本文主要是介绍SLS机器学习最佳实战:根因分析(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为何需要根因分析?
当某个宏观的监控指标发生异常时,如果能快速定位到具体是那个细粒度的指标发生了异常而导致的。具体来说,当某个流量发生了异常,具体如图中所示:
这个指标就对应是某个小时级别的流量情况,我们要快速定位到2018-09-02 20:00:00 具体发生了什么问题而导致流量突增的?
如何在平台中分析?
- 原始数据格式

在给定的LogStore中一共存在14天的各个粒度的流量数据,其中涉及的维度为 leaf=(dim1, dim2, dim3, dim4, dim5),在每个时刻,一个leaf节点有一个对应的流量值value,在相同时刻,流量对应有可加性。
- 异常区间分析

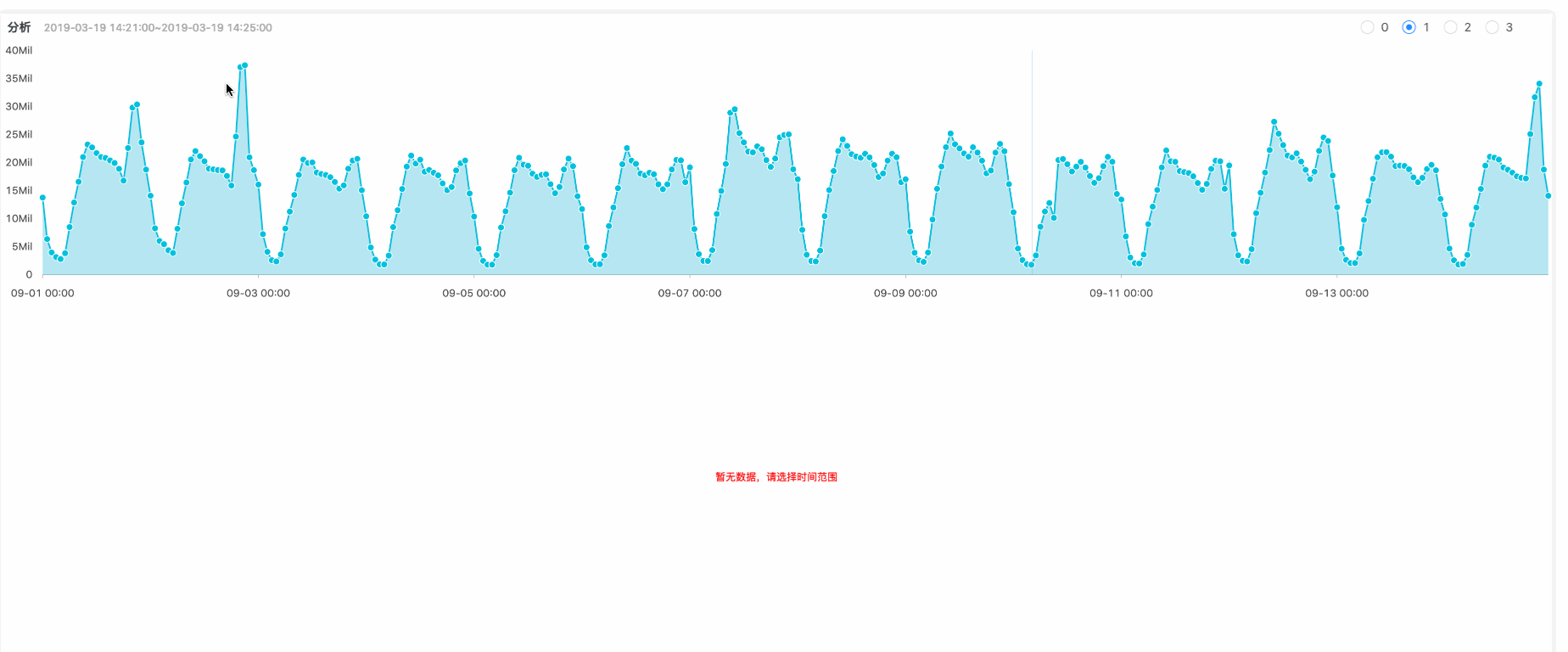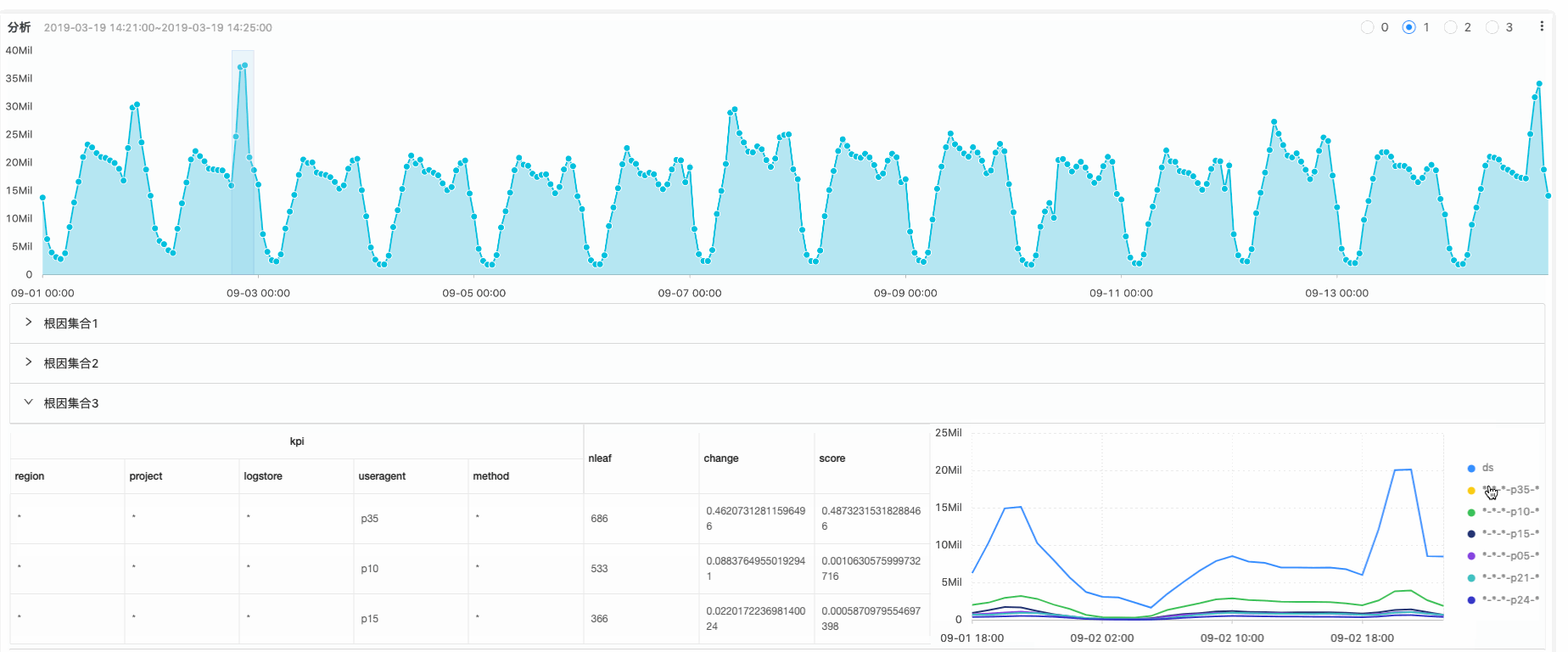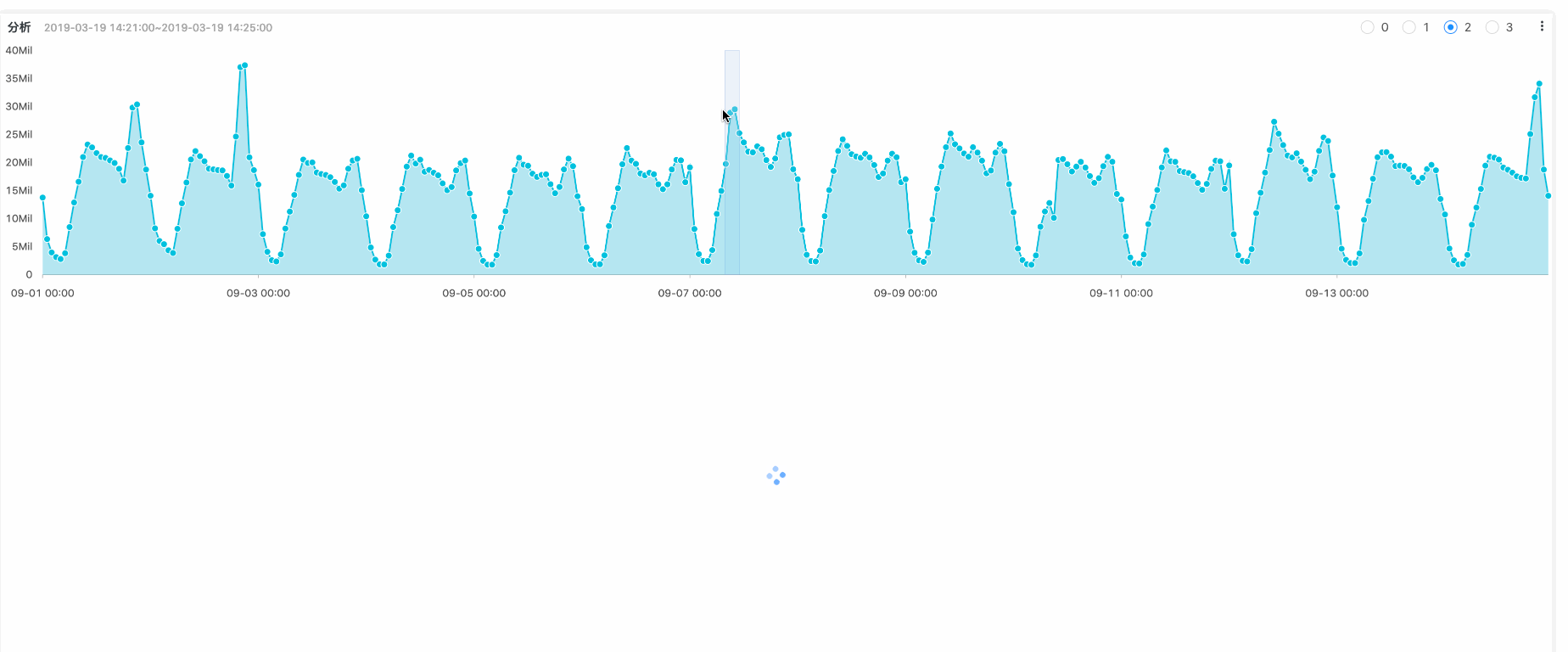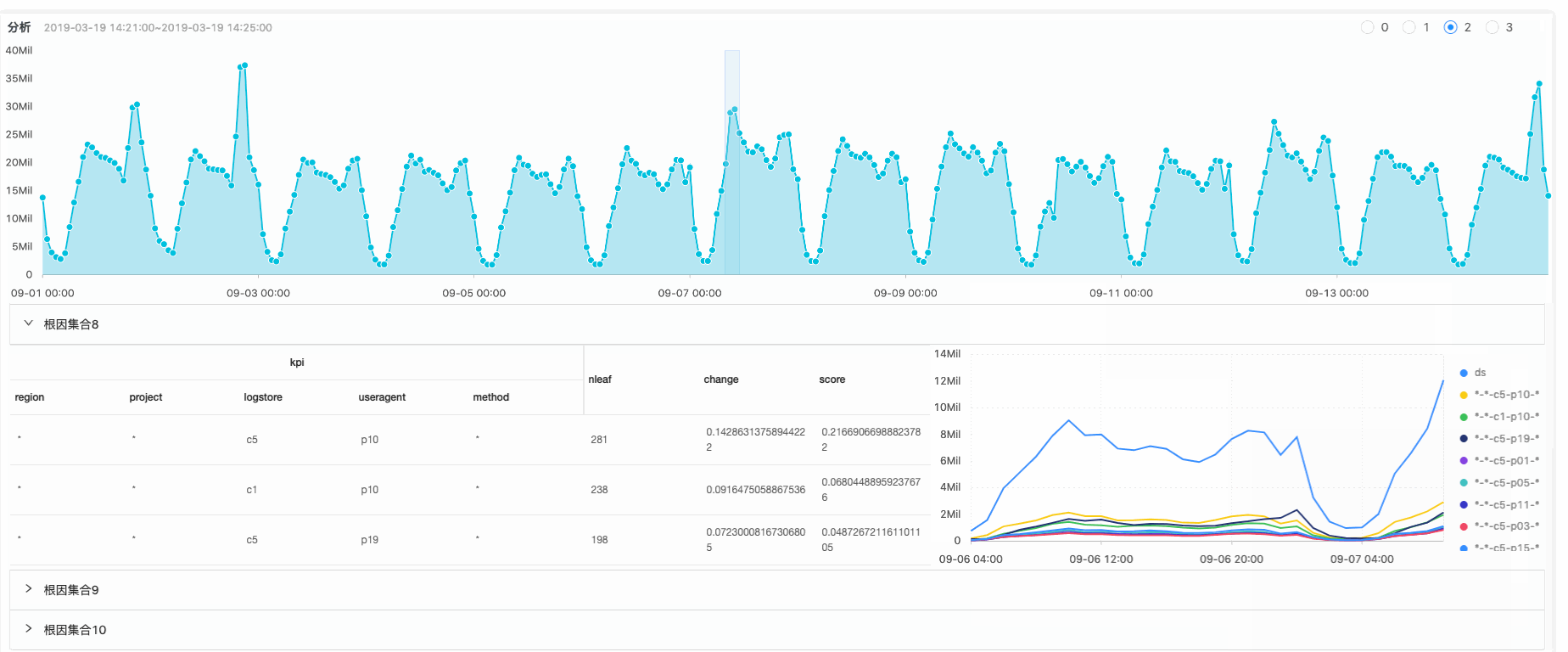
我们在图中,绘制某个异常的区间,算法就会去分析从数据:[起始时刻,异常区间的右边界],遍历所有可能,找到导致该异常的集合。
在上图中,红色框部分,展示的所找到的候选集合中各个子元素对应的时序图,其中ds表示当前根因集合对应的整体趋势信息,其它为根因集合中对应的各个元素的时序曲线。对图中各个含义进行说明:
- 具体的调用形式(仅仅事例,展示调用形式)
* not Status:200 |
select rca_kpi_search(array[ ProjectName, LogStore, UserAgent, Method ],array[ 'ProjectName', 'LogStore', 'UserAgent', 'Method' ], real, forecast, 1)
from (
select ProjectName, LogStore, UserAgent, Method,sum(case when time < 1552436040 then real else 0 end) * 1.0 / sum(case when time < 1552436040
then 1 else 0 end) as forecast,sum(case when time >=1552436040 then real else 0 end) *1.0 / sum(case when time >= 1552436040
then 1 else 0 end) as realfrom (
select __time__ - __time__ % 60 as time, ProjectName, LogStore, UserAgent, Method, COUNT(*) as real
from log GROUP by time, ProjectName, LogStore, UserAgent, Method )
GROUP BY ProjectName, LogStore, UserAgent, Method limit 100000000)使用流程
根因分析演示 PlayGround 地址
硬广时间
日志进阶
阿里云日志服务针对日志提供了完整的解决方案,以下相关功能是日志进阶的必备良药:
- 机器学习语法与函数: https://help.aliyun.com/document_detail/93024.html
- 日志上下文查询:https://help.aliyun.com/document_detail/48148.html
- 快速查询:https://help.aliyun.com/document_detail/88985.html
- 实时分析:https://help.aliyun.com/document_detail/53608.html
- 快速分析:https://help.aliyun.com/document_detail/66275.html
- 基于日志设置告警:https://help.aliyun.com/document_detail/48162.html
- 配置大盘:https://help.aliyun.com/document_detail/69313.html
更多日志进阶内容可以参考:日志服务学习路径。
联系我们
纠错或者帮助文档以及最佳实践贡献,请联系:悟冥
问题咨询请加钉钉群:

这篇关于SLS机器学习最佳实战:根因分析(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





