本文主要是介绍Extract Mass Data Via Bloomberg API,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
个人博客地址 https://mengjiexu.com/post/bloomberg-api/
Motivation
Bloomberg has integrated massive data from various of data vendors. However, as a typical finance terminal designed for traders, it’s technically hard to use as a database for scholars. This blog will introduce how to prepare your Bloomberg Terminal for massive data extracting and how to access data via Bloomberg API.
Deploy Operation Enviornment
Bloomberg Access
-
Get a Bloomberg Terminal and of course a valid Bloomberg Account
-
Make sure the Bloomberg Add-in in Excel in this terminal works
Figure 1: Bloomberg Add-in in Excel
Install Blommberg C++ SDK
-
Visit Bloomberg API Library and downlaod C++ Supported Release
Figure 2: Bloomberg API Library -
Copy
blpapi3_32.dllandblpapi3_64.dllfrom thelibfolder of downloaded zip file (typically namedblpapi_cpp_3.16.6.1-windows.zip) to BloombergBLPAPI_ROOTfolder in the terminal (usuallyC:/blp/DAPI). If any note saying the files would be replaced appears, confirm the replacement.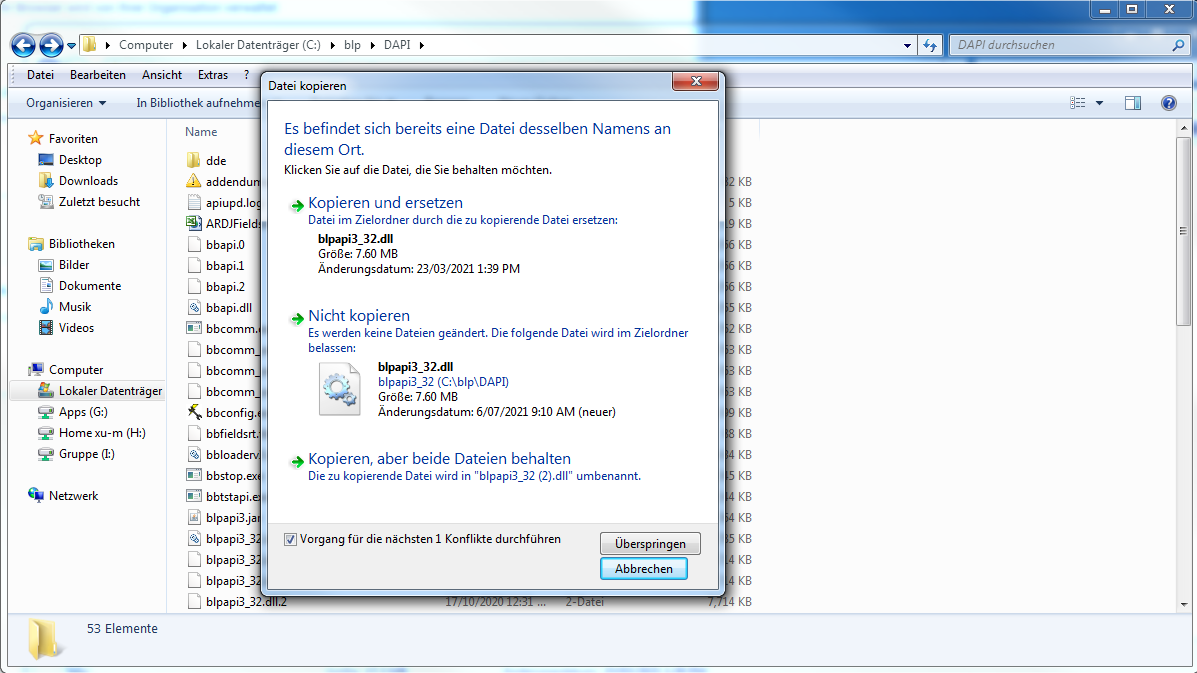
Figure 3: Replace Files in BlPAPI_Root -
Please make sure the Bloomberg App is closed before replacing those two root files.
Install Python/Anaconda
As Anaconda has integrated the majority of most frequently used Python packages, I would recommend installing Anaconda as a shortcut. If you choose to purely install Python, remember to click the option" Add Python into Enviornment Path" when installing to make sure your later procedures easier.
Suppose you’ve already installed Anaconda, launch the cmd from the navigator panel (or directly from the start menu).
Install Necessary Packages
Type the following orders in the cmd window you launched from Anaconda Navigator.
-
Install Bloomberg official Python API
pip install blpapi --index-url=https://bcms.bloomberg.com/pip/simple/ -
Install
numpy,pandas,ruamel.yamlandpayarrow. As Anaconda has integratednumpyandpandas, we only need to install the last two packages.conda install ruamel.yaml conda install pyarrow -
Install a third-party package that enables better data extracting experience
xbbgpip install xbbg
Login in Bloomberg Terminal
This steps activates your access to Bloomberg data and enables the following data extracting.
Test API
Type python in the cmd window, you will enter the Python enviornment. If you enter the following code and get the same result as mine, that means you’ve deployed the operation enviornment for Bloomberg API successfully. All of the following examples are obtained from the Github Page of xbbg.
In [1]: from xbbg import blp
BDP example:
In [2]: blp.bdp(tickers='NVDA US Equity', flds=['Security_Name', 'GICS_Sector_Name'])
Out[2]:security_name gics_sector_name
NVDA US Equity NVIDIA Corp Information Technology
BDP with overrides:
In [3]: blp.bdp('AAPL US Equity', 'Eqy_Weighted_Avg_Px', VWAP_Dt='20181224')
Out[3]:eqy_weighted_avg_px
AAPL US Equity 148.75
BDH example:
In [4]: blp.bdh(...: tickers='SPX Index', flds=['high', 'low', 'last_price'],...: start_date='2018-10-10', end_date='2018-10-20',...: )
Out[4]:SPX Indexhigh low last_price
2018-10-10 2,874.02 2,784.86 2,785.68
2018-10-11 2,795.14 2,710.51 2,728.37
2018-10-12 2,775.77 2,729.44 2,767.13
2018-10-15 2,775.99 2,749.03 2,750.79
2018-10-16 2,813.46 2,766.91 2,809.92
2018-10-17 2,816.94 2,781.81 2,809.21
2018-10-18 2,806.04 2,755.18 2,768.78
2018-10-19 2,797.77 2,760.27 2,767.78
BDH example with Excel compatible inputs:
In [5]: blp.bdh(...: tickers='SHCOMP Index', flds=['high', 'low', 'last_price'],...: start_date='2018-09-26', end_date='2018-10-20',...: Per='W', Fill='P', Days='A',...: )
Out[5]:SHCOMP Indexhigh low last_price
2018-09-28 2,827.34 2,771.16 2,821.35
2018-10-05 2,827.34 2,771.16 2,821.35
2018-10-12 2,771.94 2,536.66 2,606.91
2018-10-19 2,611.97 2,449.20 2,550.47
An Example : Extract ESG Disclosure Scores
Suppose we want to extract the ESG Disclosure Score for a list of 8000 securities via API. A very first obstacle is that we have no idea what does this variable is named in API and which function we should use to request the data. Thus, the first step is to obtain all those information you demand by building an example spreadsheet through Bloomberg Excel Add-in.
Get The Function Name and Key Parameters
Click the Spreadsheet Builder in Bloomberg Excel Add-in. Click Historical Data Table.
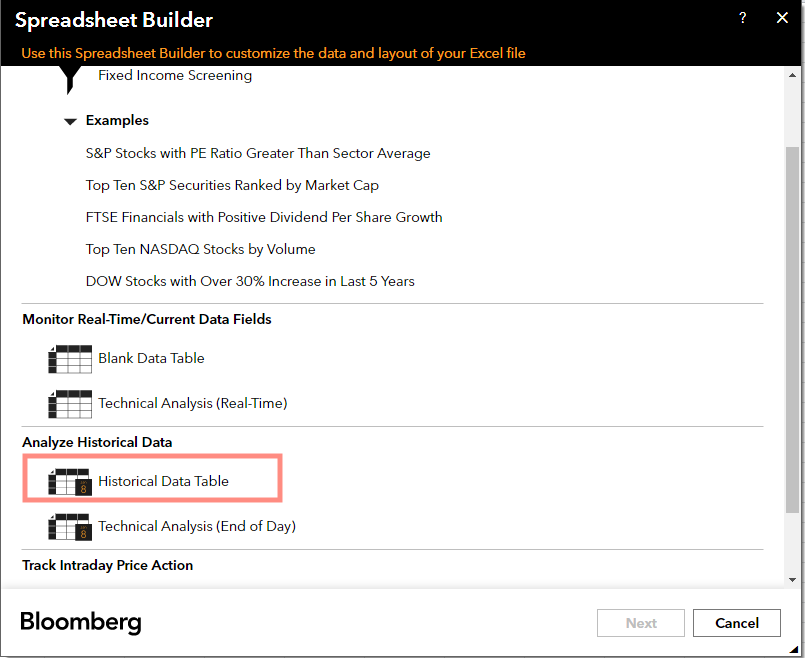
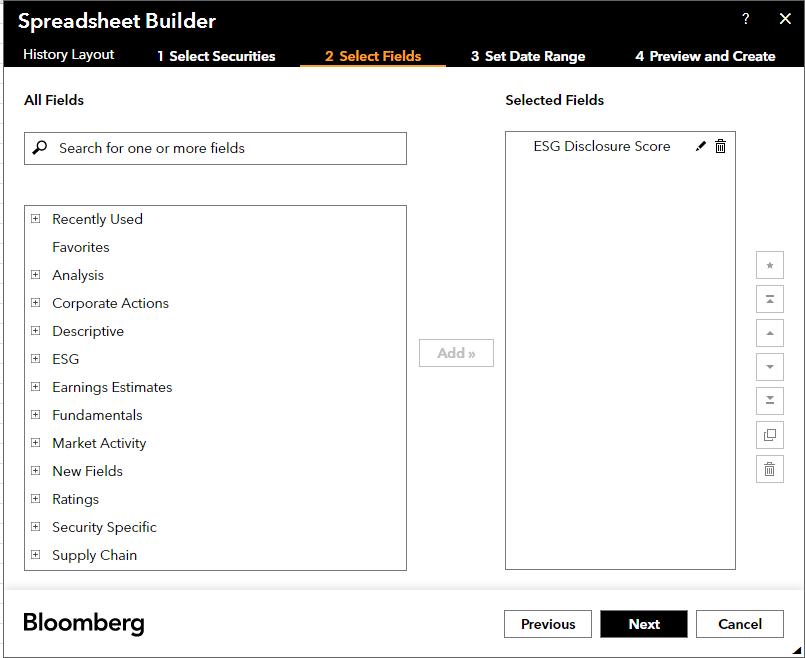
You can randomly pick one (or more) security. I would choose Apple (AAPL) here as an example. Then there appears a window where you can select fields you want.
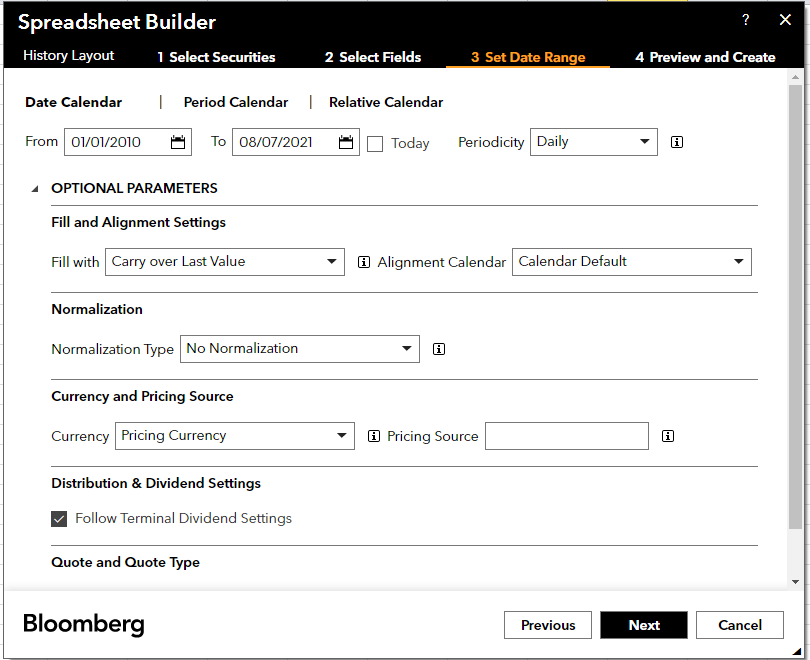
Then you can select the data range and periodicity. For variables like ESG Disclosure Score, we typically choose “Yearly”.
Finally, you will obtain the results. Click the cell exactly below Dates, you will get
- Function
bdh - Variable name
ESG_DISCLOSURE_SCORE - Equity Name
APPL US Equity - Start Date
1/01/2010 - End Date
8/07/2021 - Periodicity
Per=Y
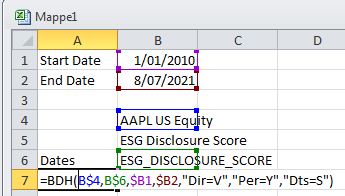
With the above information, you can construct the function you need for extracting data via API.
Code
Purely Extract Single Variable
In this case, you only need to
- Prepare a cusip list
cusiplist.xlsx - Customize the key parameters as you need
- Searching start date
date_from - Searching end date
date_until - Searching variable name
target
- Searching start date
import pandas as pd
from xbbg import blp
from tqdm import tqdmdf = pd.read_excel('cusiplist.xlsx')date_from = '20090101'
date_until = '20210630'
target = ['ESG_DISCLOSURE_SCORE']for cusip in tqdm(df_index['cusip']):df=blp.bdh(tickers=cusip,flds=target,start_date=date_from,end_date=date_until,\Per = 'Y')df.to_csv('ESG_Score_Single.csv', mode='a')
Extract Multiple Variables
As the institutional quota of request is monthly limited, it would be more efficient to request multiple variables together. In this case, you need to deal with a tricky situation. Suppose you request 7 variables for each firm, but some firm only has 4 variables valid while others have 5 variables valid. The distribution is random. API only returns the valid columns, which means the size of the returned dataframe and the order of the variable names could be random.
To deal with this situation, I write a function prepare() to pre-specify an order for all the requested variables to make sure the data returned for each variable should be written to the pre-specified column
-
For example, the data returned for
SOCIAL_SCOREis always written to the 3rd column while the data returned forENVIRON_DISCLOSURE_SCOREis always written to the 6th column -
If there is no data returned for a variable during one request, then write a blank stirng
""to the respect column
import pandas as pd
from xbbg import blp
from tqdm import tqdm
import csvdf = pd.read_excel('cusiplist.xlsx')date_from = '20090101'
date_until = '20210630'
target = ['ESG_DISCLOSURE_SCORE', 'SOCIAL_SCORE', 'ENVIRONMENTAL_SCORE',\'SOCIAL_DISCLOSURE_SCORE', 'ENVIRON_DISCLOSURE_SCORE', 'GOVNCE_DISCLOSURE_SCORE', 'ESG_RISK_SCR_MOMENTUM']def prepare(temp):cols = [i[1] for i in temp.columns]diff = set(target) - set(cols)diffindex = [target.index(i) for i in diff]leftindex = set(range(len(target))) - set(diffindex)dictt = list(zip(range(len(cols)), leftindex))return([cols, dictt])# Iterate each cusip in the cusip list
for i in tqdm(df.iterrows()):# Obtain cusipcusip = i[1][2]# Request data from Bloomberg APItemp = blp.bdh(tickers=cusip,flds=target, start_date=date_from,\end_date=date_until, Per = 'Y')[cols, dictt] = prepare(temp)with open('Esg_Score_Multiple','a') as f:# Open a csv file with mode 'a', which allows adding new rows# without covering existed rowsg = csv.writer(f)# Create a list with length equal to the number of requested # variables plus 3headline =['DATE']+target+['CUSIP', 'FIELDS']res = [""]*(len(target)+3)# Iterate each row of returned dataframefor row in temp.iterrows():for j,k in dictt:# Put date to the first cellres[0] = row[0]# Put variables returned by API following the# pre-specified orderres[k+1] = row[1][j]# Put the identifier of security into the listres[len(target)+1] = cusip# Put names of valid variables returned for the security# into the last cell of the list for cross-checkres[len(target)+2] = cols# Write the revised list to the opened csv fileg.writerow(res)
Sample Outcome
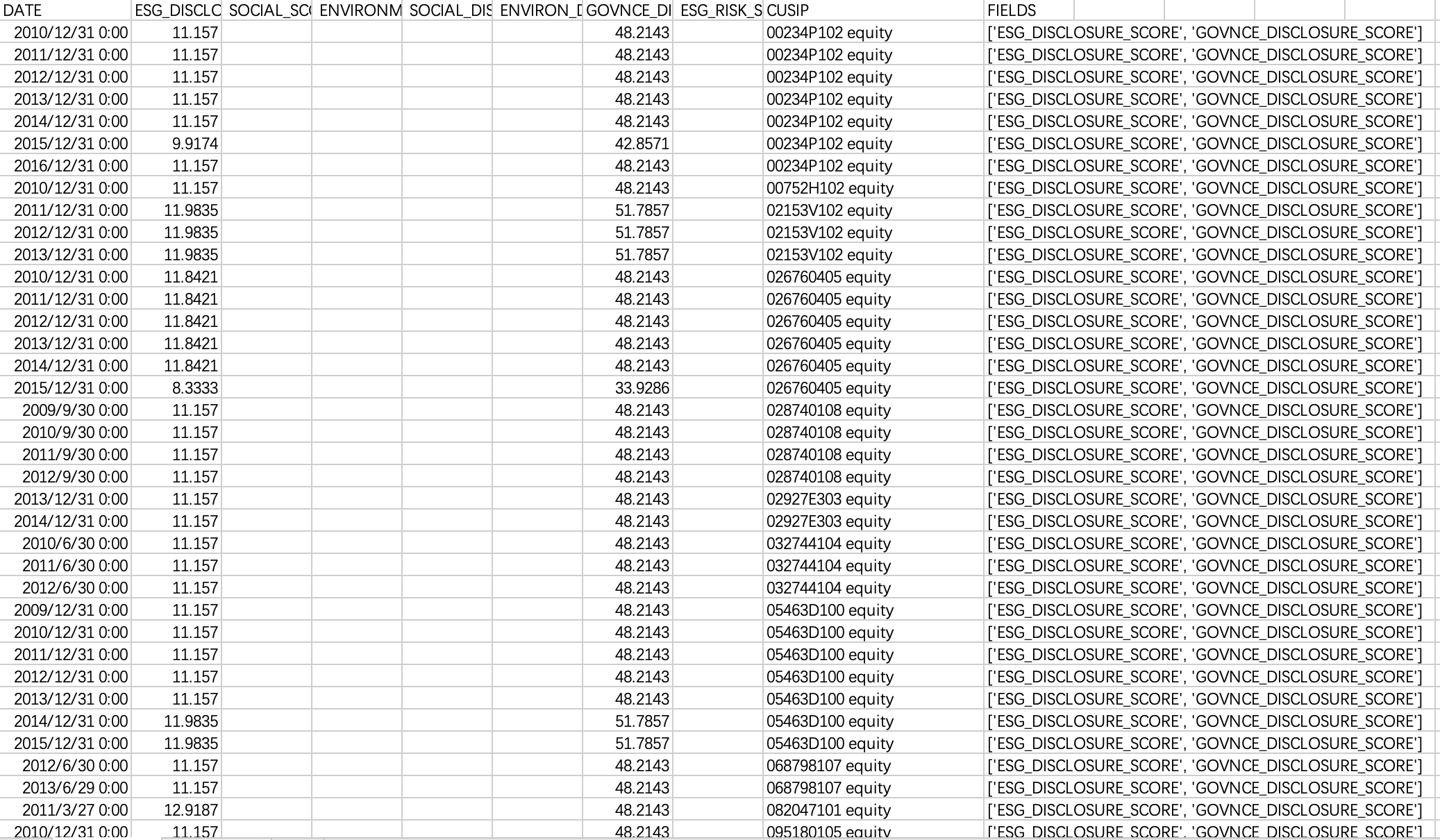
Main References
- https://github.com/alpha-xone/xbbg
- https://www.bloomberg.com/professional/support/api-library/
这篇关于Extract Mass Data Via Bloomberg API的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






