本文主要是介绍关于从USGS下载的Landsat数据进行植被的提取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、归一化植被指数(NDVI)
我下载的遥感数据有这些波段
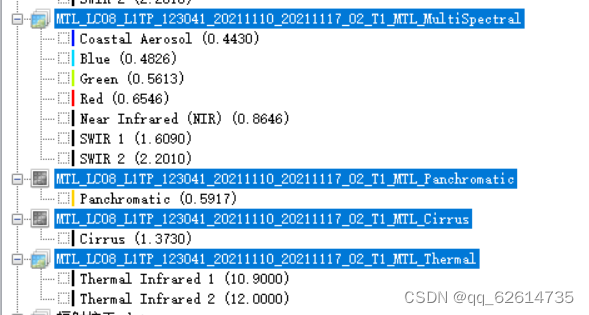
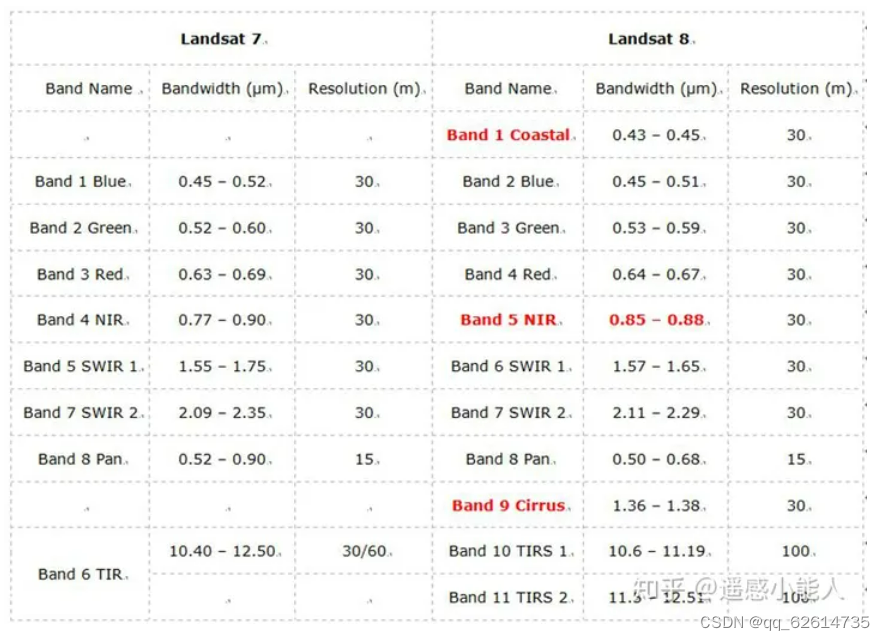
有水印的图片来自于https://zhuanlan.zhihu.com/p/133251982
算法如下:
1、如果你有遥感数据中的红光(Red)、近红外(NIR)和绿光(Green)波段,那么你可以使用标准的归一化植被指数(NDVI)计算公式来估算NDVI。NDVI是一种常用于植被监测的指数,其计算公式如下:
[NDVI = \frac{NIR - Red}{NIR + Red}]
\frac{NIR - Red}{NIR + Red} 表示将 NIR - Red 放在分子位置,NIR + Red 放在分母位置
其中,NIR代表近红外波段的辐射亮度值,而Red代表红光波段的辐射亮度值。计算得到的NDVI值将在范围[-1, 1]内,通常可用来表示地表的植被状况,数值越高表示植被越茂盛。
2、打开波段运算工具
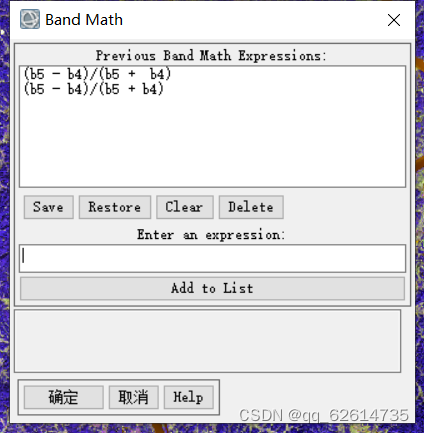
在其中输入(b5 - b4)/(b5 + b4),因为b5代表NIR,b4代表Red,对于输入公式加载会出现两个选项文件——加载,内存——展示。
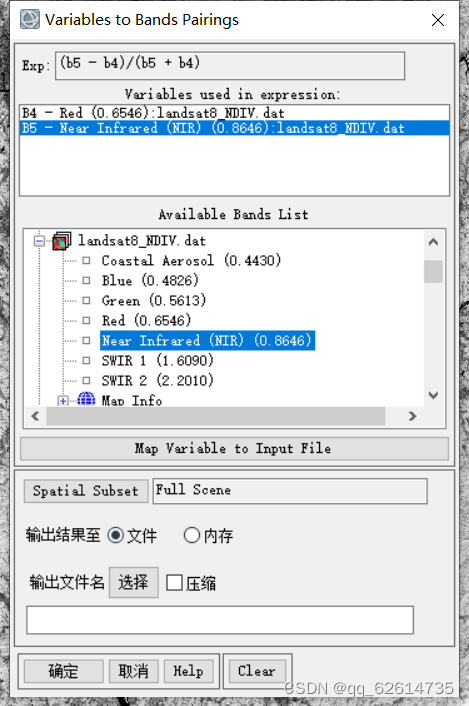
得到此图
3、波段统计
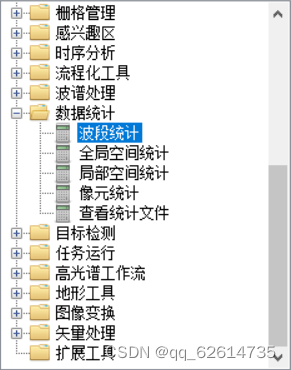
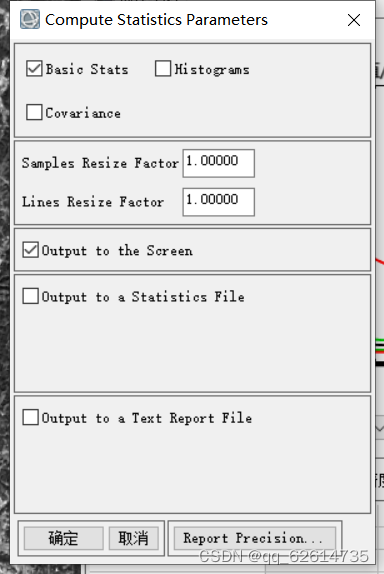
打开,选择landsat8_bandmath,打开得到一个界面,选择Histograms,点击确定即可。
得到: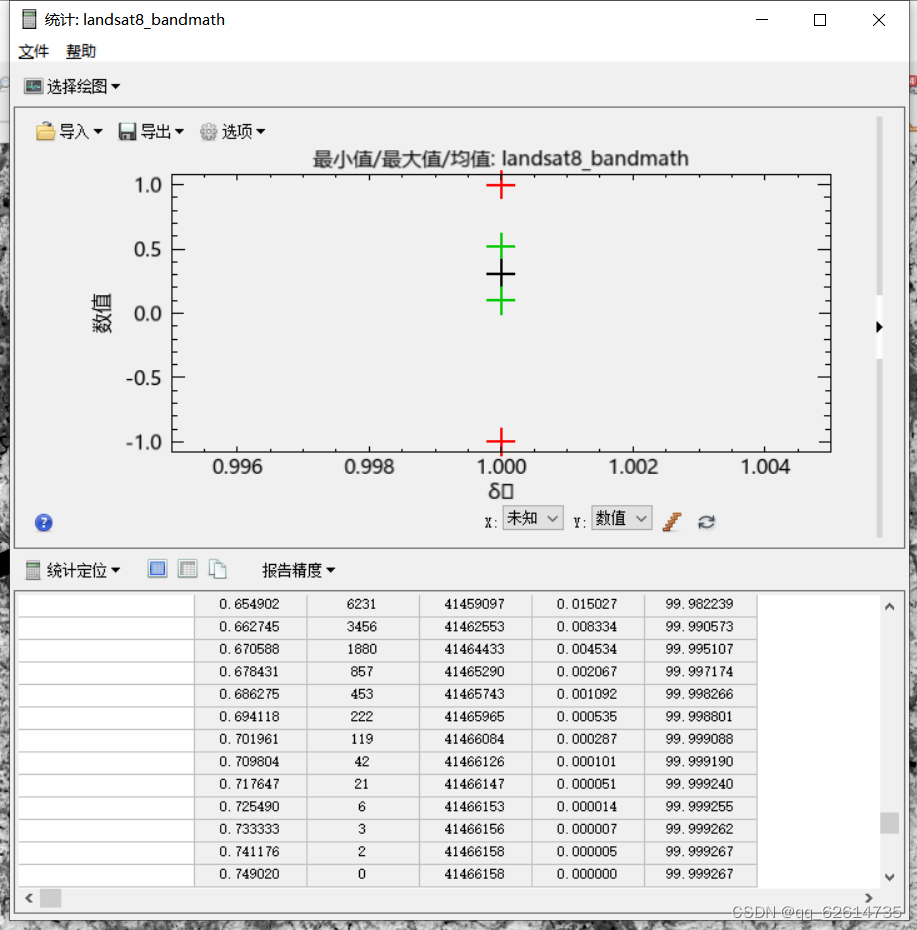
(植被在0.4-4之间,可以考虑去除小于-1,大于1的数据。)
在图像处理和分析中,选择百分位数(如2%、5%、95%、98%等)来提取归一化值或数据的一部分通常是为了去除图像中的极端值或异常值,并更好地捕捉数据的主要分布。这种做法通常用于统计学和数据处理中,有以下原因:
1. 去除异常值:极端值或异常值可能会干扰数据的分析和可视化。通过选择百分位数来截断数据,你可以将这些异常值排除在分析之外。
2.提高数据的动态范围:在某些情况下,图像或数据的动态范围可能很广,包含了大量的信息。选择较小的百分位数(如2%或5%)可以帮助突出数据的主要特征。
3.适应数据分布:不同类型的数据具有不同的分布特征,有些可能偏斜或包含长尾分布。通过选择适当的百分位数,你可以更好地适应数据的分布。
4.增强可视化效果:截断数据可以提高图像或图表的可视化效果,使数据更容易理解。
5.减小数据量:选择较小的百分位数可以减小数据量,这对于存储和传输大量数据时非常有用。
例如,选择2%和98%的百分位数来提取数据的一部分通常会剔除数据中的2%最小值和2%最大值,使得提取的数据包含了中间96%的值。这可以有效地去除异常值,并确保提取的数据在主要分布范围内。
在具体应用中,选择百分位数的值应根据数据的性质和分析任务来确定。
找到后记录数据
4、再继续波段计算(bandmath)
补充:这个我好像找到了地方,那个复杂的公式可能是因为把归一化的数据变成了一个波段了吧,后面有发现再来改改。
 http://t.csdnimg.cn/77zxk
http://t.csdnimg.cn/77zxk![]() http://t.csdnimg.cn/77zxk
http://t.csdnimg.cn/77zxk

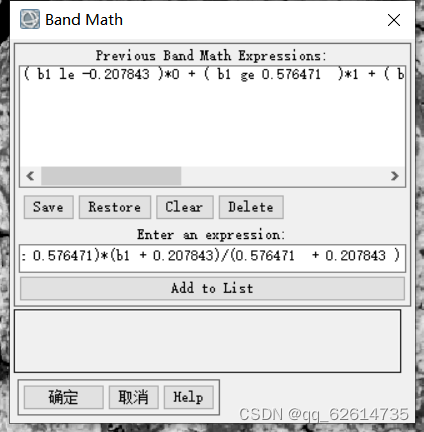
这一段我也不是很清楚,这个是作者的书写

最后b1波段是为计算的DNIV值。
5、导出转为tiff
另存为
最后,可以在arcgis中打开看看。整篇文章我借鉴了遥感数据处理的个人空间-遥感数据处理个人主页-哔哩哔哩视频
https://www.bilibili.com/video/BV16e4y1k7V9/?spm_id_from=333.880.my_history.page.click&vd_source=af5601c616cf7b00bb087ce5507a0fee
如果当中有错误,还请读者不吝赐教,其中的有些地方我后面弄懂了会重新加上去的,读者有改进的地方我也会加上去的。
二、归一化差异水体指数(MNDWI)
MNDWI=(band2-band3)/(band2+band3)=(GREEN-MIR)/(GREEN+MIR)
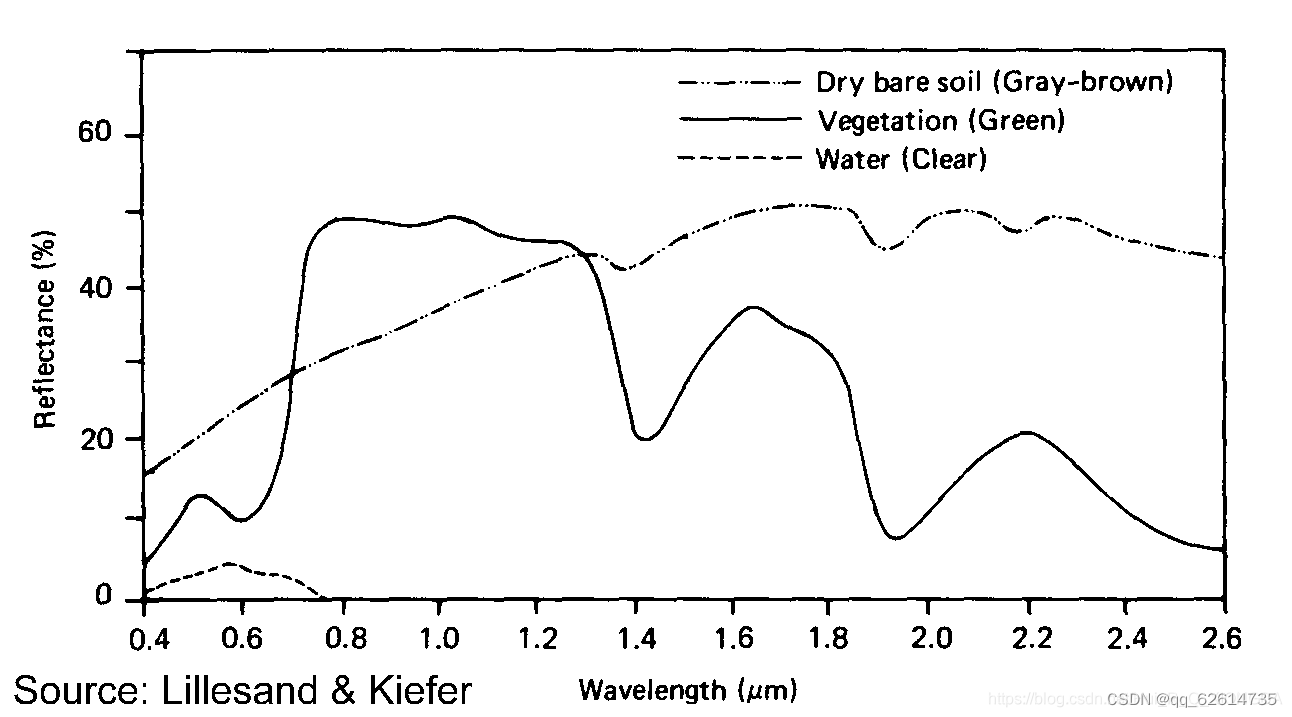
公式中: GREEN为绿光波段; NIR为近红外波段。NDWI主要利用了在近红外波段水体强吸收几乎没有反射而植被反射率很强的特点,通过抑制植被和突出水体用来提取影像中的水体信息,效果较好。但是由于NDWI只考虑了植被因素,忽略了建筑物和土壤这2个重要的地物,通过NDWI提取水体信息时由于绿光波段的反射率远远高于近红外波段,所以提取结果往往混淆有土壤和建筑物信息。用NDWI提取城市水体时会有较多建筑物阴影的水体,效果较差。
————————————————
原文链接:https://blog.csdn.net/qq_32306361/article/details/126247211
1、预处理
对于NDWI计算,预处理包括辐射校正和大气校正非常重要,以确保计算的准确性和可比性。这些步骤有助于消除大气和辐射影响,使NDWI能够更好地反映地表水体特征。
2、大气校正
辐射校正比较简单,主要是大气校正,以下是大气校正的做法:
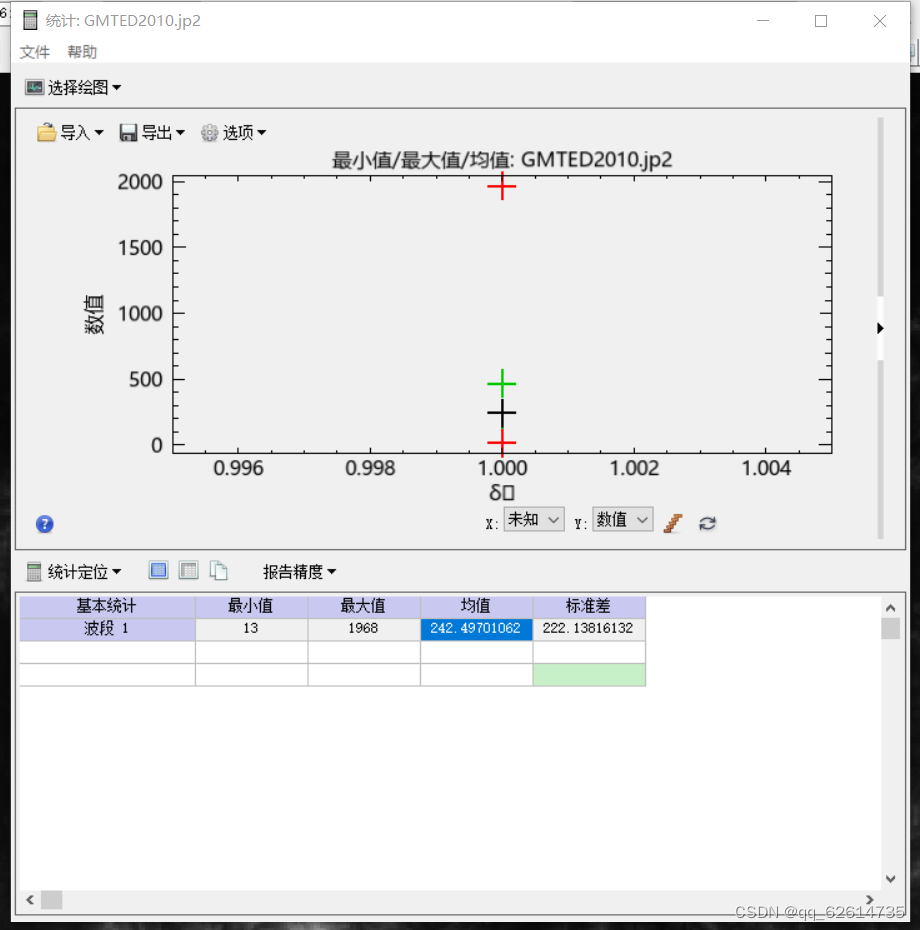
首先获取所在地区的高程值中的均值(为什么?)

在文件,打开世界数据里面最后一项高程中,点击就可以得到该遥感影像所匹配的高程,使用工具波段统计,得出如下结果,记住均值(米为单位)。
接下来进行大气校正(大气校正后的光谱曲线通常表现出地表上存在的不同要素或特征的反射率或反照率),选择FLAASH大气校正工具。

打开如下:
第一步,修改输入输出和存储路径,再修改遥感影像类型(下载时选择的遥感影像数据的卫星是哪种),然后修改高程值(km),最后查看时间和日期正不正确。
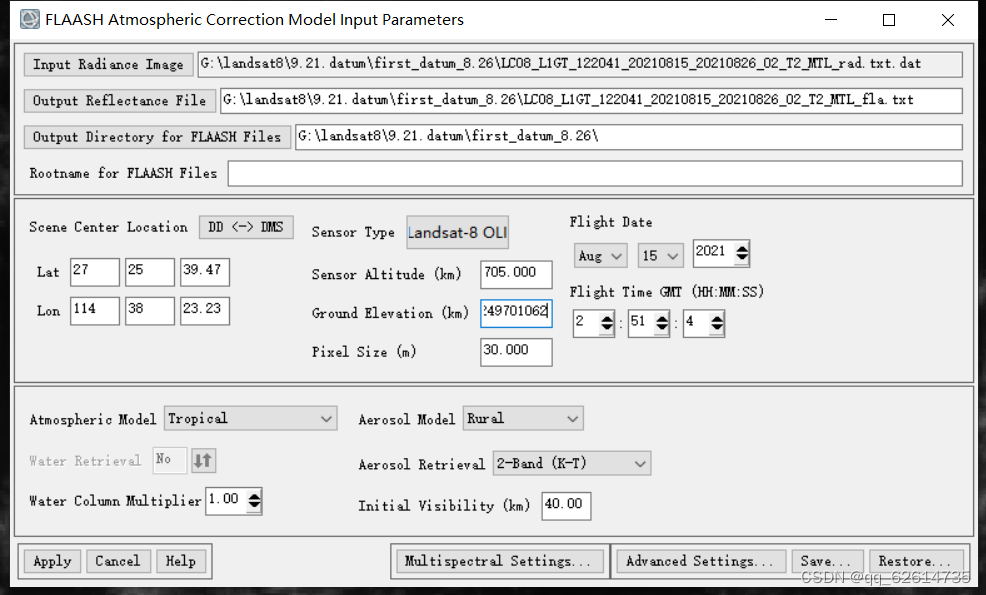
第二步,查询大气校正模型,找出经纬度和时间相匹配的模型。
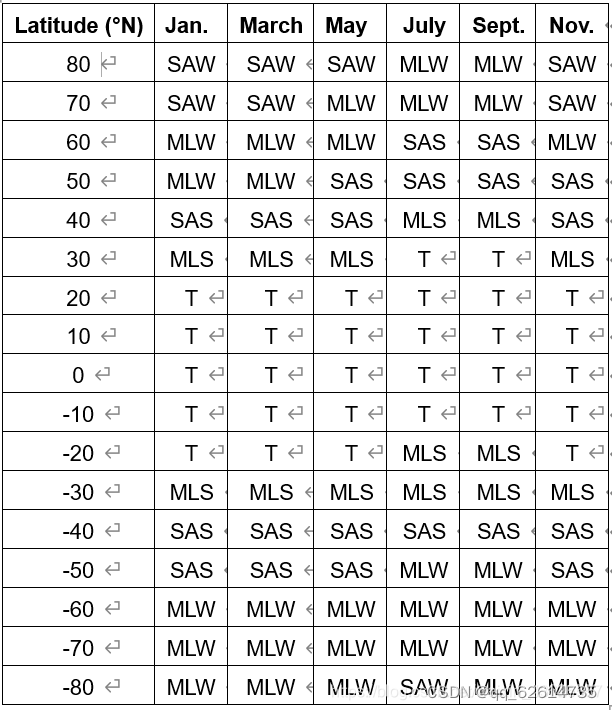
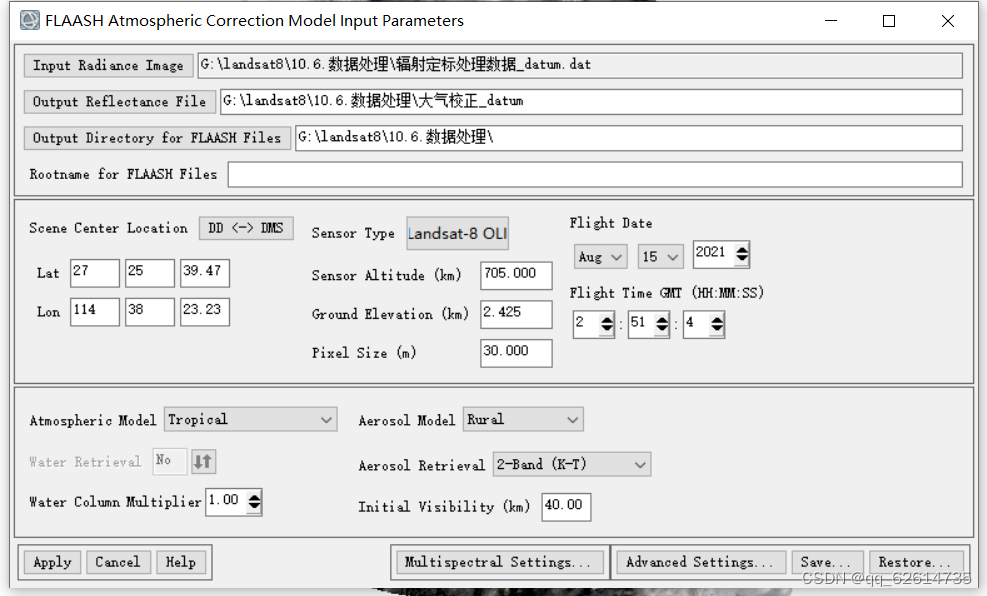
由于我这个影像不是整数的,因此我用经纬度和时间来套匹配的数据模型。

得到t模型,输入即可,至于Aerosol Model选择城郊还是其它地区都可以

第三步,选择Multispectral Settings,选择其中的Kaufman—Tanre Aerosol Retrieval【Kaufman-Tanre Aerosol Retrieval(KTAR)是一种气溶胶反演算法,用于估算大气中的气溶胶光学厚度(Aerosol Optical Depth,AOD)等气溶胶参数】,选择over_land Retrieval Standard (660:2100nm)。
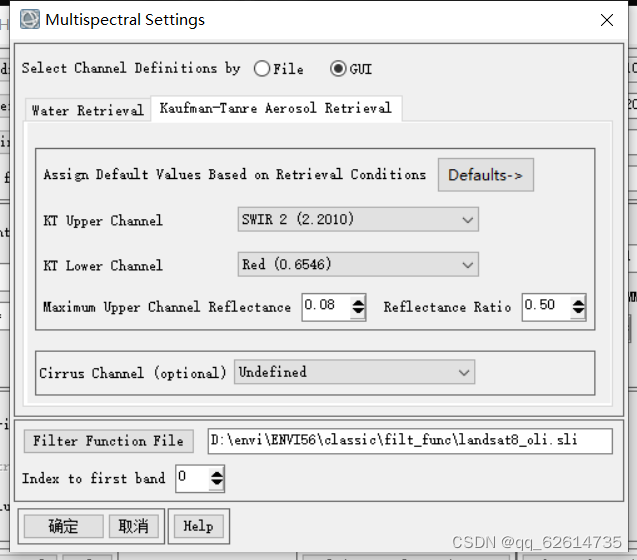
选择over_land Retrieval Standard (660:2100nm)的原因:
第四步,apply。
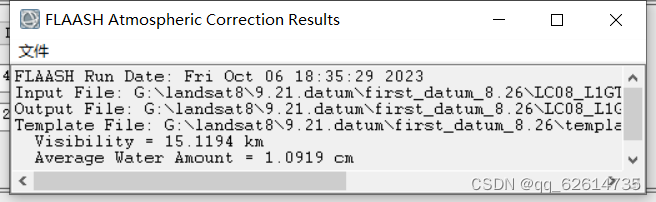
结果如下

最后,查看光谱曲线,先查看原始的数据
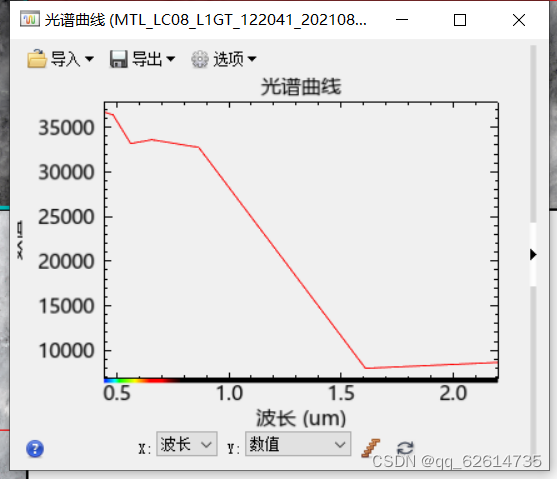
原始数据
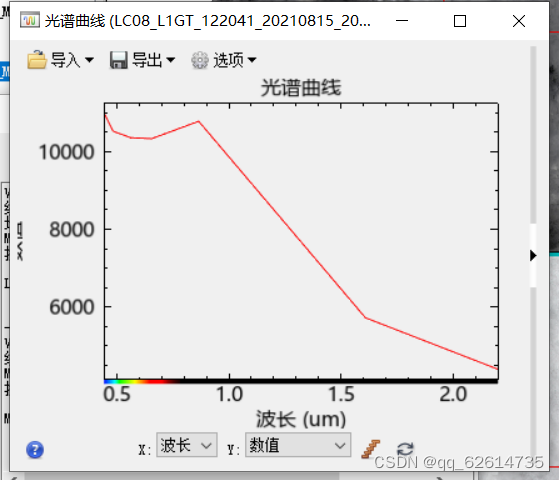
大气校正后的数据
比较数据正确与否

大气校正后的光谱曲线的特点包括:
1. 去除大气吸收和散射影响后,光谱曲线更为平滑,能够准确反映地物本身的光谱特征。
2. 光谱曲线的波峰和波谷位置和形态更加明显,有利于进行光谱分析和识别。
3. 在特定的光谱范围内,由于大气校正的不同,不同的光谱数据集可能存在一些差异。
4. 大气校正后的光谱曲线在不同地区、不同时间、不同季节和不同天气条件下的光谱响应有所不同。因此,在使用大气校正后的光谱数据时,应该根据自己研究的特定区域和时间段以及研究目的,对光谱曲线进行精细的分析和处理。

资料来源于:
【013 #ENVI-遥感影像预处理-辐射定标与大气校正(FLASSH大气模型)——以landsat8数据为例】 https://www.bilibili.com/video/BV1hf4y1K7su/?share_source=copy_web

http://t.csdnimg.cn/F4KgZ
3、数据误差处理
与上面的NDVI的数据处理一样,进行去除首尾的去除时,考虑到水体吸收的波段。
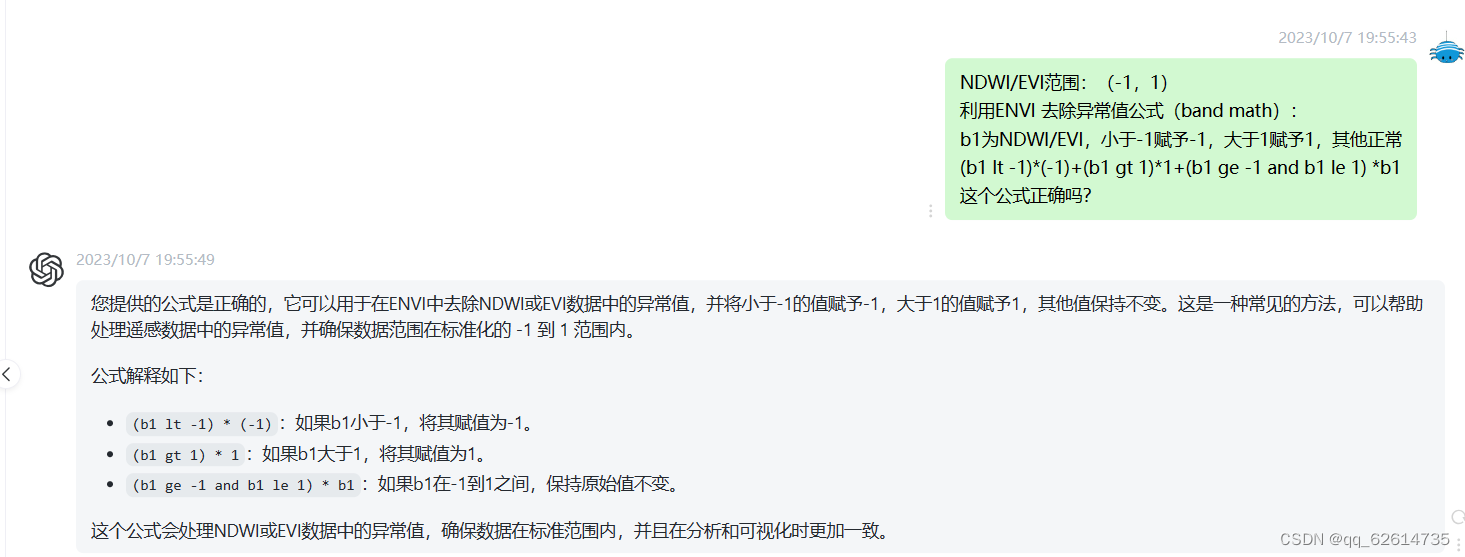
使用这个公式(上面那个公式也就是这个公式的解决方法)。
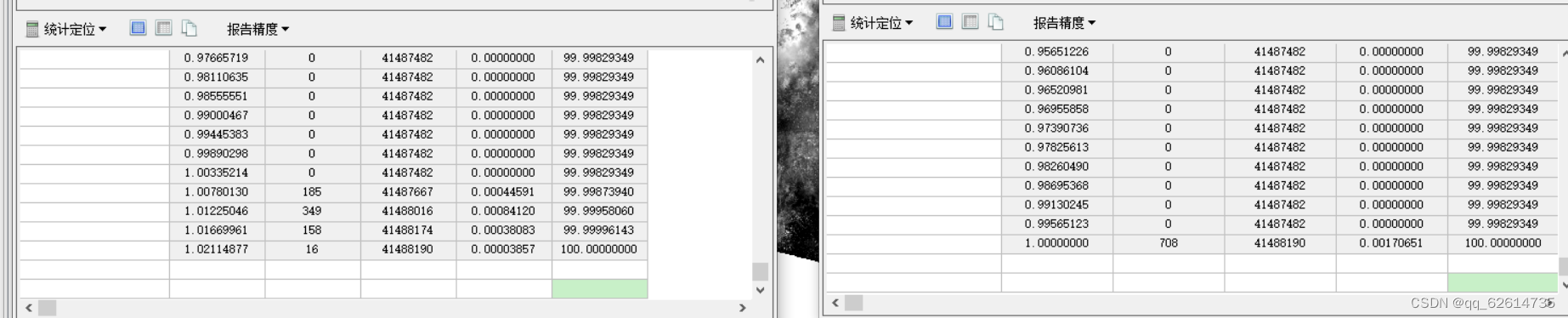
处理后的对比(左原,右改)
处理的数据观察是观察DN的数据,它是表示该像素在图像中的亮度或反射率。DN 值通常是整数,表示不同的亮度级别或强度水平,具体取决于传感器和图像的特性。在多光谱或高光谱遥感图像中,不同波段的 DN 值代表了不同波段下的反射或辐射强度。
另一种方法:
如果找不到对应的公式,可以考虑使用arcgis的栅格计算器来处理这个,使用con函数
con("数据名+条件",正确条件,"数据名")。

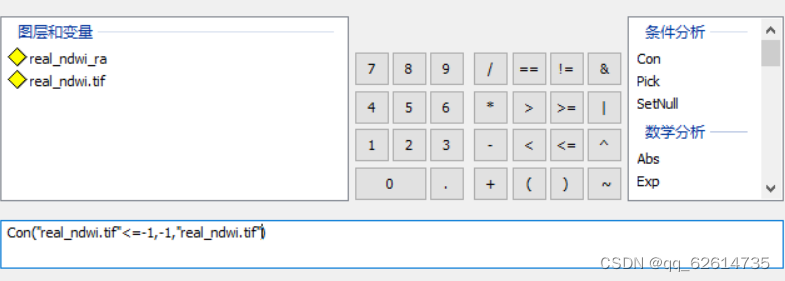
后面的数据对比有些问题,后面学到了再改改,这是一种方法。
这篇关于关于从USGS下载的Landsat数据进行植被的提取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




