本文主要是介绍【计算机网络】网络层:IP数据报首部,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
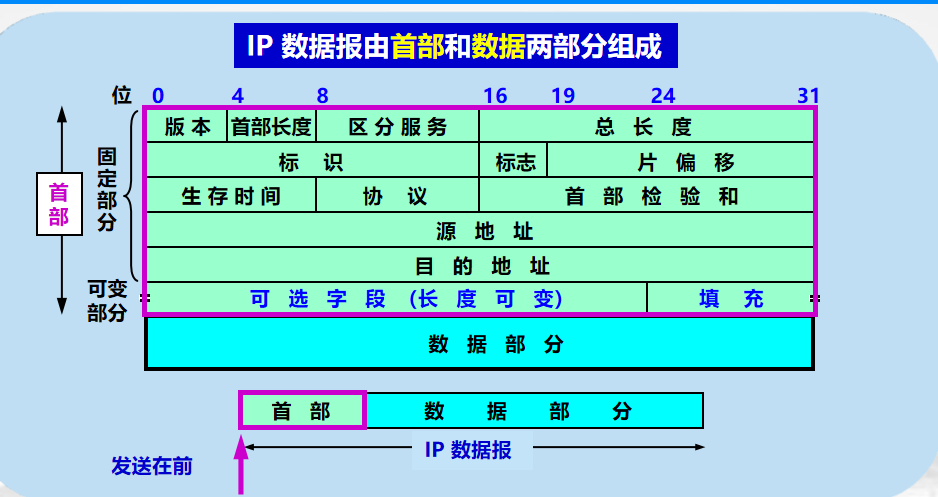
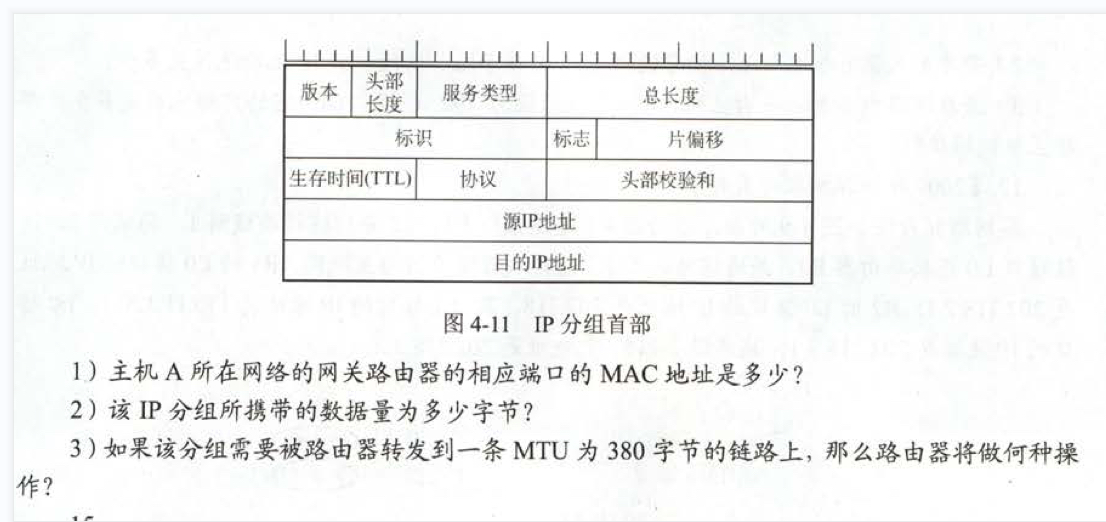
版本:IP协议版本
首部长度:乘以4为首部字节数
因为IP首部固定部分是20字节,因此首部长度字段的最小值是5
当首部字段长度为1111(即15),IP首部为60字节。
当IP数据报的数据部分不是4字节的整数倍时,必须利用最后的填充字段加以填充
区分服务:一般不使用
总长度:首部和数据之和的长度。
因为总长度字段为16位,所以数据报的最大长度为2^16-1=65535,
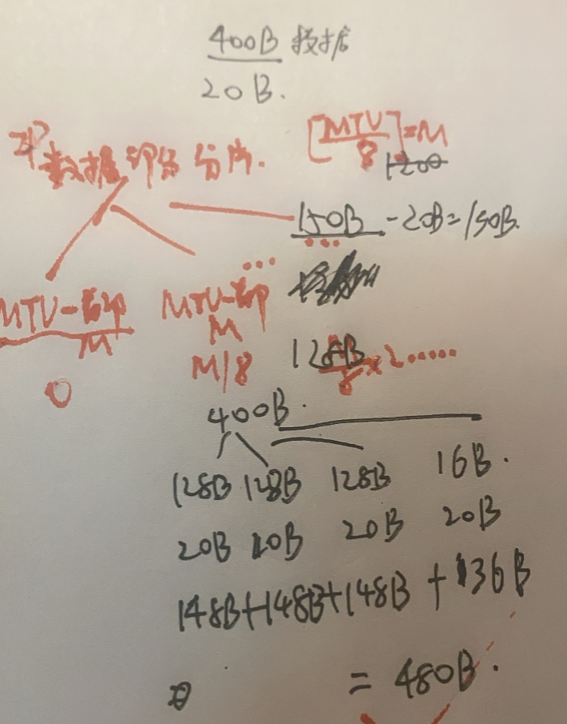
数据链路层规定了一个数据帧中的数据字段的最大长度MTU,即MTU是MAC帧数据部分的上限值,即IP数据报的上限。
所以IP数据报的总长度<=min{MTU,65535}
最长用的以太网规定其MTU是1500字节(即IP数据报首部+数据部分不能超过1500字节,若IP首部长度20B,则数据部分不能超过1480字节)
如果IP数据报超过数据链路层的MTU值,就必须把数据报进行分片处理。在进行分片时,数据报首部中的总长度字段是指分片后每一个分片的首部长度与该分片的数据长度的总和。
标识:IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。当数据报需要分片时,标识字段就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数据最后能正确地重装成为原来的数据报。
仅当标识符相同时IP数据报片才能组装成一个IP数据报。
标志:
3位,只有两位有意义。
最低位记为MF。MF=1表示后面还有分片。MF=0表示这已是若干数据报片中的最后一个。
标志字段中间的一位记为DF,DF=0才允许分片。
片偏移:分组分片后,某片在原分组中的相对位置。
生存时间(TTL):路由器在每次转发数据数据报之前把TTL值减1。若TTL值减少到0,则丢失这个数据报,不再转发。
当路由器收到生存时间为零的数据报时,除了丢弃该数据报外,还要向源点发送时间超过类型的ICMP报文。
分组是逐跳转发的

协议:指出数据报的数据部分使用何种协议。
IP数据部分使用TCP协议,协议字段为6
IP数据部分使用UDP协议,协议字段为17
首部检验和:只检验数据报的首部,但不包括数据部分。
(IP数据报首部检验和只检验首部。UDP/TCP检验和在加上12个字节的伪首部之后检验数据部分和首部)
使用反码检验是否出错。
源地址:发送IP数据报的主机的IP地址
目的地址:接受IP数据报的主机的IP地址
IP数据报首部的可变部分:
是一个选项字段,长度可变,可以增加IP数据报的功能,同时也使得IP数据报的首部长度成为可变的。
相关问题:
首部检验和:
1、IP数据报中的首部检验和并不检验数据报的数据,这样做的最大好处是什么?坏处是什么?
好处:不检验数据部分可以加快检查的过程,使转发分组更快
坏处:数据部分出错不能及早发现。
2、当IP数据报的首部检验和有差错时,为什么采取丢弃的办法,而不是要求源站重传此数据报?
IP首部中的源地址可能是错误的
3、计算首部检验和为什么不采用CRC循环检验码?
减少路由器进行检验的时间。
IP数据报分片:
1、为什么在目的主机进行组装,而不是在中间的路由器进行组装
(1)数据报片不一定经过同样的路由器
(2)如果在中间路由器就进行组装,后面可能还会拆分
(3)使路由器更简单一些
IP数据分片的题:
出错:
4000-20=3980


出错:数据部分字节数需要被8整除

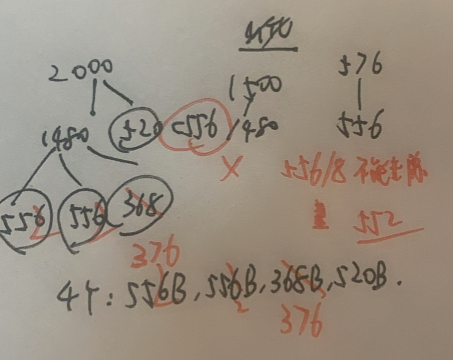

第一个字节800,最后一个879。

IP数据报解析题:

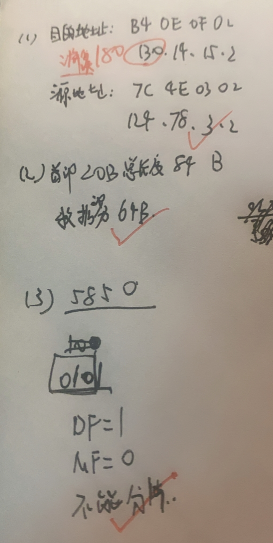
出错:DF=1时,即使IP数据报大于MTU,也不能分片,直接丢弃,并向源主机发送ICMP差错报文。


这篇关于【计算机网络】网络层:IP数据报首部的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





