本文主要是介绍ArraySet 添加和删除元素分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一直在使用Set相关类进行运行时数据存储,之前也有知道Android为了更加有效的利用内存,在23的时候设计了自己的一套运行时的集合类。本文的以我的视角分析ArraySet的add和remove过程,并做了简单的对比分析。
结构
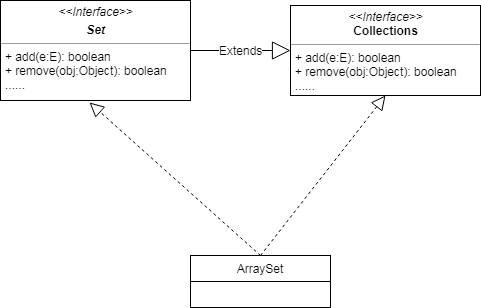
ArraySet实现了Set和Collections接口,故add和remove接口的使用方式相同,就不在对这两个接口的使用提供示例。
存储结构
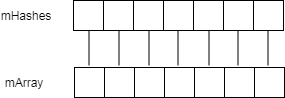
ArraySet在进行add和remove操作时,操作的是int[]类型的mHashes和Object[]类型的mArray,其中mHashes保存mArray每个元素的hash值,且mHashes和mArray相同下标的元素一一对应。
add
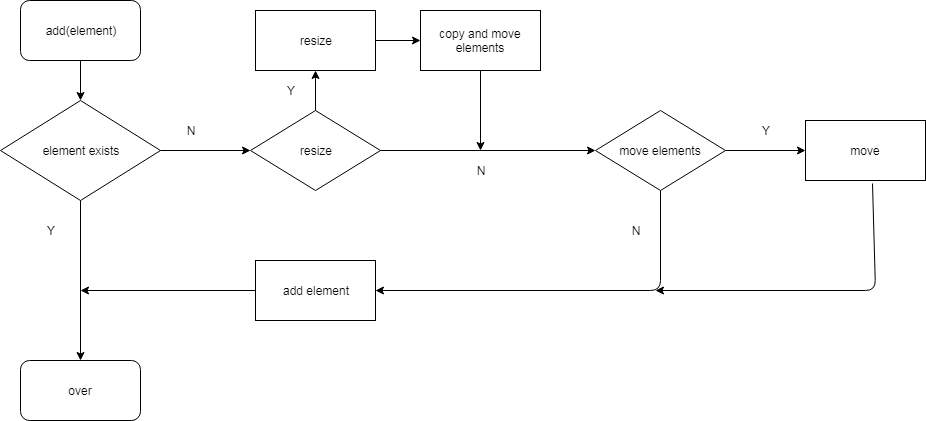
以上为 add的流程,可以概括为以下几点:
-
判断元素是否存在,已存在则直接返回
indexOf函数判断待插入元素是否存在,如果存在,则直接返回元素在mArray的下标,如果不存在,则返回带插入元素即将插入的位置的取反 -
判断是否需要对存储元素的数组进行扩容
ArraySet使用mSize记录当前元素的数量,如果mSize >= mHashes.length(元素的数量大于等于数组的长度),则需要对数组进行扩容,则计算扩容后的容量,扩容的规则会后续说明。扩容过程中还会涉及到的缓存也会后续说明。 -
根据元素插入的位置判断是否需要对数组元素进行移动
如果数组中不存在待插入元素,则在第一步中会计算出带插入元素待插入位置的取反,此不会再次取反,获得真实待插入的位置index。如果index < mSize(插入位置不在数组末尾),则需要将index+1只mSize - 1位置的元素后移一位。 -
插入元素
将待插入元素本身和其hash值分别插入到mArray和mHashes的index位置
remove
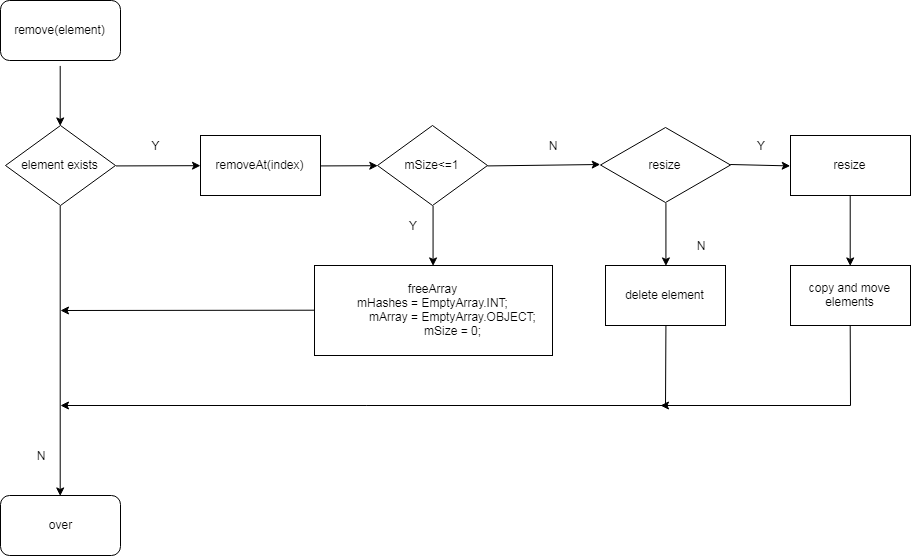
remove得流程可以概括如下:
- 判断元素是否存在,如果不存在则直接返回
- 如果当前元素小于等于1,则将
mHashes和mArray置空,否则会进行扩容判断判断 - 如果需要进行扩容,则计算扩容后的容量,扩容过程中涉及到的缓存处理会后续说明,扩容完成后会将原来数组中的元素copy到新数组中
- 扩容完成后,执行将
index至mSize-1的元素前移一位,删除待删除元素
indexOf
indexOf函数功能是查找元素在mArray中的位置,在add和remove操作过程中都涉及到查找元素的过程。看下这个函数的实现
private int indexOf(Object key, int hash) {final int N = mSize;// Important fast case: if nothing is in here, nothing to look for.if (N == 0) {return ~0;}int index = ContainerHelpers.binarySearch(mHashes, N, hash);// If the hash code wasn't found, then we have no entry for this key.if (index < 0) {return index;}// If the key at the returned index matches, that's what we want.if (key.equals(mArray[index])) {return index;}// Search for a matching key after the index.int end;for (end = index + 1; end < N && mHashes[end] == hash; end++) {if (key.equals(mArray[end])) return end;}// Search for a matching key before the index.for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {if (key.equals(mArray[i])) return i;}// Key not found -- return negative value indicating where a// new entry for this key should go. We use the end of the// hash chain to reduce the number of array entries that will// need to be copied when inserting.return ~end;}
indexOf函数的实现比较简单,首先会判断当前元素数量是否为0,如果是0,则直接返回-1,否则使用二分查找ContainerHelpers.binarySearch(mHashes, N, hash)获取元素的位置index。ContainerHelpers.binarySearch的代码比较简单,就不分析了。如果待查找元element素和mArray[index]相同,表示元素已经找到,直接返回index。若element未找到,则使用end记录如果将element插入mArray时的位置。
可以发现,indexOf函数有两个作用:
- 查找element在mArray中的位置
- 若element在mArray中不存在,则返回将element插入mArray中的位置的取反。
resize
ArraySet中没有resize函数,这里的resize表示ArraySet在add和remove时可能会执行的扩容操作,这里的扩容可能是增加容量,也可能是缩小容量。接下来会分别分下add和remove过程中涉及到的扩容操作。
add扩容
add过程中,如果mSize >= mHashes.length(元素的数量大于等于数组的长度),则数组(mHashes和mArray)需要进行扩容,扩容规则如下
private static final int BASE_SIZE = 4;final int n = mSize >= (BASE_SIZE * 2) ? (mSize + (mSize >> 1)): (mSize >= BASE_SIZE ? (BASE_SIZE * 2) : BASE_SIZE);
BASE_SIZE是ArraySet扩容的最小增量,已经经过Google工程师验证过,BASE_SIZE = 4时,内存的使用效率最高。根据以上的扩容规则,假设我们使用ArraySet mSet = new ArraySet()的方式新建了一个ArraySet对象,mHashes和mArray的长度大小变化如下:
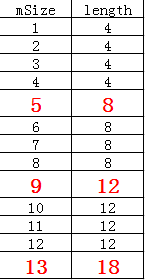
上图中,mSize表示mHashes和mArray中元素的数量,length表示mHashes和mArray的长度。
remove缩容
remove的过程中ArraySet会根据一定的规则对mHashes和mArray的大小进行缩小,缩小规则如下:
if (mHashes.length > (BASE_SIZE * 2) && mSize < mHashes.length / 3) {final int n = mSize > (BASE_SIZE * 2) ? (mSize + (mSize >> 1)) : (BASE_SIZE * 2);......
}
缩容的规则比扩容稍微简单一些,数组mHashes和mArray长度是一样的,故缩容的条件可理解为:
mHashes和mArray长度大于BASE_SIZE * 2mHashes和mArray中元素的数量小于数组长度的1/3
缩容之后数组mHashes和mArray的长度:
n = mSize > (BASE_SIZE * 2) ? (mSize + (mSize >> 1)) : (BASE_SIZE * 2);
可以发现,缩容之后,mHashes和mArray的长度最小为BASE_SIZE * 2
缓存
在add过程中,如果需要扩容,需要走如下逻辑:
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
......
freeArrays(ohashes, oarray, mSize);
在remove过程中,如果需要缩容,则需要走如下逻辑:
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
以上两段代码中n表示计算后数组的容量。在add的扩容和remove的缩容过程中,都会调用allocArray,可以看下具体实现,代码可能比较长,但不是很复杂
private void allocArrays(final int size) {if (size == (BASE_SIZE * 2)) {synchronized (ArraySet.class) {if (sTwiceBaseCache != null) {final Object[] array = sTwiceBaseCache;try {mArray = array;sTwiceBaseCache = (Object[]) array[0];mHashes = (int[]) array[1];array[0] = array[1] = null;sTwiceBaseCacheSize--;if (DEBUG) {Log.d(TAG, "Retrieving 2x cache " + mHashes + " now have "+ sTwiceBaseCacheSize + " entries");}return;} catch (ClassCastException e) {}// Whoops! Someone trampled the array (probably due to not protecting// their access with a lock). Our cache is corrupt; report and give up.Slog.wtf(TAG, "Found corrupt ArraySet cache: [0]=" + array[0]+ " [1]=" + array[1]);sTwiceBaseCache = null;sTwiceBaseCacheSize = 0;}}} else if (size == BASE_SIZE) {synchronized (ArraySet.class) {if (sBaseCache != null) {final Object[] array = sBaseCache;try {mArray = array;sBaseCache = (Object[]) array[0];mHashes = (int[]) array[1];array[0] = array[1] = null;sBaseCacheSize--;if (DEBUG) {Log.d(TAG, "Retrieving 1x cache " + mHashes + " now have " + sBaseCacheSize+ " entries");}return;} catch (ClassCastException e) {}// Whoops! Someone trampled the array (probably due to not protecting// their access with a lock). Our cache is corrupt; report and give up.Slog.wtf(TAG, "Found corrupt ArraySet cache: [0]=" + array[0]+ " [1]=" + array[1]);sBaseCache = null;sBaseCacheSize = 0;}}}mHashes = new int[size];mArray = new Object[size];
}
如果不考虑缓存部分,直接到函数的最后,可以发现,allocArray函数其实就是根据计算出来的长度,新建了mHashes和mArray数组。再看下缓存部分,Google设计了两个节点,BASE_SIZE和BASE_SIZE * 2,如果计算后数组的容量是以上两个节点,则尝试从缓存中给mHashes和mArray赋值。至于为什么不设置其他的节点,个人猜测,可能是Google认为这两个节点是数组在变化过程中会经常到达的点;也可能是认为如果缓存其他节点,缓存的数组过长,对内存的消耗较大。
说了这么多缓存,这个缓存究竟是什么结构呢,这个缓存是如何被赋值的呢?我们先给出这个缓存的结构,然后在分析freeArray中分析缓存的赋值。
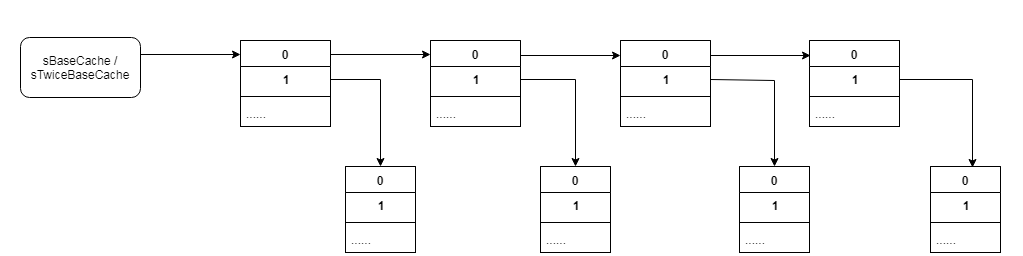
以上就是缓存的结构,sBaseCache和sTwiceBaseCache指向的节点称为缓存节点,sBaseCache和sTwiceBaseCache指向的是最新的缓存节点,这样的缓存节点最多有CACHE_SIZE = 10个。每个缓存节点都是一个Object类型的数组,index = 0的元素指向下一个缓存节点,index = 1的元素指向缓存的mHashes的数组。
接下来看下在释放数组的时候,freeArray函数是如何给缓存赋值的
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {if (hashes.length == (BASE_SIZE * 2)) {synchronized (ArraySet.class) {if (sTwiceBaseCacheSize < CACHE_SIZE) {array[0] = sTwiceBaseCache;array[1] = hashes;for (int i = size - 1; i >= 2; i--) {array[i] = null;}sTwiceBaseCache = array;sTwiceBaseCacheSize++;if (DEBUG) {Log.d(TAG, "Storing 2x cache " + array + " now have " + sTwiceBaseCacheSize+ " entries");}}}} else if (hashes.length == BASE_SIZE) {synchronized (ArraySet.class) {if (sBaseCacheSize < CACHE_SIZE) {array[0] = sBaseCache;array[1] = hashes;for (int i = size - 1; i >= 2; i--) {array[i] = null;}sBaseCache = array;sBaseCacheSize++;if (DEBUG) {Log.d(TAG, "Storing 1x cache " + array + " now have "+ sBaseCacheSize + " entries");}}}}
}
上面的代码看着很多,逻辑理解起来相对比较简单的,在释放数组的size为4或者8的时候,会首先判断缓存节点的数量是否已经超过CACHE_SIZE,如果没有超过,则将待释放的array作为一个缓存节点,array[0]指向目前最新的节点,array[1]指向待释放的hashes数组,然后调整sBaseCache / sTwiceBaseCache指向array。这就是freeArray添加缓存节点或者说设置缓存的流程。
再回顾下前面的allocArray, 如果从最新的缓存节点中给mHashes和mArray赋值,sBaseCache / sTwiceBaseCache调整自己的指向,指向上一个缓存节点。
在添加缓存节点的时候,有这样的逻辑一直在引起我的关注
for (int i = size - 1; i >= 2; i--) {array[i] = null;
}
这段逻辑如果仔细分析,可以发现Google程序员考虑的真的很周全。我们在freeArray的时候,函数中传递的array是数组,这个数组指向的是Object[]类型的mArray,也就是说函数参数中的array和mArray指向的是同一块内存区域,array中每一个元素和mArray中每个元素引用同样的内存区域。如果没有array[i] = null这一步逻辑,每一个缓存节点从2号为元素开始,都会引用mArray对应节点指向的内存区域。
猜测可能会产生两个后果:
- 由于数组
mArray指向的内存区域存在过多的引用,其他程序可能会使用这些引用修改缓存,引起缓存异常 - 虚拟机中普遍采用可达性分析的方式计算内存是否可以被回收,在判断时,会沿着GC Root搜索,如果对象在以GC Root为根的链上,则对象不能被回收。如果没有
array[i] = null,则随着缓存的增加,mArray指向的对象增加大量的引用,可能会影响虚拟机的内存回收
补充一下
虚拟机中使用可达性分析的方式来判断对象所占用的空间是否需要回收。使用可达性分析的时候,虚拟机会从GC Root开始往下搜索,搜索的过程中,会形成一条引用链,如果某个对象在引用链上,则此对象还在存活不能被回收。可以作为GC Root的对象包括下面几种:
- 虚拟机栈中引用的对象
- 方法区中静态属性引用的对象
- 方法区中常亮引用的属性
- 本地方法栈中应用的对象。
以上有关虚拟机的内容,可参考《深入理解Java虚拟机》第二版,3.2.2节相关内容。此部分的分析没有经过验证,大家有验证方式可以回复我一下。
总结
根据Google官方的说明,ArraySet的设计是为了更加有效的利用内存,它的对比目标是HashSet,HashSet的实现底层是HashMap,故ArraySet实际上就是和HashMap进行对比。既然说ArraySet可以更加有效利用内存,有效在那些方面呢?接下来就对比下优势和劣势。
优势:
ArraySet使用更少的存储单元存储元素
ArraySet使用int类型的数组存储hash,使用Object类型数组存储元素,相较于HashMap使用Node存储节点,ArraySet存储一个元素占用的内存更小。ArraySet在扩容时容量变化更小
HashMap在扩容的时候,往往会对原来的容量扩大一倍,而ArraySet在元素超过8之后,只会增加元素个数的1/2,在扩容过程中更省内存空间。
劣势
- 存储大量元素(超过1000)时比较耗时
相较于HashMap使用hash算法直接找到数组下标,然后从该下表的元素往后搜索,ArraySet在查找元素时需要进行二分查找,如果数组元素数量过多(超过1000),可能比较耗时。 - 在扩容和缩容时可能会频繁移动元素
ArraySet在扩容和缩容时需要移动元素,且扩容时容量变化比HashMap小,扩容和缩容的频率可能更高,元素数量过多时,元素的移动可能会对性能产生影响。
Google给出了提示,如果元素的数量少于1000,性能最多降低50%。
建议
对程序员来说,Read The Fucking Source Code才能真正了解其中的原理,文章以我的视角分析了ArraySet,可能有些分析并不能满足需求,建议各位去Read The Fucking Source Code,同时也帮我检查看有没有问题。
写的功力不好,文章中可能有很多写的不清楚甚至可能会有错误,希望大家能指出来,我及时修改。
这篇关于ArraySet 添加和删除元素分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








