本文主要是介绍猿创征文|分布式国产数据库 TiDB 从入门到实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
本文讲解的是目前欢迎程度最高分布式国产数据库 TiDB,详细讲解了 TiDB 的由来、架构、SQL 基本操作、SpringBoot 整合 TiDB 等内容。
目录
- 写在前面
- 一、概述
- 二、与 MySQL 兼容性对比
- 三、安装使用
- 四、SQL 基本操作
- 4.1、库操作
- 4.2、表操作
- 4.3、索引操作
- 4.4、用户操作
- 五、SpringBoot 整合
一、概述

TiDB 是 PingCAP 公司使用 Go 语言自主设计、研发的开源分布式关系型数据库,它基于 Google 公司的 Google Spanner / F1 论文设计的开源分布式数据库,是一款结合了传统的关系型数据库和 NoSQL数据库特性的新型分布式数据库。
TiDB 自开源后受到广泛的关注和讨论,至今其 GitHub 项目已经超过 32k多个star 和 5k多的fork 。
TiDB 作为国产新兴数据库,与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
如下是 TiDB 数据库的架构图:

- TiDB Server: SQL 层。负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。
- PD (Placement Driver) Server: 整个 TiDB 集群的大脑。负责调度 TiKV 节点,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
- Storage(存储节点):存储节点分为 TiKV 和 TiFlash。
- TiKV: 负责存储数据,数据行存的,对有事务需求的数据友好。
- TiFlash: 列式存储,对于统计分析友好。可以将统计查询,经常做暴力扫描类型的业务数据存入TiFlash。
二、与 MySQL 兼容性对比
目前大多数企业项目使用的数据库为MySQL数据库,对于与 MySQL 兼容性的支持是非常重要的。
TiDB 高度兼容 MySQL 5.7 协议、MySQL 5.7 常用的功能及语法。MySQL 5.7 生态中的系统工具 (PHPMyAdmin、Navicat、MySQL Workbench、mysqldump、Mydumper/Myloader)、客户端等均适用于 TiDB。
高度兼容的同时,也有一些不支持的功能特性。大家在使用时,一定要非常注意的地方。
- 存储过程与函数
- 触发器
- 事件
- 自定义函数
- 外键约束
- 全文语法与索引
- 空间类型的函数(即
GIS/GEOMETRY)、数据类型和索引 - 非
ascii、latin1、binary、utf8、utf8mb4、gbk的字符集 - SYS schema
- MySQL 追踪优化器
- XML 函数
- X-Protocol
- Savepoints
- 列级权限
XA语法(TiDB 内部使用两阶段提交,但并没有通过 SQL 接口公开)CREATE TABLE tblName AS SELECT stmt语法CHECK TABLE语法CHECKSUM TABLE语法REPAIR TABLE语法OPTIMIZE TABLE语法HANDLER语句CREATE TABLESPACE语句
大家在对技术选型,或者技术更迭的时候,一定要做好充分的兼容测试,尽可能的避免在中途出现不可控的问题。
三、安装使用
目前 TiDB 仅支持 macOS 和 Linux 系统。
注意:使用 Linux 请一定要用
CentOS 7.6及以上系统,我开始使用Ubuntu 22.04 LTS版本,会出现部署不了的情况,也出现部署安装完成后,启动不了,接着切换到CentOS 7.9的系统,可以顺利安装启动。
这里本来想使用Docker Compose方式安装的,但是看官网说仅用于测试,不能用于生产,就放弃使用这种方式了。原文:警告:这仅用于测试,请勿在生产中使用!
环境准备:
- 推荐安装 CentOS 7.6 及以上版本
- 运行环境可以支持互联网访问,用于下载 TiDB 及相关软件安装包
1)、下载并安装 TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
$ curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed
100 7085k 100 7085k 0 0 8205k 0 --:--:-- --:--:-- --:--:-- 8201k
WARN: adding root certificate via internet: https://tiup-mirrors.pingcap.com/root.json
You can revoke this by remove /root/.tiup/bin/7b8e153f2e2d0928.root.json
Successfully set mirror to https://tiup-mirrors.pingcap.com
Detected shell: bash
Shell profile: /root/.bash_profile
/root/.bash_profile has been modified to add tiup to PATH
open a new terminal or source /root/.bash_profile to use it
Installed path: /root/.tiup/bin/tiup
===============================================
Have a try: tiup playground
==============================================
2)、声明全局环境变量
TiUP 安装完成后会提示对应 Shell profile 文件的绝对路径。
我的是:/root/.bash_profile
source /root/.bash_profile
3)、安装 TiUP 的 cluster 组件
tiup cluster
如果机器已经安装 TiUP cluster,需要更新软件版本:
tiup update --self && tiup update cluster
4)、增大 sshd 服务连接数
由于模拟多机部署,需要通过 root 用户调大 sshd 服务的连接数限制:
-
修改
/etc/ssh/sshd_config将MaxSessions调至 20。 -
重启 sshd 服务:
service sshd restart
5)、创建并启动集群
创建目录
mkdir -p /usr/local/tidb
cd /usr/local/tidb/
创建配置文件 topo.yaml。配置模板如下:
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"# # Monitored variables are applied to all the machines.
monitored:node_exporter_port: 9100blackbox_exporter_port: 9115server_configs:tidb:log.slow-threshold: 300tikv:readpool.storage.use-unified-pool: falsereadpool.coprocessor.use-unified-pool: truepd:replication.enable-placement-rules: truereplication.location-labels: ["host"]tiflash:logger.level: "info"pd_servers:- host: 192.168.110.134tidb_servers:- host: 192.168.110.134tikv_servers:- host: 192.168.110.134port: 20160status_port: 20180config:server.labels: { host: "logic-host-1" }- host: 192.168.110.134port: 20161status_port: 20181config:server.labels: { host: "logic-host-2" }- host: 192.168.110.134port: 20162status_port: 20182config:server.labels: { host: "logic-host-3" }tiflash_servers:- host: 192.168.110.134monitoring_servers:- host: 192.168.110.134grafana_servers:- host: 192.168.110.134
user: "tidb":表示通过tidb系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行host:设置为本部署主机的 IP。(更改为自己机器IP)
6)、部署集群
命令格式为:
tiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p
<cluster-name>:需设置的集群名称<tidb-version>:需设置的集群版本。可以通过tiup list tidb命令来查看当前支持部署的 TiDB 版本-p:表示在连接目标机器时使用密码登录
首先使用tiup list tidb命令查看 TiDB 版本
tiup list tidb
我们这里就使用最新稳定版 v6.3.0。
执行集群部署命令:
tiup cluster deploy my-tidb v6.3.0 ./topo.yaml --user root -p
此命令需要在
topo.yaml目录执行
执行后,会提示让你输入 SSH 密码,也就是你的登录密码。
$ tiup cluster deploy my-tidb v6.3.0 ./topo.yaml --user root -p
tiup is checking updates for component cluster ...
Starting component `cluster`: /root/.tiup/components/cluster/v1.11.0/tiup-cluster deploy my-tidb v6.3.0 ./topo.yaml --user root -p
Input SSH password:
然后根据提示,输入 y 后,等待部署完成
Do you want to continue? [y/N]: (default=N)
安装程序跑完后,记得看一下是否所有的组件都成功安装,如果安装失败,根据提示查看日志进行解决。
7)、启动集群
命令格式:
tiup cluster start <cluster-name>
执行命令:
tiup cluster start my-tidb
8)、客户端访问
一定要关闭防火墙在进行测试
使用 Navicat 客户端连接工具,选择MySQL方式连接。连接成功。
使用 SQLyog 也可以连接成功。

9)、Grafana 监控页面
访问地址:
http://IP:3000
默认用户名和密码均为
admin。

10)、TiDB 的 Dashboard
访问地址:
http://IP:2379/dashboard
默认用户名为
root,密码为空。
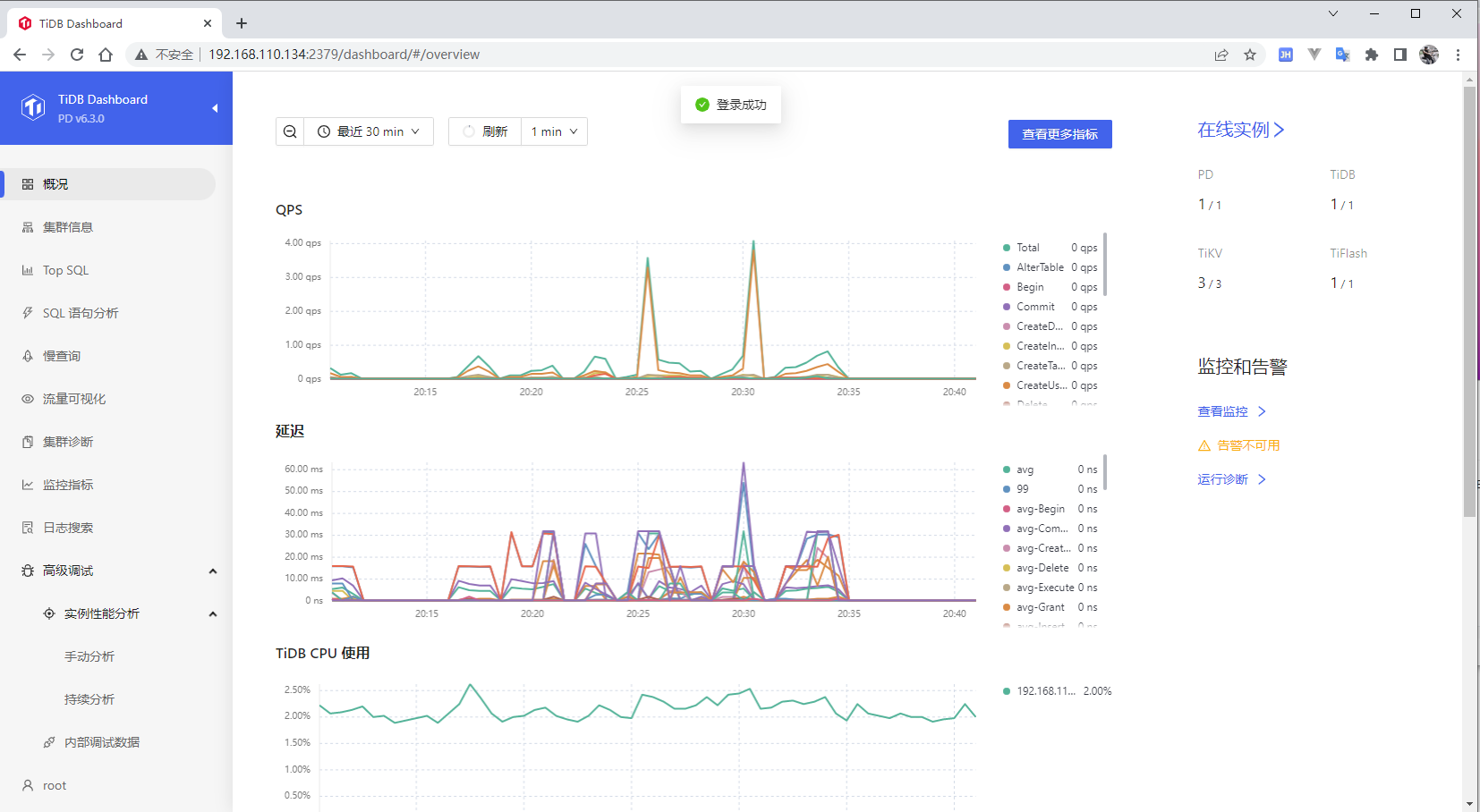
有很多实用的功能,可以查看 QPS、慢查询、流量查询等。可以帮助我们快速的定位问题。
四、SQL 基本操作
安装好 TiDB 后,便可以在 TiDB 中执行 SQL 语句了。我这里直接使用大家常用的 Navicat 进行操作了。
因为 TiDB 兼容 MySQL,我们可以像操作 MySQL 一样操作 TiDB。
4.1、库操作
1)、查看数据库列表
SHOW DATABASES;
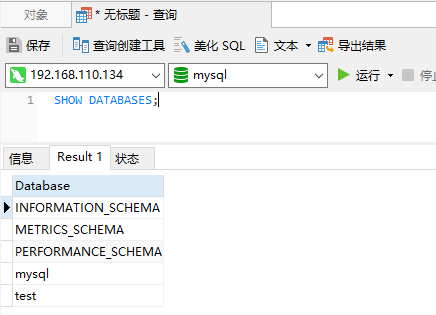
2)、创建数据库
CREATE DATABASE IF NOT EXISTS my_db;
添加 IF NOT EXISTS 可防止发生错误。
3)、切换数据库
USE my_db;
4)、删除数据库
DROP DATABASE my_db;
5)、查看数据库下所有的表
SHOW TABLES FROM my_db;
4.2、表操作
1)、创建表
语法格式:
CREATE TABLE table_name column_name data_type constraint;
创建 sys_user 表
CREATE TABLE sys_user (id INT(11),name VARCHAR(255),birthday DATE
);
2)、删除表
DROP TABLE sys_user;
3)、插入数据
两种方式
INSERT INTO sys_user VALUES(1,'tom','20221008');
INSERT INTO sys_user(id,name) VALUES('2','bob');
4)、查询数据
SELECT * FROM sys_user;
5)、修改数据
UPDATE sys_user SET birthday='20221009' WHERE id=2;
6)、删除数据
DELETE FROM sys_user WHERE id=2;
4.3、索引操作
1)、普通索引
两种方式
CREATE INDEX sys_user_id ON sys_user (id);
ALTER TABLE sys_user ADD INDEX sys_user_id (id);
2)、唯一索引
两种方式
CREATE UNIQUE INDEX sys_user_unique_id ON sys_user (id);
ALTER TABLE sys_user ADD UNIQUE sys_user_unique_id (id);
3)、查看表内索引
SHOW INDEX FROM sys_user;
4)、删除索引
两种方式
DROP INDEX sys_user_id ON sys_user;
ALTER TABLE sys_user DROP INDEX sys_user_unique_id;
4.4、用户操作
1)、创建用户
创建用户 micromaple ,密码 123456
CREATE USER 'micromaple'@'localhost' IDENTIFIED BY '123456';
2)、授权用户
授权用户 micromaple 可检索数据库 my_db 内的表:
GRANT SELECT ON my_db.* TO 'micromaple'@'localhost';
授权所有权限:
GRANT ALL PRIVILEGES ON *.* TO 'micromaple'@'localhost';
3)、查询权限
SHOW GRANTS for micromaple@localhost;
4)、删除用户
DROP USER 'micromaple'@'localhost';
5)、设置用户远程访问
update mysql.user set host = '%' where user = 'micromaple';
FLUSH PRIVILEGES;
五、SpringBoot 整合
TiDB 对于 JDBC 的支持等级是 Full。也就是全量支持。
我们只需要引入 Java JDBC 驱动程序即可使用。
官方说明:强烈建议使用 JDBC 5.1 的最后一个版本 5.1.49。因为当前 8.0.29 版本有未合并的Bug 修复,在与 TiDB 共同使用时可能会导致线程卡死。在 MySQL JDBC 8.0 未合并此修复之前,建议不要升级至 8.0 版本。
Maven 引入依赖
<!-- Junit -->
<dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope>
</dependency>
<!-- Spring Web -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
<!-- MySQL Drivers -->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version>
</dependency>
<!-- JDBC -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- mybatis-plus -->
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version>
</dependency>
<!-- lombok -->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
application.yml 配置:
spring:datasource:driver-class-name: com.mysql.jdbc.Drivertype: com.zaxxer.hikari.HikariDataSourceurl: jdbc:mysql://192.168.110.134:4000/my_db?useUnicode=true&characterEncoding=utf-8&useSSL=trueusername: rootpassword:
启动类增加注解,扫描mapper包
@MapperScan(value = "com.micromaple.tidb.mapper")
SysUser 实体类
package com.micromaple.tidb.domain;import lombok.Data;import java.util.Date;@Data
public class SysUser {/*** 主键ID*/private Integer id;/*** 姓名*/private String name;/*** 生日*/private Date birthday;}
SysUserMapper
package com.micromaple.tidb.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.micromaple.tidb.domain.SysUser;
import org.springframework.stereotype.Repository;@Repository
public interface SysUserMapper extends BaseMapper<SysUser> {}
编写测试类,测试新增和查询
package com.micromaple.tidb;import com.micromaple.tidb.domain.SysUser;
import com.micromaple.tidb.mapper.SysUserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.Date;
import java.util.List;@SpringBootTest(classes = TiDBDemoApplication.class)
@RunWith(SpringRunner.class)
public class SysUserTest {@Autowiredprivate SysUserMapper sysUserMapper;@Testpublic void testAdd() {SysUser sysUser = new SysUser();sysUser.setId(3);sysUser.setName("Micromaple");sysUser.setBirthday(new Date());int i = sysUserMapper.insert(sysUser);if(i > 0){System.out.println("新增成功");}}@Testpublic void testSelect() {List<SysUser> sysUserList = sysUserMapper.selectList(null);for (SysUser sysUser : sysUserList) {System.out.println(sysUser.getName());}}
}
测试成功!!
最大的感触就是跟使用 MySQL 基本没有任何差别,可以使用常用的 ORM 框架,比如:Hibernate、MyBatis等。
官方文档也有提供大量的详细的教程,比如集群部署、数据迁移、运维操作、监控告警等,完备及活跃的社区也给我们开发人员提供了有力的保障。当然确定一款数据库是否适合自己的业务还需要大量测试和实践检验,这是非常重要的。
这篇关于猿创征文|分布式国产数据库 TiDB 从入门到实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







