本文主要是介绍基金评价专题5:公募基金持仓分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 获取持仓情况
2. 十大持仓情况
3. 行业分布情况
4. 行业纵向比对
5. 历史总仓位
6. 特别强调
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的基金仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。
前面做过基于公募基金净值的评价框架介绍,单从净值层面获取的信息是相对有限的。因此,本期从持仓的角度进行进一步的探究。
1. 获取持仓情况
本文以110009(偏股型非指数基金)基金为例,使用akshare的接口获取相应的数据源,首先获取该基金在2023年第二季度的持仓情况。整体的代码如下:
import akshare as ak
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdef get_position(year, quarter, code):# 获取某年某季度的持仓date_str = str(year) + '年' + str(quarter) + '季度股票投资明细'# 获取对应时间节点的持仓fund_position = ak.fund_portfolio_hold_em(symbol=code, date=str(year))fund_position = fund_position.loc[fund_position['占净值比例']!=0]position = fund_position.loc[fund_position['季度'] == date_str]return position
if __name__ == '__main__':code = "110009"# 设置年份和季度year, quarter = 2023, 2date = str(year)+'年'+str(quarter)+'季度'position = get_position(year, quarter, code)得到的持仓结果--position(持仓较多,此处仅展示了部分)如下:
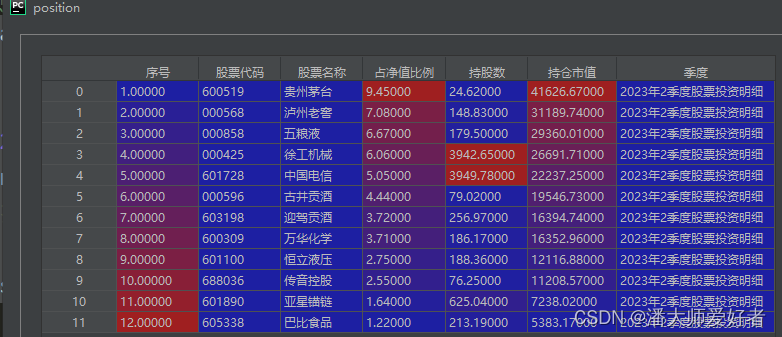
2. 十大持仓情况
在获取了持仓的基本情况后,取前十大持仓,作出其前十大持仓的仓位占比图。由于十大持仓的占比达不到100%,因此增加一项其余持仓的情况。
import akshare as ak
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdef get_position(year, quarter, code):# 获取某年某季度的持仓date_str = str(year) + '年' + str(quarter) + '季度股票投资明细'# 获取对应时间节点的持仓fund_position = ak.fund_portfolio_hold_em(symbol=code, date=str(year))fund_position = fund_position.loc[fund_position['占净值比例']!=0]position = fund_position.loc[fund_position['季度'] == date_str]return position
def get_ten_position(position):# 取出前十大持仓以及其对应的比例new_p = position.sort_values(['占净值比例'], ascending=False).loc[0:9]top_ten = pd.DataFrame({'股票名称': new_p['股票名称'], '仓位占比': new_p['占净值比例']})# 增加其余持仓other_po = 100 - top_ten['仓位占比'].sum()other_df = pd.DataFrame({'股票名称': ['其余持仓'], '仓位占比': [round(other_po, 2)]})top_ten = top_ten.append(other_df)return top_tenif __name__ == '__main__':code = "110009"# 设置年份和季度year, quarter = 2023, 2date = str(year)+'年'+str(quarter)+'季度'position = get_position(year, quarter, code)position_sum = format( position['占净值比例'].sum()/100,'.2%')# 获取前十大持仓以及其余持仓的扇形分布图top_ten = ten_positionplt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falsedata = (top_ten['仓位占比'] / 100).tolist()name = top_ten['股票名称'].tolist()plt.pie(data, labels=name, autopct='%.2f%%')plt.title(date + '十大持仓及其余持仓占比图'+'(总仓位'+position_sum+')')plt.show()对应得到的结果为:
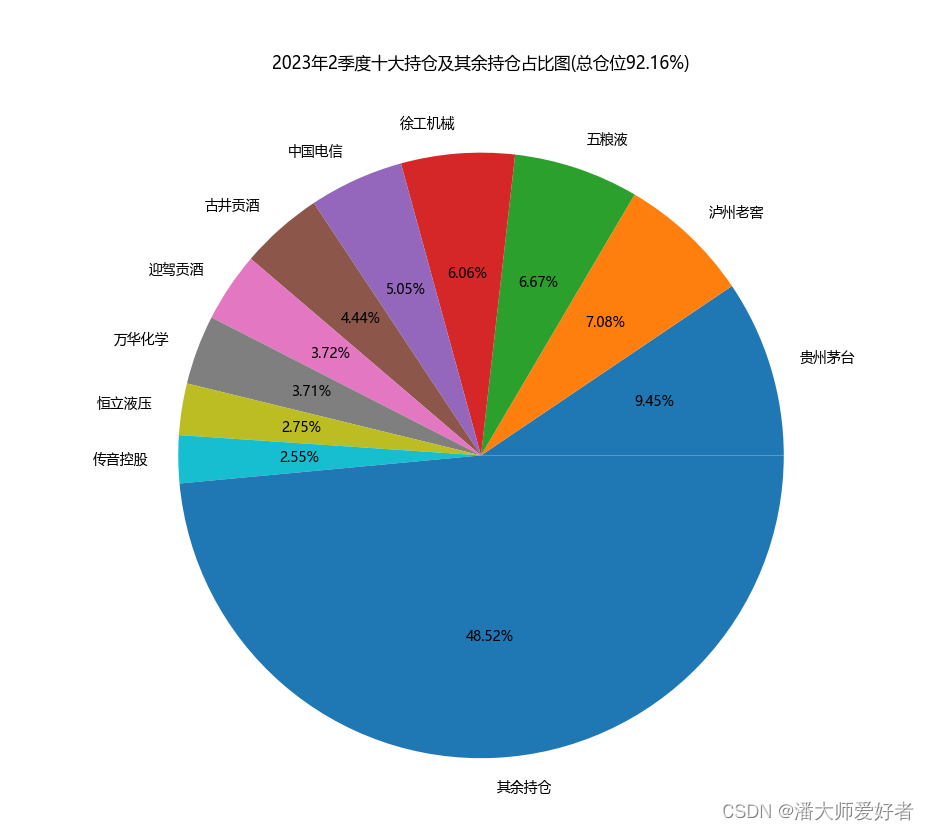
从当期十大持仓及其余持仓的分布图中,可以看出:1.该基金的前十大持仓股票的总仓位占比约为51.5%,整体持仓集中度适中。2.该基金第一大持仓股票的总仓位低于10%,不存在重仓押票的情形。3. 该基金前十大持仓股的均值为5%,最大值9.45%,最小值2.25%,整体分布较为均匀。4.该基金的股票总仓位为92.16%,符合偏股型基金的特征,但还仓位整体还是偏高。总结下来,从前十大持仓的情况看,该基金持仓分布均匀,不存在单票重仓的情形,属于持仓稳健且均匀分散,但整体仓位偏高的风格。
3. 行业分布情况
在分析了十大持仓的情况后,还需要对持仓所属的行业进行进一步的讨论。个股仓位的控制更多只反映了对于标的风险的控制,如果要进一步了解基金的分散化控制程度以及对行业偏好,还需要对其持仓进行行业分布的统计。
首先,构造一个函数来获取股票所属行业(依据东方财富的划分标准),此处还是直接使用akshare的接口。
def get_industry(code):# 获取股票所属的行业# code:str,例如'000001'stock = ak.stock_individual_info_em(symbol=code)industry = stock.loc[stock['item'] == '行业']['value'].values[0]return industry接下来,获取持仓股票所属的行业,并对行业对应的持仓占比进行求和,由于部分基金持仓的股票可能较多,且大部分股票的仓位占比较低,考虑到效率,本文仅对仓位占比前30的股票进行统计。
import akshare as ak
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdef get_position(year, quarter, code):# 获取某年某季度的持仓date_str = str(year) + '年' + str(quarter) + '季度股票投资明细'# 获取对应时间节点的持仓fund_position = ak.fund_portfolio_hold_em(symbol=code, date=str(year))fund_position = fund_position.loc[fund_position['占净值比例']!=0]position = fund_position.loc[fund_position['季度'] == date_str]return positiondef get_industry(code):# 获取股票所属的行业# code:str,例如'000001'stock = ak.stock_individual_info_em(symbol=code)industry = stock.loc[stock['item'] == '行业']['value'].values[0]return industrydef get_position_industry(position):# 获取持仓所属的行业if len(position)>30:position_part = position.sort_values(['占净值比例'], ascending=False).loc[0:29]else:position_part = positionposition_part['所属行业'] = position_part['股票代码'].apply(lambda x: get_industry(str(x)))industry_df = position_part.groupby(['所属行业'])['占净值比例'].sum().reset_index()# 排序position_industry = industry_df.sort_values(['占净值比例'], ascending=False).reset_index()return position_industryif __name__ == '__main__':code = "110009"# 设置年份和季度year, quarter = 2023, 2date = str(year)+'年'+str(quarter)+'季度'position = get_position(year, quarter, code)position_industry = get_position_industry(position)对应得到的结果为:

对上述结果做柱状图,此处代码续接前文的position_industry。
industry, num = position_industry['所属行业'], position_industry['占净值比例'] / 100plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falseplt.title('持仓所属行业分布')x = np.arange(len(industry))plt.bar(x, num, label=date, tick_label=industry)for i in range(len(num)):plt.text(x[i], num[i] + 0.005, format(num[i], '.2%'))plt.legend()plt.show()对应得到的结果为:
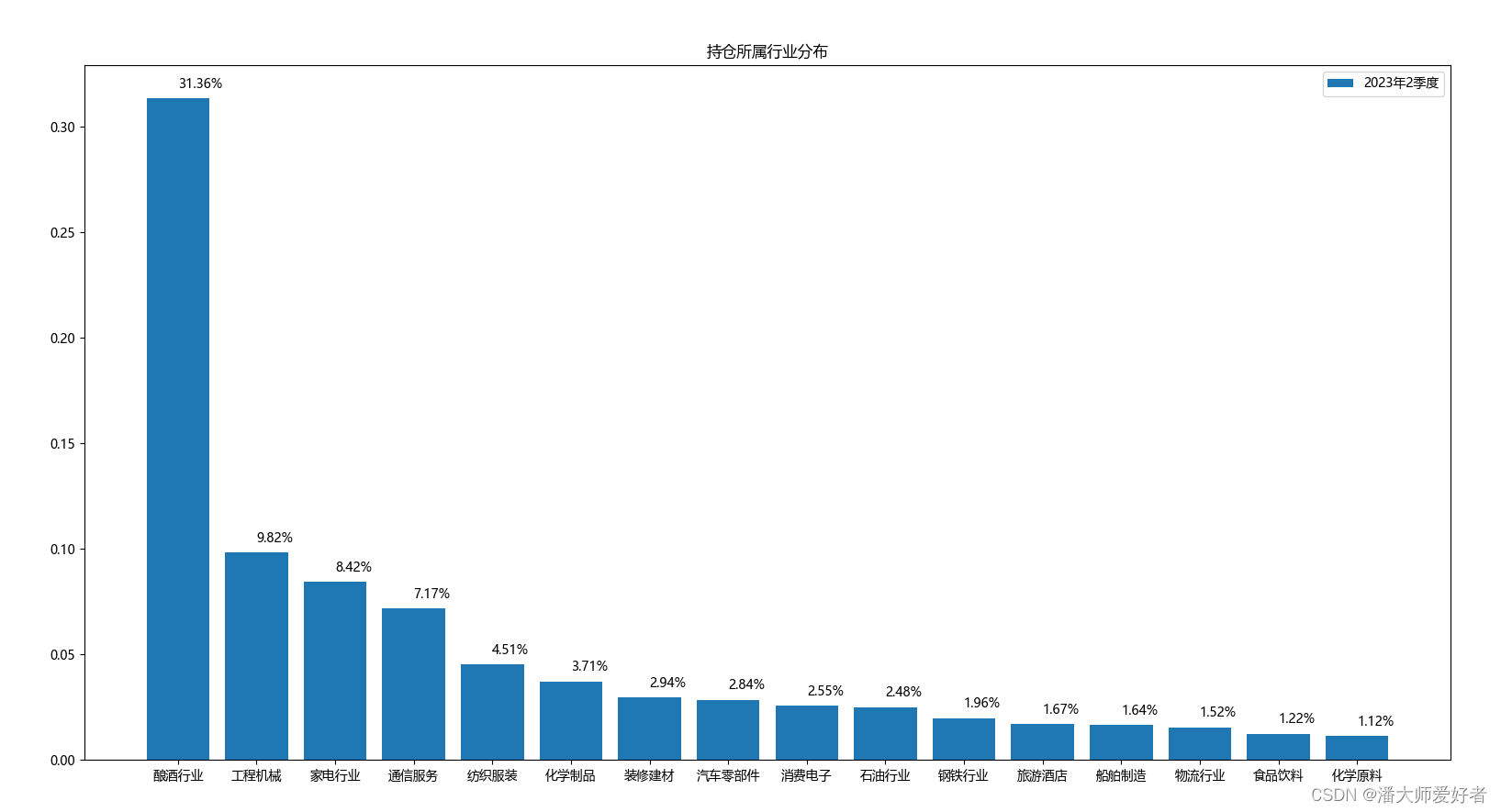
从当期持仓的行业分布来看:1.酿酒行业的持仓占比最高,占净值的比例为31.36%,远高于其他行业。2. 行业覆盖较多,相对比较分散。因此,在行业的分布上,该基金覆盖较多行业,较为分散,重点偏好于酿酒行业。
4. 行业纵向比对
上一节简单分析了2023年2季度的持仓行业分布,属于截面分析。本章节采用纵向分析的思路,分析2023年1季度和2季度持仓行业的变动情况,进一步刻画持仓的行业风格。
if __name__ == '__main__':code = "110009"# 设置年份和季度year, quarter = 2023, 2date = str(year)+'年'+str(quarter)+'季度'position = get_position(year, quarter, code)year1, quarter1 = 2023, 1date1 = str(year1)+'年'+str(quarter1)+'季度'position1 = get_position(year1, quarter1, code)position1_sum = format( position1['占净值比例'].sum()/100,'.2%')position_industry = get_position_industry(position)position_industry1 = get_position_industry(position1)industry_now = pd.DataFrame({'所属行业':position_industry['所属行业'],date+'占比':position_industry['占净值比例']})industry_last = pd.DataFrame({'所属行业':position_industry1['所属行业'],date1+'占比':position_industry1['占净值比例']})# 合并数据me_df = pd.merge(industry_last,industry_now,how='outer',on='所属行业').fillna(0)if __name__ == '__main__':前的代码和第三节的一致。2023年1季度的仓位position1_sum的结果为 55.63%。对应me_df的结果为:
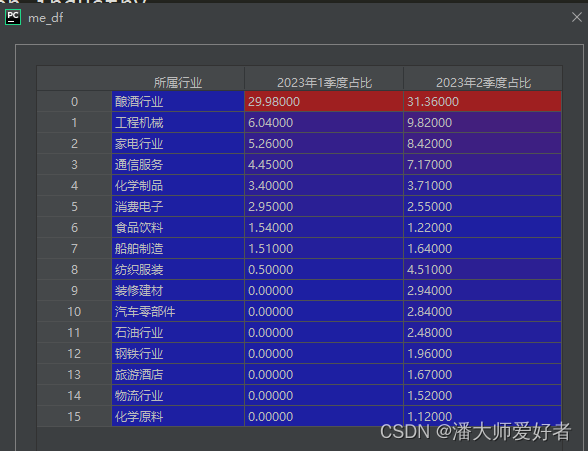
对me_df做可视化的柱状图(代码续接前文me_df):
industry, num = me_df['所属行业'], me_df[date + '占比'] / 100num1 = me_df[date1 + '占比'] / 100plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falseplt.title('持仓所属行业分布')x = np.arange(len(industry))bar_with = 0.3# 柱状图宽度plt.bar(x, num, bar_with,label=date, tick_label=industry)plt.bar(x+bar_with, num1, bar_with,label=date1, tick_label=industry)for i in range(len(num)):plt.text(x[i]-0.2, num[i] + 0.005, format(num[i], '.2%'))plt.text(x[i]+bar_with-0.2, num1[i] + 0.005, format(num1[i], '.2%'))plt.legend()plt.show()对应得到的结果为:
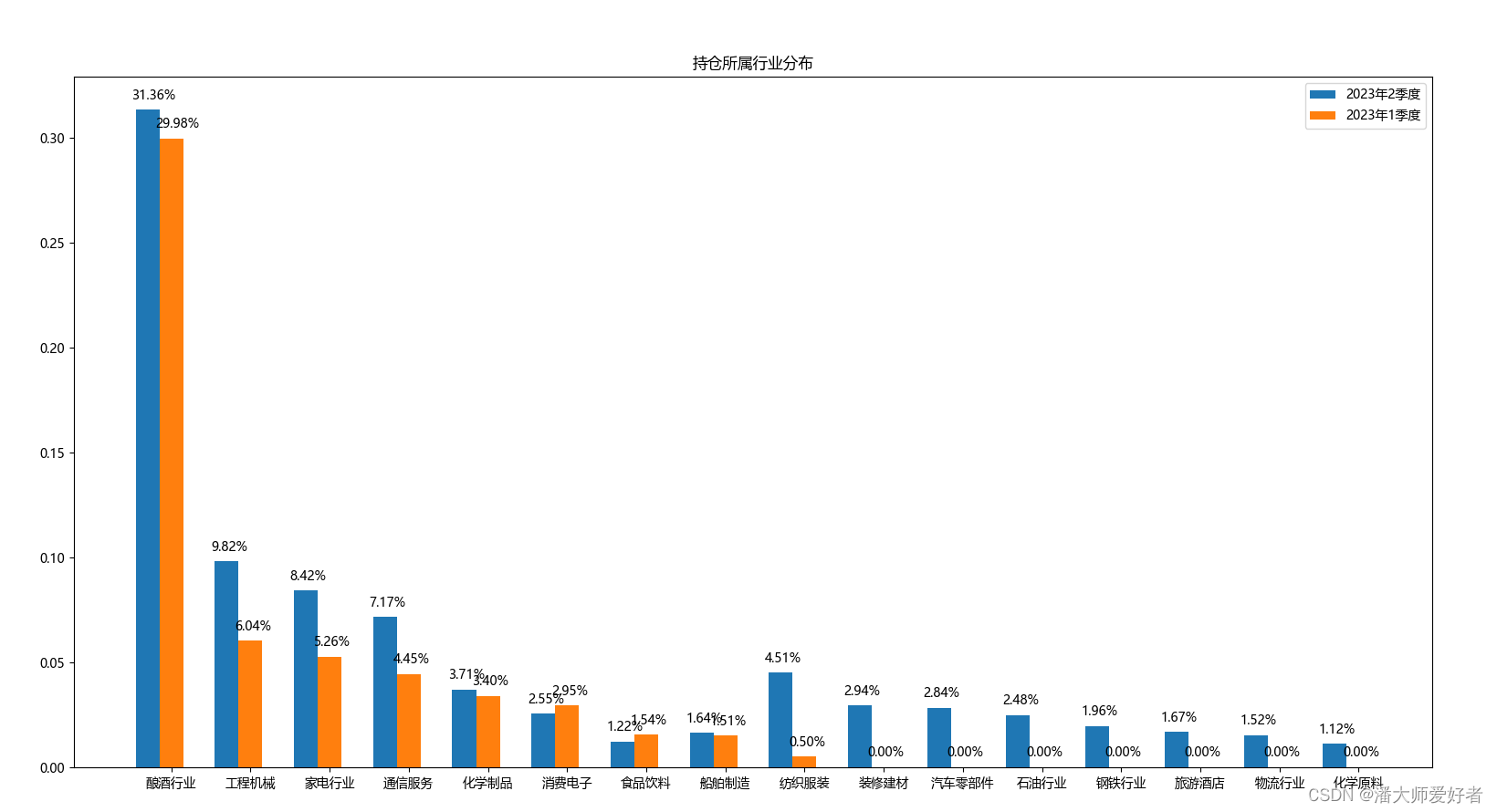
从上图结合相应当季度的仓位, 可以发现:1.第2季度相对1季度进行了加仓,在1季度持仓行业上进行了一调整,同时又加入了新的行业。2.两季度来看,白酒都作为该基金的重点配置行业。结合前文的分析,可以发现:2023年以来,该基金持仓相对分散,偏向于白酒行业;二季度有加仓的行为,加仓时加入了较多新的行业。侧面反映出该基金中长期偏好于白酒,同时对二季度的市场预期相对1季度要更加乐观,但是在行业配置上操作保持谨慎,以分散化的思路为主。
5. 历史总仓位
分析过去两年,该基金每个季度的仓位,同时结合上证指数对应的季度区间的收盘价,判断该基金是否存在仓位上的主动调整。
首先根据年份和季度构造一个函数,提取上证指数对应每个季度末的收盘价。然后获取相应每个季度末对应的总仓位。
import akshare as ak
import pandas as pddef get_position(year, quarter, code):# 获取某年某季度的持仓date_str = str(year) + '年' + str(quarter) + '季度股票投资明细'# 获取对应时间节点的持仓fund_position = ak.fund_portfolio_hold_em(symbol=code, date=str(year))fund_position = fund_position.loc[fund_position['占净值比例'] != 0]position = fund_position.loc[fund_position['季度'] == date_str]return positiondef get_index_close(time):# 获取上证指数的收盘价data = ak.stock_zh_index_daily_em(symbol='sh000001')data['year'] = data['date'].apply(lambda x: pd.to_datetime(x).year)data['month'] = data['date'].apply(lambda x: pd.to_datetime(x).month)all_df = pd.DataFrame()for num in time:year, quarter = num[0], num[1]date = str(year) + '-' + str(quarter * 3)new_data = data.loc[(data['year'] == year) & (data['month'] == quarter * 3)]day = new_data['date'].max()price = new_data.loc[new_data['date'] == day]['close'].values[0]one_df = pd.DataFrame({'时间节点': [date], '上证指数收盘价': [price]})all_df = all_df.append(one_df)return all_dfdef get_position_sum(code, time):# 获取一段时间内基金逐个季度末的总仓位all_df = pd.DataFrame()for num in time:year, quarter = num[0], num[1]date = str(year) + '-' + str(quarter * 3)position = get_position(year, quarter, code)position_sum = position['占净值比例'].sum() / 100one_df = pd.DataFrame({'时间节点': [date], '总仓位': [position_sum]})all_df = all_df.append(one_df)return all_dfif __name__ == '__main__':code = "110009"time = [[2021, 1], [2021, 2], [2021, 3], [2021, 4],[2022, 1], [2022, 2], [2022, 3], [2022, 4],[2023, 1], [2023, 2]]position_sum = get_position_sum(code, time)index = get_index_close(time)me_df = pd.merge(position_sum,index,how='inner',on='时间节点')对应的结果为:
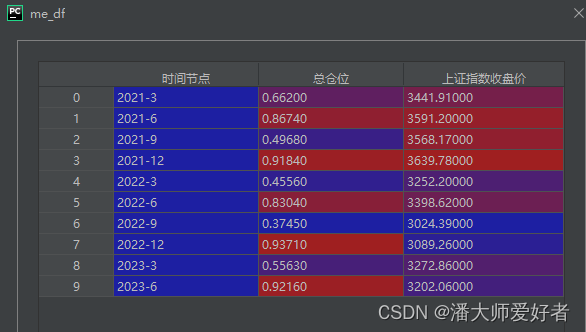
为了节约时间,此处不再使用程序作图,直接用excel,对应结果如下:
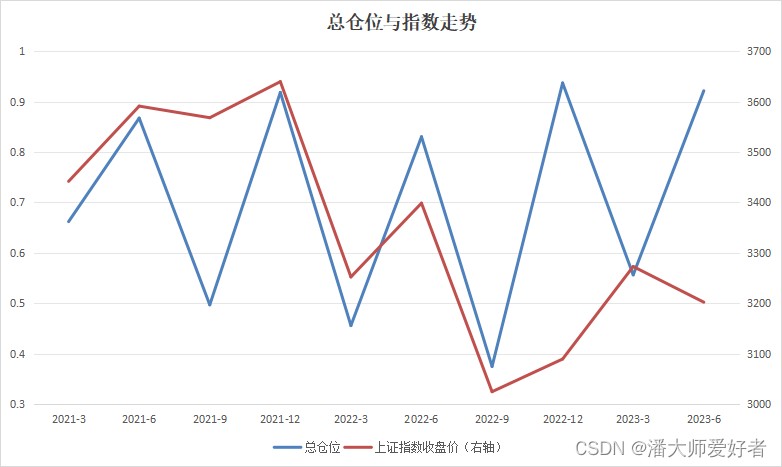
从上图可以看出:2021年初到2022年末,该基金仓位会随着指数的变动 而进行主动的调整,而且是基于一个正向的调整,即指数上涨加仓,指数下跌减仓。2023年开始,操作有所转变:指数上涨减仓,下跌加仓。这是一个比较有意思的现象。笔者猜测是投资经理在2023年初由于仓位较高,因此在后续进行了仓位的控制,而后因为第一季度指数上涨较多,因此二季度相对乐观,又继续加仓(以上仅为推测)。但是基于22年前后的数据,可以推断出该基金在仓位控制上的风格发生了转变,这一点是比较明显的。
6. 特别强调
基金的季度持仓一般在该季度末后N个交易日公告,因此数据存在滞后,因此此方法只是对过去某一节点基金持仓的大概分析,不可过度依赖。
此方法只是基础性的探究,在这个方向还有许多深入性的研究方法,有兴趣可以进一步研究;笔者精力和能力有限,后续不再进行深入性的探讨分享。
每个投资者都有自己的风险收益偏好,因此,持仓分析的结果并不是为了判断基金表现的好坏,仅是对其持仓风格做一个评价,期望能在遴选基金(符合自身偏好)这个层面上,提供一些帮助。
本期分享结束,有和问题欢迎交流。
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的基金仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。
这篇关于基金评价专题5:公募基金持仓分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







