本文主要是介绍基于matlab统计Excel文件一列数据中每个数字出现的频次和频率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求描述

如上表所示,在excel文件中,有一列数,统计出该列数中,每个数出现的次数和频率。最后,将统计结果输出到新的excel文件中。
二、程序讲解
第一步:选择excel文件;
[Filename, Pathname] = uigetfile('*.xls', '选择所用的雷达数据'); % 获取文件名和路径根据情况,更改为现有的excel后缀名
filePath=[Pathname Filename]; % 存储文件路径第二步:读取excel文件中的一列数据;
data = xlsread(filePath);第三步:统计出现的数字次数;
[counts, edges] = histcounts(data); % counts 统计出现的数字次数第四步:计算数字出现的频率;
frequencies = counts / length(data); % 计算数字出现的频率第五步:汇总结果。
values = (edges(1:end-1) + edges(2:end)) / 2; % 数据数值出现区间
result = [values; counts;frequencies]'; % 汇总统计结果第六步:创建存储excel文件的文件夹;
folder='ExcelFiles'; % 文件夹名称
if exist(folder,'dir')==0 % 判断站点文件夹是否已经存在mkdir(folder); % 不存在,则创建该文件夹
end
Datestr=['.\ExcelFiles\','数据统计结果.xls']; % 存储汇总统计结果的路径及文件名第七步:输入表头;
T1 =table({'原数据'},{'出现频次'},{'出现频率'}); % 表头名称
writetable(T1,Datestr,'Sheet','1','Range','A1:C1','WriteVariableNames', false); % 写入表头第八步:输入统计数据。
T2 = table(result); % 统计结果
RangeNum=['A2:C',num2str(length(data)+1)]; % 确定数据写入区域
writetable(T2,Datestr,'Sheet','1','Range',RangeNum, 'WriteVariableNames', false); % 写入数据三、所有程序
clear all; close all; clc;%% 选取excel文件
[Filename, Pathname] = uigetfile('*.xls', '选择所用的雷达数据'); % 获取文件名和路径根据情况,更改为现有的excel后缀名
filePath=[Pathname Filename]; % 存储文件路径data = xlsread(filePath);[counts, edges] = histcounts(data); % counts 统计出现的数字次数
frequencies = counts / length(data); % 计算数字出现的频率
values = (edges(1:end-1) + edges(2:end)) / 2; % 数据数值出现区间
result = [values; counts;frequencies]'; % 汇总统计结果%% 将统计结果存储到excel文件中
folder='ExcelFiles'; % 文件夹名称
if exist(folder,'dir')==0 % 判断站点文件夹是否已经存在mkdir(folder); % 不存在,则创建该文件夹
end
Datestr=['.\ExcelFiles\','数据统计结果.xls']; % 存储汇总统计结果的路径及文件名% 输入表头
T1 =table({'原数据'},{'出现频次'},{'出现频率'}); % 表头名称
writetable(T1,Datestr,'Sheet','1','Range','A1:C1','WriteVariableNames', false); % 写入表头
% 输入统计数据
T2 = table(result); % 统计结果
RangeNum=['A2:C',num2str(length(data)+1)]; % 确定数据写入区域
writetable(T2,Datestr,'Sheet','1','Range',RangeNum, 'WriteVariableNames', false); % 写入数据运行后,输出的结果,如下表所示: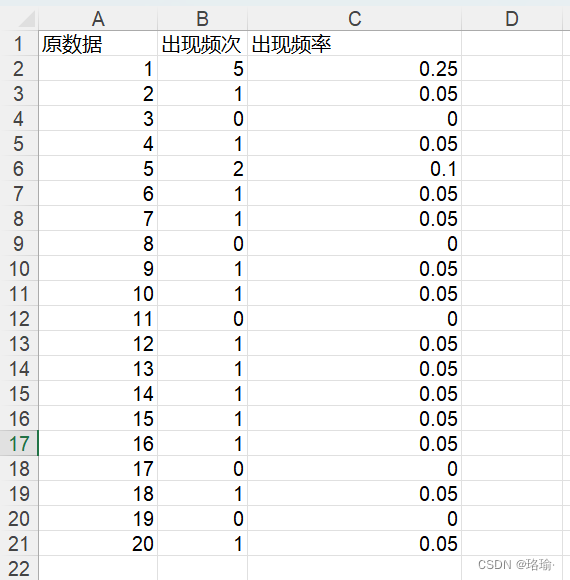
这篇关于基于matlab统计Excel文件一列数据中每个数字出现的频次和频率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





