via专题

Flutter-Warning! This package referenced a Flutter repository via the .packages file that is no long
android studio中修改了diart sdk路径,需要执行以下步骤:
![[论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals](https://img-blog.csdn.net/20171124154517721?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
[论文笔记]Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Arbitrary-Oriented Scene Text Detection via Rotation Proposals 论文地址:https://arxiv.org/abs/1703.01086 github地址:https://github.com/mjq11302010044/RRPN 该论文是基于faster-rcnn框架,在场景文字识别领域的应用。 创新点:生成带文字

Openai api via azure error: NotFoundError: 404 Resource not found
题意:"OpenAI API通过Azure出错:NotFoundError: 404 找不到资源" 问题背景: thanks to the university account my team and I were able to get openai credits through microsoft azure. The problem is that now, trying to

One-Shot Visual Imitation Learning via Meta-Learning
发表时间:CoRL 2017 论文链接:https://readpaper.com/pdf-annotate/note?pdfId=4667206488817680385¬eId=2408726470680795136 作者单位:University of California, Berkeley Motivation:为了使机器人成为可以执行广泛工作的通才,它必须能够在复杂的非结构化

PCB设计中的via孔和pad孔
原文出自微信公众号【小小的电子之路】 在PCB设计过程中,经常会提到via孔和pad孔,下面就简单介绍一下二者的区别。 via称为过孔,主要起到电气连接的作用,用于网络在不同层的导线之间的连接。PCB设计中一般做盖油处理。 via孔 via孔有通孔(Plating Through Hole,PHT)、盲孔(Blind Via Hole,BVH)、埋孔(Buried Via Hol
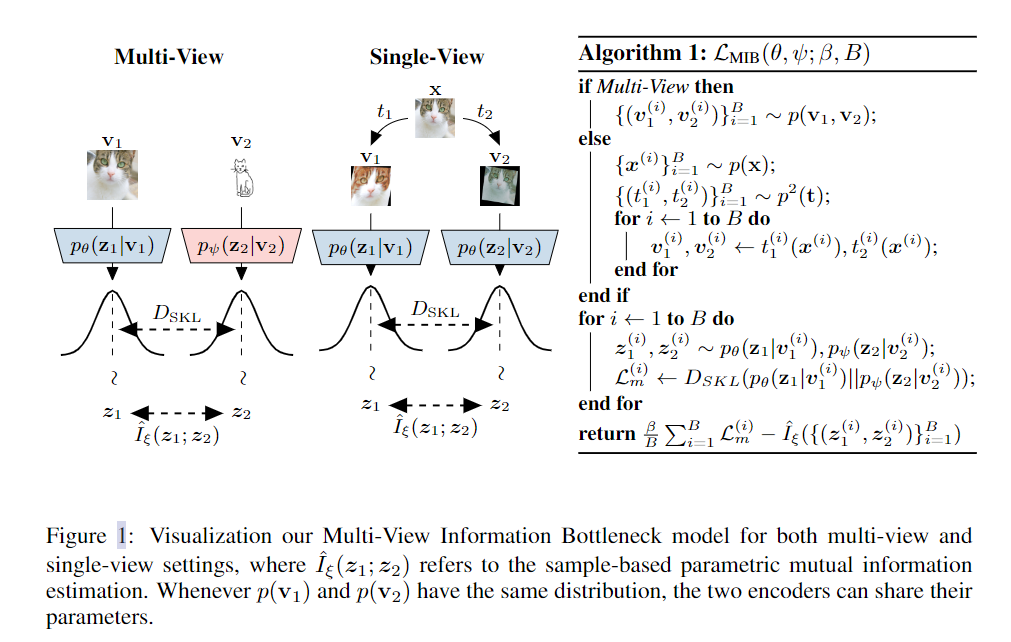
论文学习 Learning Robust Representations via Multi-View Information Bottleneck
Code available at https://github.com/mfederici/Multi-View-Information-Bottleneck 摘要:信息瓶颈原理为表示学习提供了一种信息论方法,通过训练编码器保留与预测标签相关的所有信息,同时最小化表示中其他多余信息的数量。然而,最初的公式需要标记数据来识别多余的信息。在这项工作中,我们将这种能力扩展到多视图无监督设置,其中提供
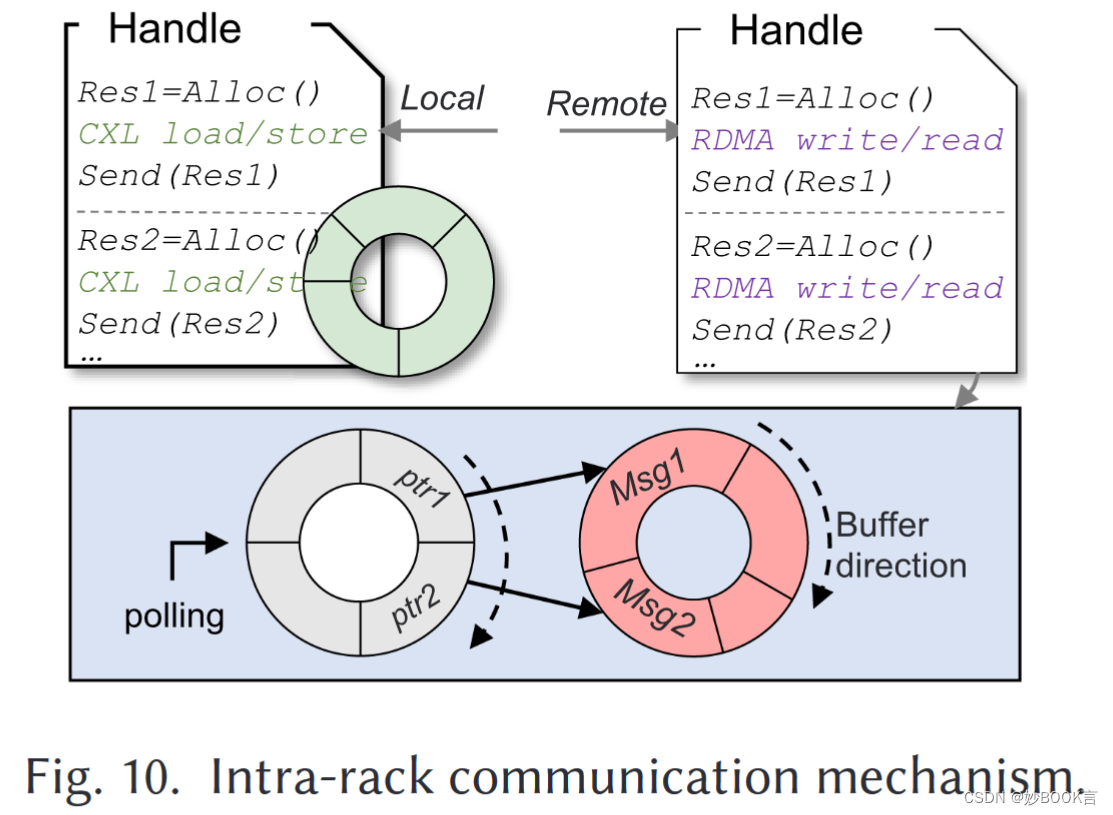
Rcmp: Reconstructing RDMA-Based Memory Disaggregation via CXL——论文阅读
TACO 2024 Paper CXL论文阅读笔记整理 背景 RDMA:RDMA是一系列协议,允许一台机器通过网络直接访问远程机器中的数据。RDMA协议通常固定在RDMA NIC(RNIC)上,具有高带宽(>10 GB/s)和微秒级延迟(~2μs),这些协议得到了InfiniBand、RoCE和OmniPath等公司的广泛支持[20, 47, 62]。RDMA基于两种类型的操作原语提供数据传输
论文阅读笔记——DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch
这篇文章,是2019年新的ICCV的papper,文章典型的使用了PatchMatch的思路,使得最后的速度快了很多。主要思路是:首先利用一种新颖的可微Patch Match算法来获得稀疏的cost volume。 然后,我们利用此表示来了解每个像素的修剪范围,自适应地修剪了每个区域的搜索空间。 最后,利用图像引导的优化模块来进一步提高性能。 由于所有组件都是可区分的,因此可以以端到端的方式训练整

论文阅读笔记:Towards Higher Ranks via Adversarial Weight Pruning
论文阅读笔记:Towards Higher Ranks via Adversarial Weight Pruning 1 背景2 创新点3 方法4 模块4.1 问题表述4.2 分析高稀疏度下的权重剪枝4.3 通过SVD进行低秩逼近4.4 保持秩的对抗优化4.5 渐进式剪枝框架 5 效果5.1 和SOTA方法对比5.2 消融实验5.3 开销分析 6 结论 论文:https://arx

《PixelLink: Detecting Scene Text via Instance Segmentation》论文阅读笔记
前言 这篇论文发表在AAAI2018上,作者给出了源码,个人认为是一篇比较work的论文。在之前DPR和SegLink两篇论文的阅读过程中,我就曾思考二者multi-task的必要性。特别是DPR的classification task,其实跟segment是几乎等价的。在复现过程中,回归任务远比分类(分割)任务难收敛。 可以认为,在自然场景下的文本检测任务中,DPR证明了anchor的非必要性

序列化推荐的图模型——Selecting Sequences of Items via Submodular Maximization(更新中)
本文介绍一种基于图模型的序列化推荐方法:OMEGA。文章来自AAAI-17,题目为《Selecting Sequences of Items via Submodular Maximization》,作者是来自苏黎世联邦理工学院的Sebastian Tschiatschek,Adish Singla 以及Andreas Krause。 背景 子集选择问题 首先,介绍一下子集选择问题,该问题的

Amortized bootstrapping via Automorphisms
参考文献: [MS18] Micciancio D, Sorrell J. Ring packing and amortized FHEW bootstrapping. ICALP 2018: 100:1-100:14.[GPV23] Guimarães A, Pereira H V L, Van Leeuwen B. Amortized bootstrapping revisited: Sim

风格迁移学习笔记(2):Universal Style Transfer via Feature Transforms
以下将分为3个部分介绍: 1.提出的background和sense2.proposal network pipeline3.results Background 先来review一下过去的架构. 1.传统的neural style存在两个巨大的弊端: 调参/耗时。即不仅需要我们对neural style的层级进行大量调参,而且整个迭代过程是对于z噪声进行迭代,非常耗时。
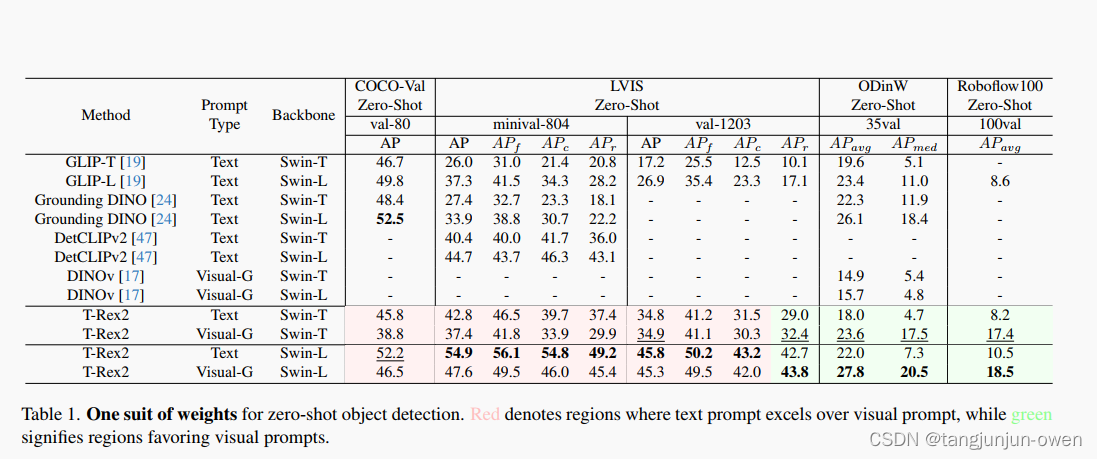
T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy论文解读
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、引言二、文献综述1. Text-prompted Object Detection2. Visual-prompted Object Detection3. Interactive Object Detection 三、模型方法1. Visual-Text Promptable Object Dete
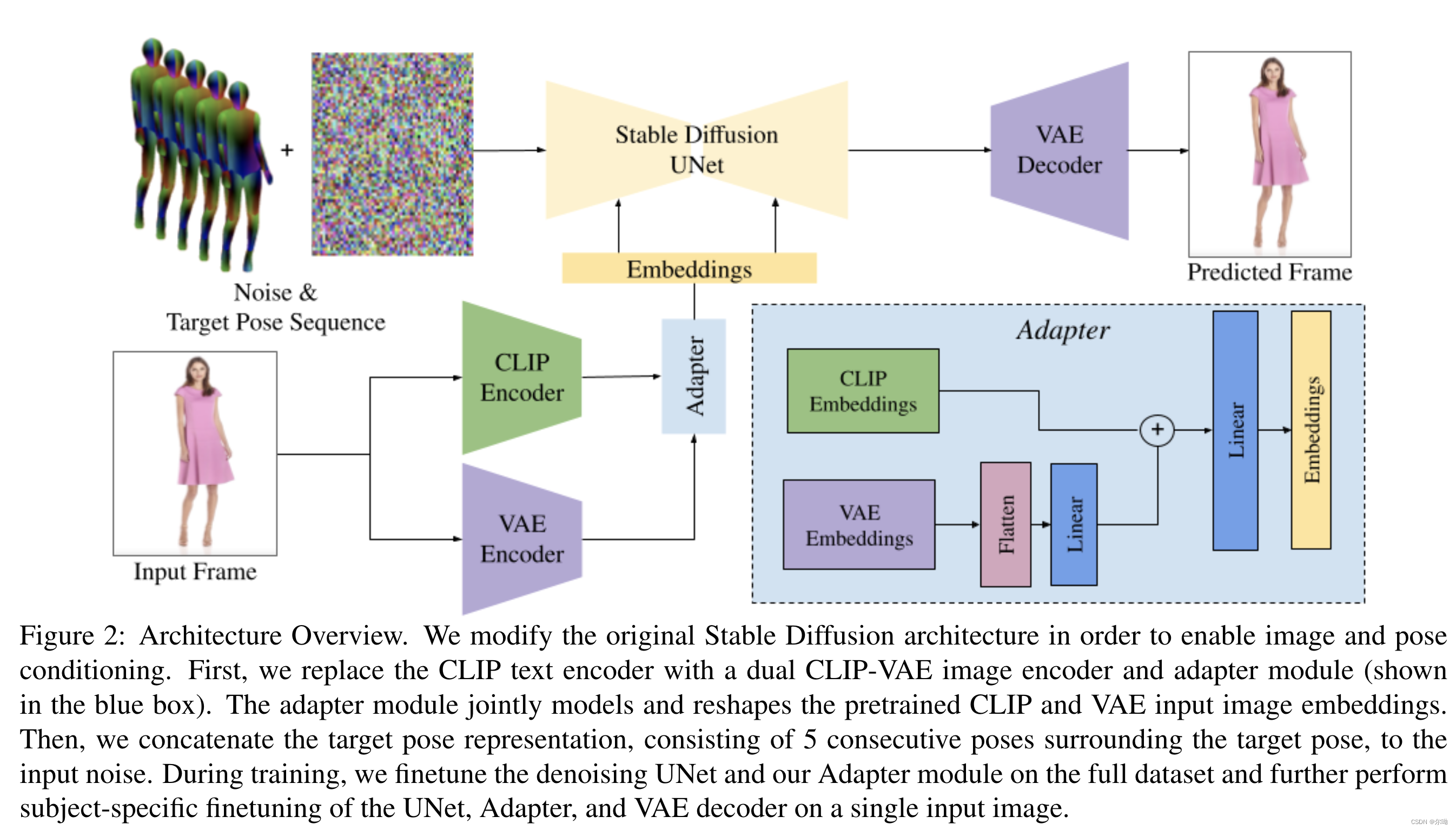
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
UW&UCB&Google&NVIDIA ICCV23https://github.com/johannakarras/DreamPose?tab=readme-ov-file 问题引入 输入参考图片 x 0 x_0 x0和pose序列 { p 1 , ⋯ , p N } \{p_1,\cdots,p_N\} {p1,⋯,pN},输出对应视频 { x 1 ′ , ⋯ , x N ′ }

论文《Face Alignment at 3000 FPS via Regressing Local Binary Features》笔记
论文:Face Alignment at 3000 FPS via Regressing Local Binary Features.pdf 实现:https://github.com/luoyetx/face-alignment-at-3000fps 摘要&介绍: 论文有两个新颖的点,一是采用局部二值特征,二是用局部性规则指导学习这些特征,最终的识别效果和实现速度俱佳。 论文首
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
本文的目的是输入一个image pair 然后得到他们的匹配 内存消耗大,推理时间长,对应关系局部性差。我们提出的修改可以减少10倍以上的内存占用和执行时间,并且效果相当。这是通过对包含试探性匹配的相关张量进行稀疏化,然后使用子流形稀疏卷积对其进行4D CNN后续处理来实现的。通过以更高的分辨率处理输入图像(这是可能的,因为减少了内存占用),以及通过一个新的两级对应重定位模块,定位精度显著
![[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection](https://img-blog.csdn.net/2018052520261694?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[深度学习论文笔记][AAAI 18]Accelerated Training for Massive Classification via Dynamic Class Selection
[AAAI 18] Accelerated Training for Massive Classification via Dynamic Class Selection Xingcheng Zhang, Lei Yang, Junjie Yan, Dahua Lin from CUHK & SenseTime paper link Motivation 这篇文章研究当分类器分类个数非常
步态识别论文(6)GaitDAN: Cross-view Gait Recognition via Adversarial Domain Adaptation
摘要: 视角变化导致步态外观存在显着差异。因此,识别跨视图场景中的步态是非常具有挑战性的。最近的方法要么在进行识别之前将步态从原始视图转换为目标视图,要么通过蛮力学习或解耦学习提取与相机视图无关的步态特征。然而,这些方法有许多约束,例如处理未知相机视图的难度。这项工作将视角变化问题视为域更改问题,并提出通过对抗性域适应来解决这个问题。这样,不同视角的步态信息被视为来自不同子域的数据。该方法侧重于

Shunted Self-Attention via Multi-Scale Token Aggregation
近期提出的ViT模型在各种计算机视觉任务上展现了令人鼓舞的结果,这要归功于能够通过自注意力对补丁或令牌的长期依赖性进行建模。然而这些方法通常指定每个令牌相似感受野。这种约束不可避免地限制了每个自注意力层在捕捉多尺度特征的能力。本文提出一种新的注意力,称为分流自注意力(Shunted Self-attention,SAA),允许ViT在每个注意力层的混合尺度上对注意力进行建模。SAA关键思想是将异构

【提示学习论文】PMF:Efficient Multimodal Fusion via Interactive Prompting论文原理
Efficient Multimodal Fusion via Interactive Prompting(CVPR2023) 基于交互式提示的高效多模态融合方法减少针对下游任务微调模型的计算成本提出模块化多模态融合架构,促进不同模态之间的相互交互将普通提示分为三种类型,仅在单模态transformer深层添加提示向量,显著减少训练内存的使用 1 Introduction 提示微调方法采用顺

DeepI2P: Image-to-Point Cloud Registration via Deep Classification
文章地址https://openaccess.thecvf.com/content/CVPR2021/papers/Li_DeepI2P_Image-to-Point_Cloud_Registration_via_Deep_Classification_CVPR_2021_paper.pdf 摘要: 本文提出了DeepI2P:一种新颖的方法,用于图像与点云之间的跨模态注册。给定一幅图像(
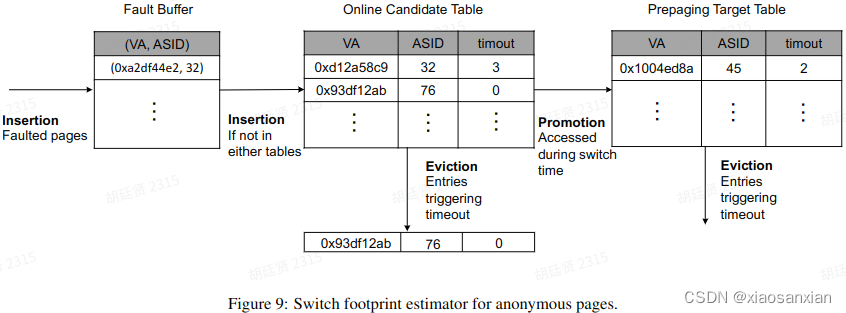
论文解读-ASAP: Fast Mobile Application Switch via Adaptive Prepaging
研究背景: 用户使用移动设备同时打开多个App,很容易造成移动设备的内存紧缺。现有解决方法一般采用杀死守护进程(lmkd)来释放内存或者基于压缩算法的in-memory swap(ZRAM)方式, 这些方法会面临用户切换回被杀死的进程过程效率低下问题,且严重影响用户体验。 其中Android操作系统的in-memory swap机制:其特点是需要压缩和解压缩匿名

【图像超分】论文精读:Single Image Super-Resolution via a Holistic Attention Network(HAN)
第一次来请先看这篇文章:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等) 文章目录 前言Abstract1. Introduction2 Related Work3 Holistic Attention Network (HAN) for SR3.1

BSP-Net: Generating Compact Meshes via Binary Space Partitioning精讲
在近日举行的 CVPR 2020 大会上,最佳论文、最佳学生论文等奖项悉数公布。加拿大西蒙弗雷泽大学陈之钦(Zhiqin Chen )等人的「BSP-Net」相关研究获得了最佳学生论文奖,他们的论文题目是《BSP-Net: Generating Compact Meshes via Binary Space Partitioning》。在最新一期的机器之心 CVPR 2020 线上论文分享中,西
【论文笔记】ResRep: Lossless CNN Pruning via Decoupling Remembering and Forgetting
Abstract 提出了ResRep,一种无损通道修剪的新方法,它通过减少卷积层的宽度(输出通道数)来缩小CNN的尺寸。 建议将CNN重新参数化为记忆部分和遗忘部分,前者学习保持性能,后者学习修剪。通过对前者使用常规 SGD 进行训练,对后者使用带有惩罚梯度的新颖更新规则进行训练,实现了结构化稀疏性,然后等效地将记忆和遗忘部分合并到层数更窄的原始架构中。 github仓库 1 Introdu