --extended-insert--default-character-set=latin1databasename>data.sql
quick:该选项用于转储大的表。它强制mysqldump从服务器一次一行地检索表中的行而不是所有的行,并在输出前将它缓冲到内存中。
extended-insert:使用包括几个values列表的多行insert语法。这样使转储文件更小,重载文件时可以加速插入。
no-create-info:不导出每个转储表的create table语句。
default-character-set=latin1:按照原有的字符集导出所有数据。这样导出的文件中,所有中文都是可见的,不会保存成乱码。
4. 打开data.sql,将set names latin1修改成set names bgk.
5. 使用新的字符集创建新的数据库。
create database databasename default charset bgk;
6. 创建表,执行createtab.sql
mysql -root -p databasename
7. 导入数据,执行data.sql
mysql -root -p databasename
总结
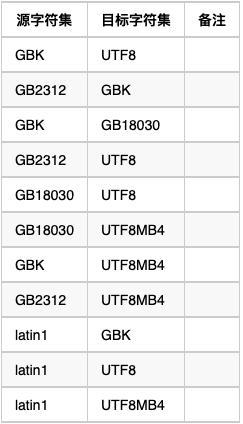
新的字符集一定要是原字符集的超集,不然转化之后,数据会出现乱码。常见字符集转换如下:
【编辑推荐】
【责任编辑:赵宁宁 TEL:(010)68476606】
点赞 0
这篇关于mysql数据库转码步骤_七步操作!教你正确更换MySQL数据库字符集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





