本文主要是介绍中医药领域的问题生成,阿里天池算法大赛Top1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:机器学习AI算法工程
本文约1700字,建议阅读5分钟
任务是中医药领域的问题生成挑战,而问题生成属于NLG中重要的一种应用。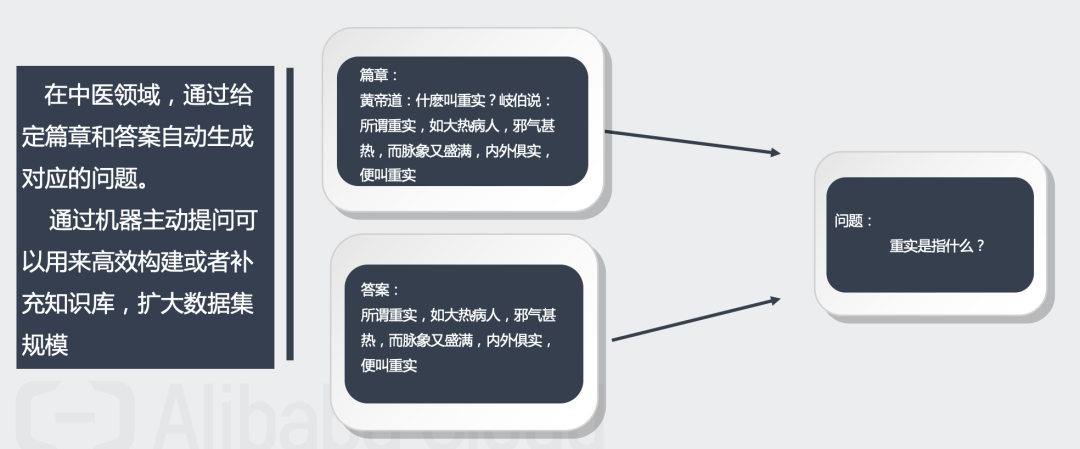
问题生成任务需要我们根据篇章及对应的答案自动生成相应的问题,即“篇章+答案→问题”这样的流程。
训练集由三个字段(篇章、问题、答案)构成,测试集由两个字段(篇章、答案)构成,其中的问题字段需要我们生成。
根据以上分析,我们可以采用Seq2Seq模型来端到端地实现问题生成,而模型的输入为篇章和答案,输出为问题。
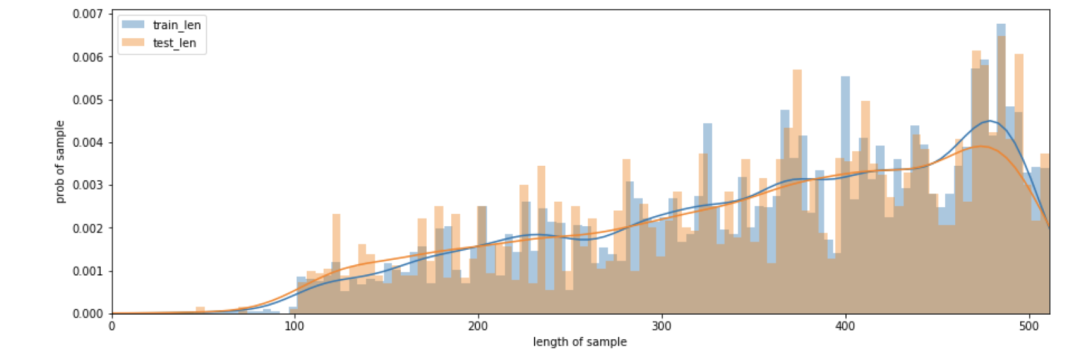
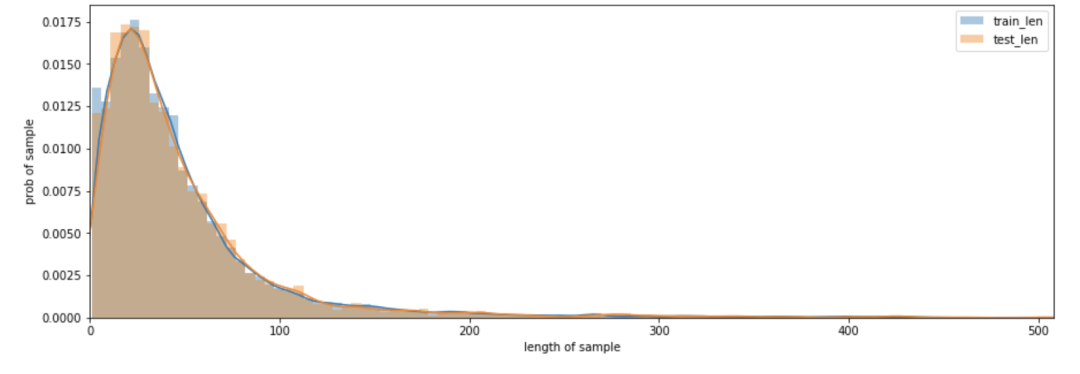
文本长度分布
篇章文本长度在100以下的数据较少,长度区间400-500的数据占比较大。
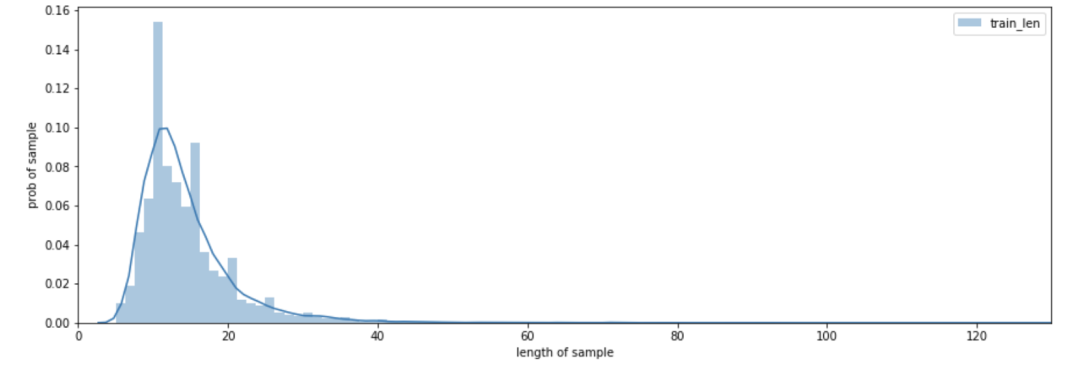
问题文本长度主要集中在5-20这个区间,长度40以上的数据较少。
答案文本长度主要集中在1-100区间,长度200以上的数据较少。
分析总结
训练数据量适中,不是很大数据量,但是也不算少。
文本长度:篇章文本最大,其次是答案文本,最后是问题文本。
如果只看答案文本,那它的长度分布应该是同分布。
若要将篇章、问题和答案拼接进行训练,则需要对其进行文本截断;
问题是要预测的部分,并且长度不是太长,所以可以不进行截断;
答案是从篇章中截取的,可以适当截取短一点;
篇章在硬件资源允许的范围内,可以尽量截取长一点。
核心思路
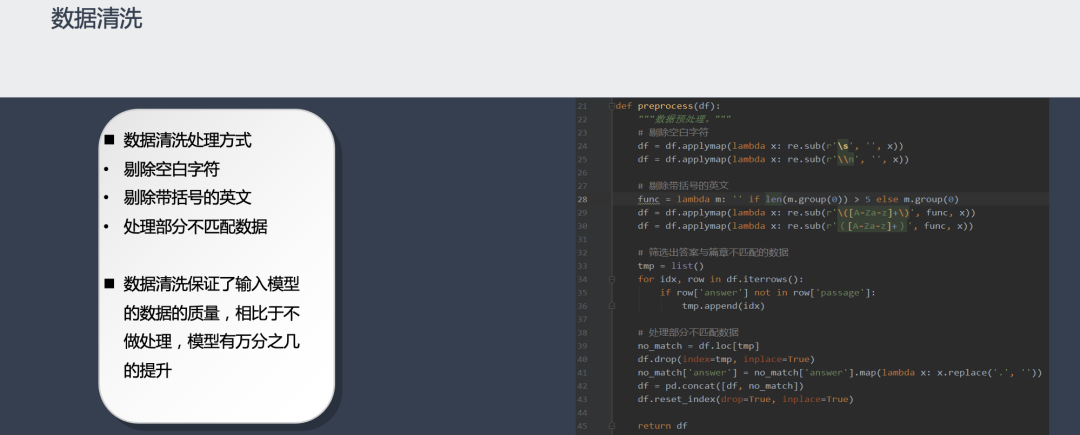
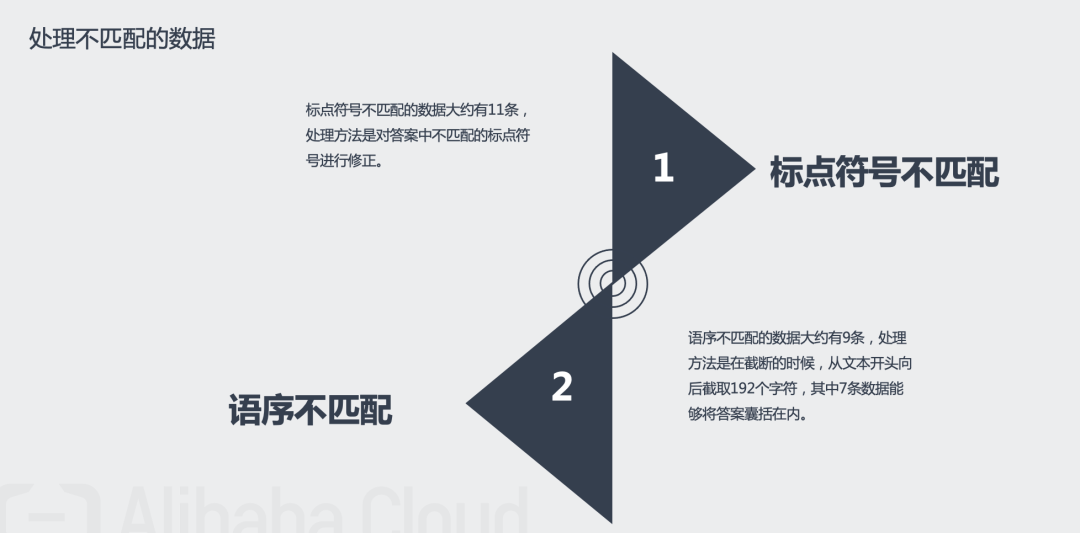
数据预处理:数据清洗(剔除空白字符、剔除带括号的英文),处理部分不匹配数据(绝大部分答案是从篇章中截取的,不匹配数据指答案在篇章中无法完全匹配到的数据);
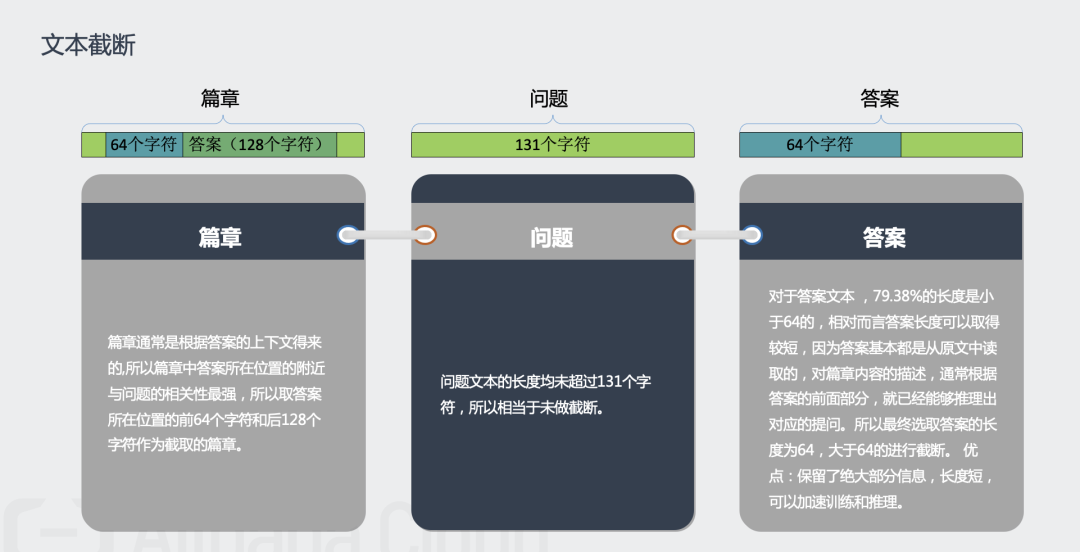
文本截断:思路是篇章中答案所在位置的附近与问题的相关性最强,答案的前面部分信息最多,问题文本最长131个字符。具体操作是篇章取答案所在位置的前64个字符和后128个字符;答案取前64个字符;问题取前131个字符。
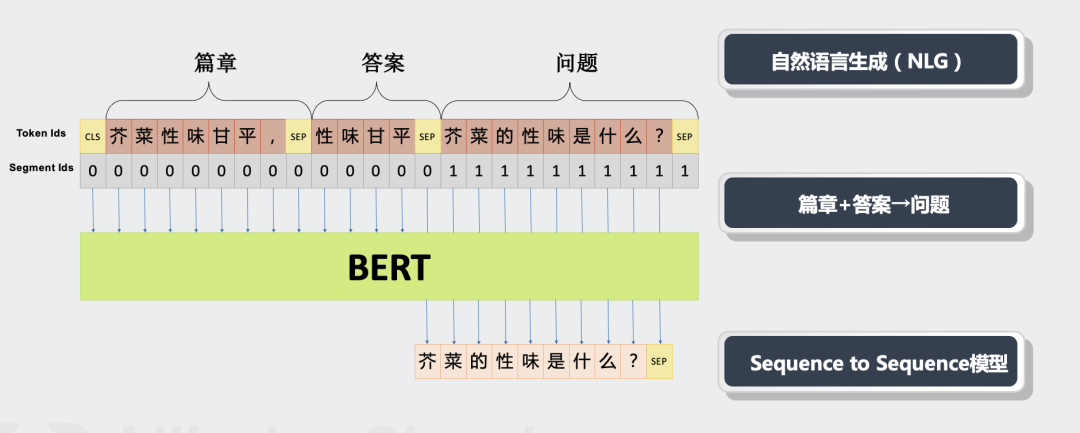
数据输入:训练时按照“[CLS]篇章[SEP]答案[SEP]问题[SEP]”格式输入。推断时按照“[CLS]篇章[SEP]答案[SEP]”格式输入。如图1所示。
模型架构:使用“NEZHA + UniLM”的方式来构建一个Seq2Seq模型,端到端地实现“篇章 + 答案 → 问题”。如图2所示。
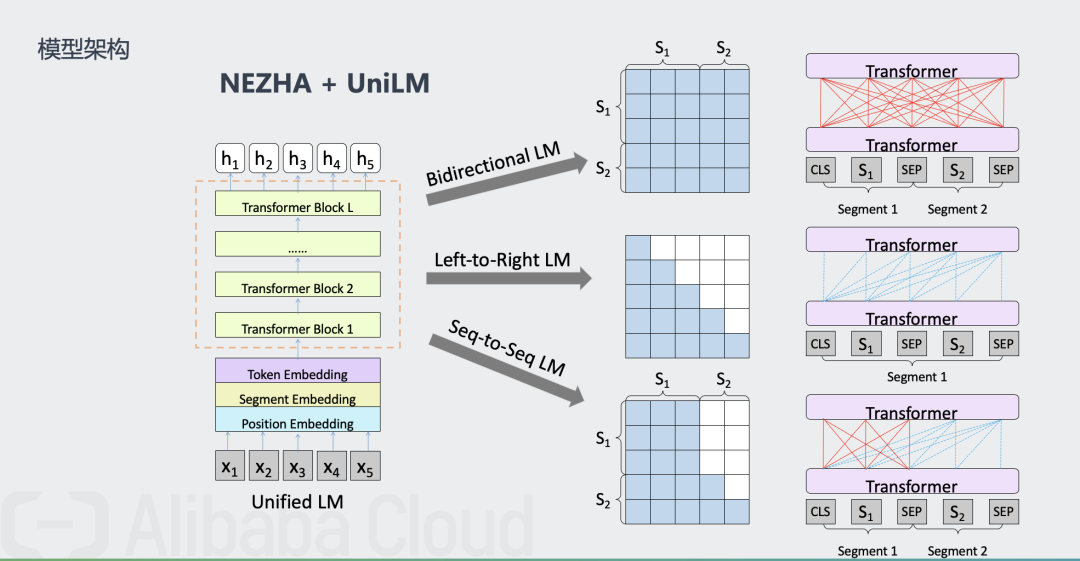
UniLM也是一个多层Transformer网络,跟bert类似,但是UniLM能够同时完成三种预训练目标,如上述表格所示,几乎囊括了上述模型的几种预训练方式,而且新增了sequence-to-sequence训练方式,所以其在NLU和NLG任务上都有很好的表现。UniLM模型基于mask词的语境来完成对mask词的预测,也是完形填空任务。对于不同的训练目标,其语境是不同的。
1.单向训练语言模型,mask词的语境就是其单侧的words,左边或者右边。
2.双向训练语言模型,mask词的语境就是左右两侧的words。
3.Seq-to-Seq语言模型,左边的seq我们称sourcesequence,右边的seq我们称为target sequence,我们要预测的就是target sequence,所以其语境就是所有的source sequence和其左侧已经预测出来的target sequence。
优势:
1.三种不同的训练目标,网络参数共享。
2.正是因为网络参数共享,使得模型避免了过拟合于某单一的语言模型,使得学习出来的模型更加general,更具普适性。
3.因为采用了Seq-to-Seq语言模型,使得其在能够完成NLU任务的同时,也能够完成NLG任务,例如:抽象文摘,问答生成。
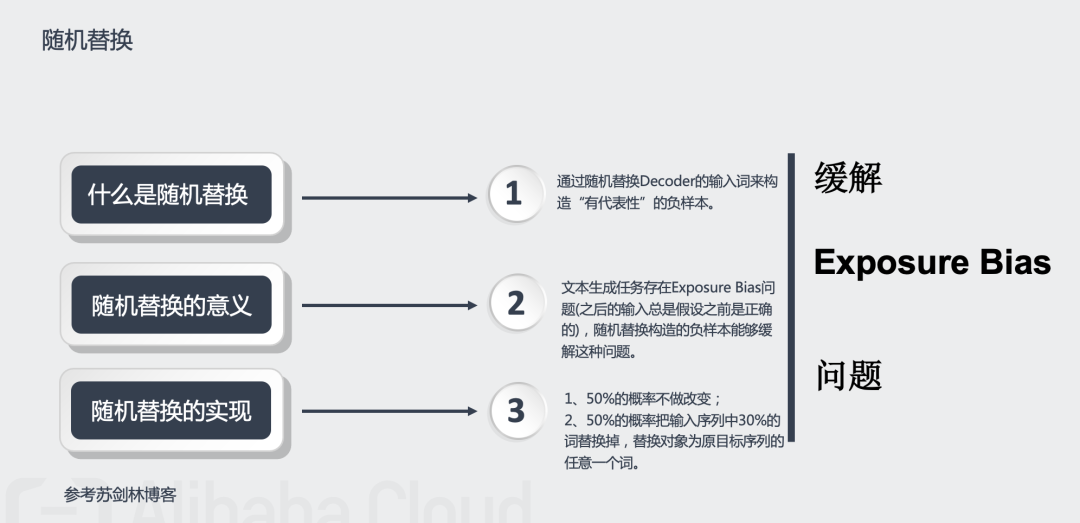
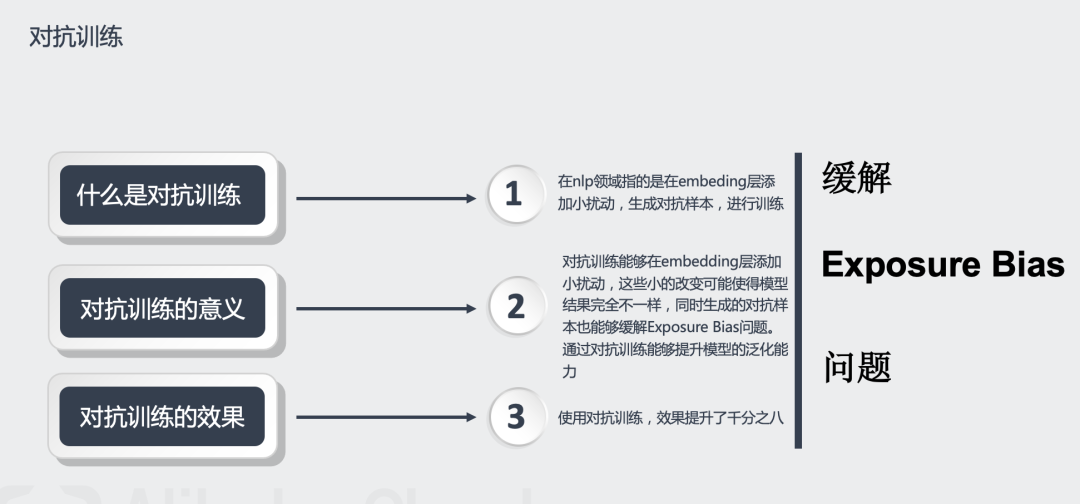
缓解Exposure Bias问题的策略:1.通过随机替换Decoder的输入词来构造“有代表性”的负样本;2.使用对抗训练来生成扰动样本。
解码:使用Beam search来对问题进行解码。
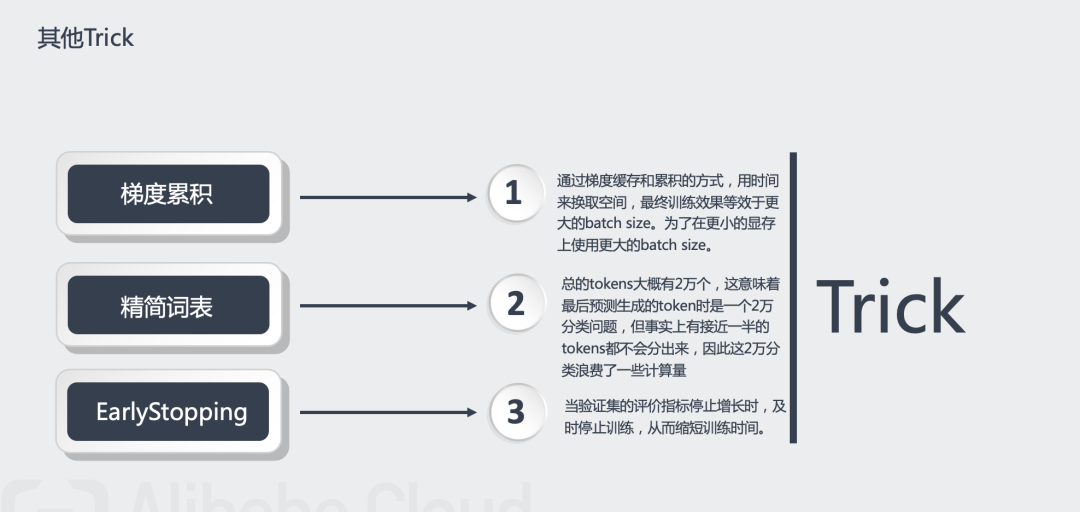
解决显存不足的方法:由于显存有限,无法使用较大的batch size进行训练,梯度累积优化器可以使用小的batch size实现大batch size的效果——只要你愿意花n倍的时间,可以达到n倍batch size的效果,而不需要增加显存。
其他Trick:
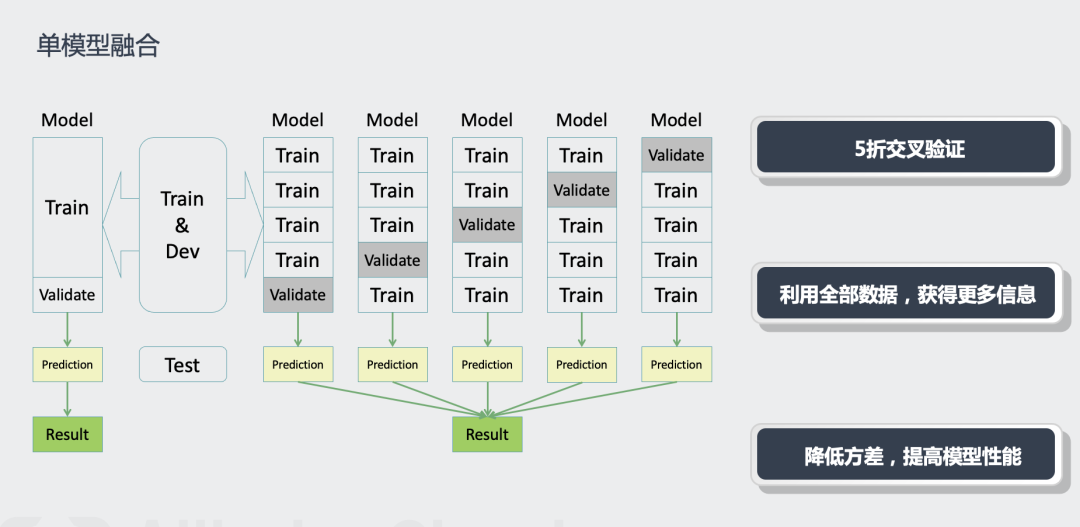
在单模型(NEZHA-Large-WWM)上使用5折交叉验证。
对词表进行精简(因为总的tokens大概有2万个,这意味着最后预测生成的token时是一个2万分类问题,但事实上有接近一半的tokens都不会分出来,因此这2万分类浪费了一些计算量)。
EarlyStopping。
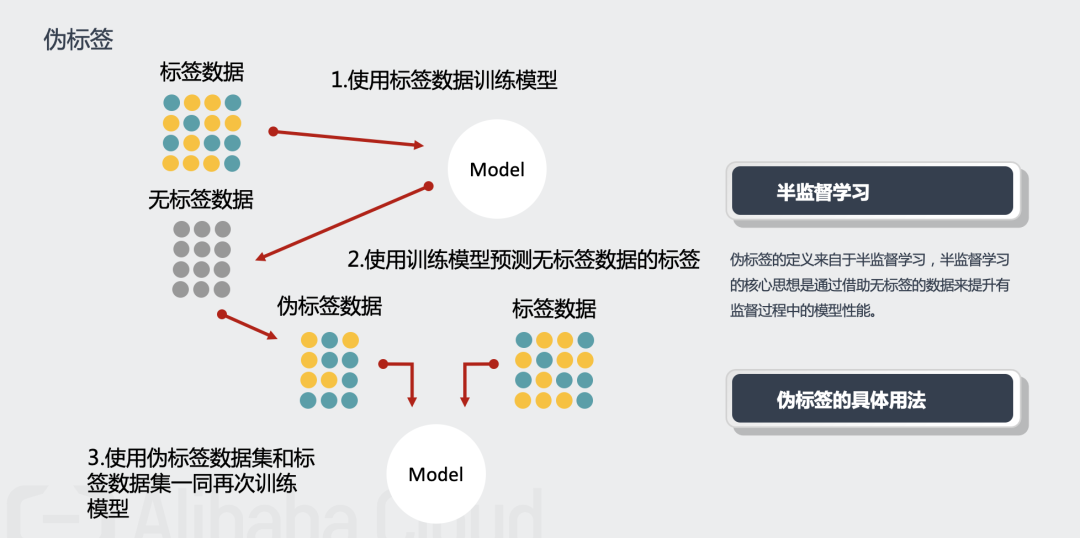
伪标签。
经验总结
文本截断策略使得文本能够在满足预训练模型输入的要求下,较少的损失上下文信息,提分效果显著。使用该文本截断策略之前,一直无法提升至0.6+。
nezha-large-wwm预训练模型是我们队试过效果是最好的模型,单个的nezha-large-wwm加上之前的技巧就能达到0.64+。nezha-base、nezha-base-wwm和wobert在该任务上效果相差不多,大约0.63+,roberta-wwm-large-ext、bert-wwm-ext大约0.62+。
使用随机替换和对抗训练能够缓解Exposure Bias,使用这两个trick后效果提升也比较明显,大约有百分之二提升。
不使用交叉验证,不划分验证集的情况下,使用全部训练数据进行训练,大约第12个epoch效果最好。使用交叉验证后效果会优于全量训练的结果,缺点是训练推断时间太长。
伪标签是一个比较常用的trick,在该生成任务上,使用伪标签有细微的提升,大约万分之二左右。
梯度累积使得能够用较大的batch size训练large模型,分数上也有细微的提升。
编辑:于腾凯这篇关于中医药领域的问题生成,阿里天池算法大赛Top1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







