本文主要是介绍心血管疾病预测--逻辑回归实现二分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、实现效果
实现心血管疾病的预测准确率70%以上
二、数据集介绍
数据共计70000条,其中心血管疾病患者人数为34979,未患病人数为35021。数据特征属性12个分别为如下所示:生理指标(性别、年龄、体重、身高等)、 医疗检测指标(血压、血糖、胆固醇水平等)和患者提供的主观信息(吸烟、饮酒、运动等):
age年龄
gender性别 1女性, 2 男性
height身高
weight 体重
ap_hi收缩压
ap_lo 舒张压
cholesterol胆固醇 1:正常; 2:高于正常; 3:远高于正常
gluc 葡萄糖,1:正常; 2:高于正常; 3:远高于正常
smoke 病人是否吸烟 alco 酒精摄入量
active 体育活动
cardio 有无心血管疾病,0:无;1:有
数据来源;http://idatascience.cn/
三、实现步骤
3.1 数据导入与分析
# 导入需要的工具包
import pandas as pd # data processing
import numpy as np
import matplotlib.pyplot as plt
#matplotlib inline
import seaborn as sns # plotfrom sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings("ignore")
import randomdata = pd.read_csv('E: /心脏疾病预测分析/cardio_train.csv',sep=',')
data.drop(columns=['id'],inplace=True)
data.head()
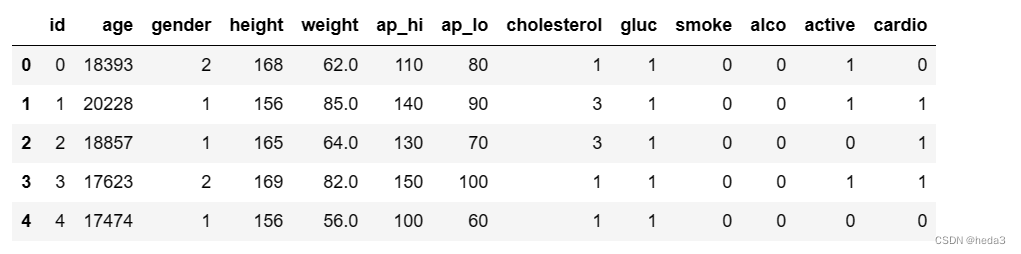
相关性分析:
correlations = data.corr()['cardio'].drop('cardio') #drop默认删除行
print(correlations)

3.2 划分数据集(训练数据集、测试数据集、验证数据集)
# 切分数据集
np.random.seed(1)#便于调试代码(设置种子-保证执行代码样本及结果一致--稳定复现结果)
# 获取当前随机状态
state = random.getstate()
# 获取随机种子
seed = state[1][0]msk = np.random.rand(len(data))<0.85
df_train_test = data[msk]# 筛选出59450个随机样本
df_val = data[~msk]#剩下的随机样本--用作验证数据集X = df_train_test.drop('cardio',axis=1)#删除最后一列,只包含样本特征
y = df_train_test['cardio']#样本对应的标签
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=70)#调用的训练和测试数据集样本划分函数
3.3 数据标准化
# 数据标准化
scale = StandardScaler()
scale.fit(X_train)
X_train_scaled = scale.transform(X_train)
X_train_ = pd.DataFrame(X_train_scaled,columns=data.columns[:-1])#添加列名,除去最后一列名(标签)scale.fit(X_test)
X_test_scaled = scale.transform(X_test)
X_test_ = pd.DataFrame(X_test_scaled,columns=data.columns[:-1])
3.4 特征选择
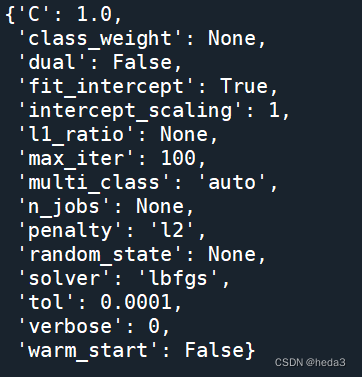
逻辑回归默认的算法为:lbfgs,L2正则化项。
模型的具体参数信息:
#特征选择
def feat_select(threshold):abs_cor = correlations.abs()features = abs_cor[abs_cor > threshold].index.tolist()
return features
def model(mod,X_tr,X_te):
mod.fit(X_tr,y_train)
pred = mod.predict(X_te)
print('Model score = ',mod.score(X_te,y_test)*100,'%')#子集准确性
# 逻辑回归#筛选出合适的阈值
lr = LogisticRegression()
#lr = LogisticRegression(penalty='l2', solver='saga')
# lr = LogisticRegression(solver='newton-cholesky')
# lr = LogisticRegression(solver='sag')
# lr = LogisticRegression(solver='newton-cg')threshold = [0.001,0.002,0.005,0.01,0.02,0.05,0.06,0.08,0.1]
for i in threshold:print("Threshold is {}".format(i))feature_i = feat_select(i)X_train_i = X_train[feature_i]#训练集X_test_i = X_test[feature_i]#测试集model(lr,X_train_i,X_test_i)
feat_final = feat_select(0.005)# 筛选出重要特征,列表
print(feat_final)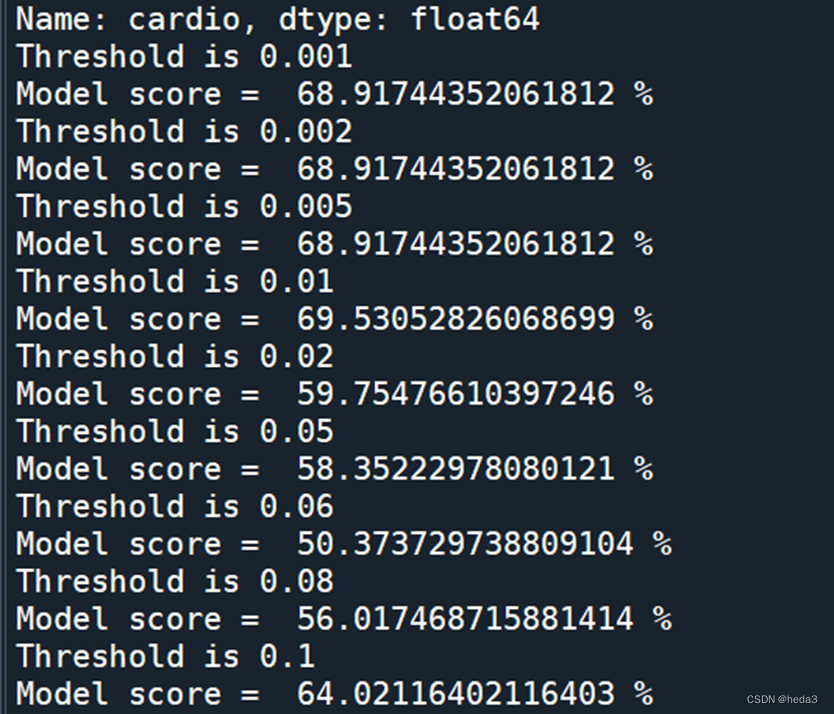
3.5 预测及结果评估
#验证数据集的标准化
X_val = np.asanyarray(df_val[feat_final])#删除最后一列,只包含样本特征 --转换为数组
y_val = np.asanyarray(df_val['cardio']) #--转换为数组scale.fit(X_val)
X_val_scaled = scale.transform(X_val)
X_val_ = pd.DataFrame(X_val_scaled,columns=df_val[feat_final].columns)#逻辑回归预测
lr.fit(X_train,y_train)
pred = lr.predict(X_val_)
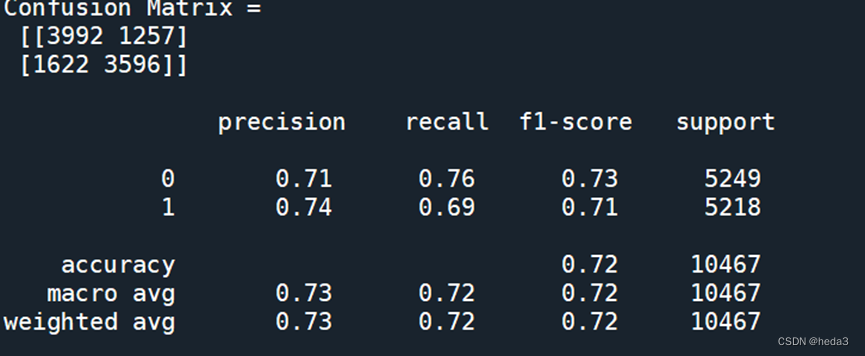
#结果评估
print('Confusion Matrix =\n',confusion_matrix(y_val,pred))
print('\n',classification_report(y_val,pred))
lr.get_params()
参考:
sklearn.linear_model.LogisticRegression — scikit-learn 1.2.2 documentation
这篇关于心血管疾病预测--逻辑回归实现二分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






