本文主要是介绍《软件方法》强化自测题-分析(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DDD领域驱动设计批评-文集-点击查看>>
按照业务建模、需求、分析、设计工作流考查。
答案不直接给出,可访问每套题后面给出的自测链接或扫二维码自测,做到全对才能知道答案。
知识点见《软件方法》(http://www.umlchina.com/book/softmeth.html)
和“软件需求设计方法学全程实例剖析”幻灯片(http://www.umlchina.com/training/slide.html)
分析-强化自测题(2)
**1 [ 多选题 ]**关于分析模型,以下说法正确的有:
A) 分析模型中的概念要尽可能使用涉众最常用的词汇来命名
B) 分析模型不一定要用类图表达
C) 要更好应对变化,分析模型要反映核心域内涵
D) 判断分析模型好坏的最重要标准是能否反映源代码的精华
**2 [ 单选题 ]**在分析工作流中,如果给下面的空格中填上适当的文字,应该填什么?___________的类图
A) 状态
B) 系统
C) 用例
D) 对象
**3 [ 单选题 ]**如果状态图是对的,那么序列图上标号的地方有可能有错的是:
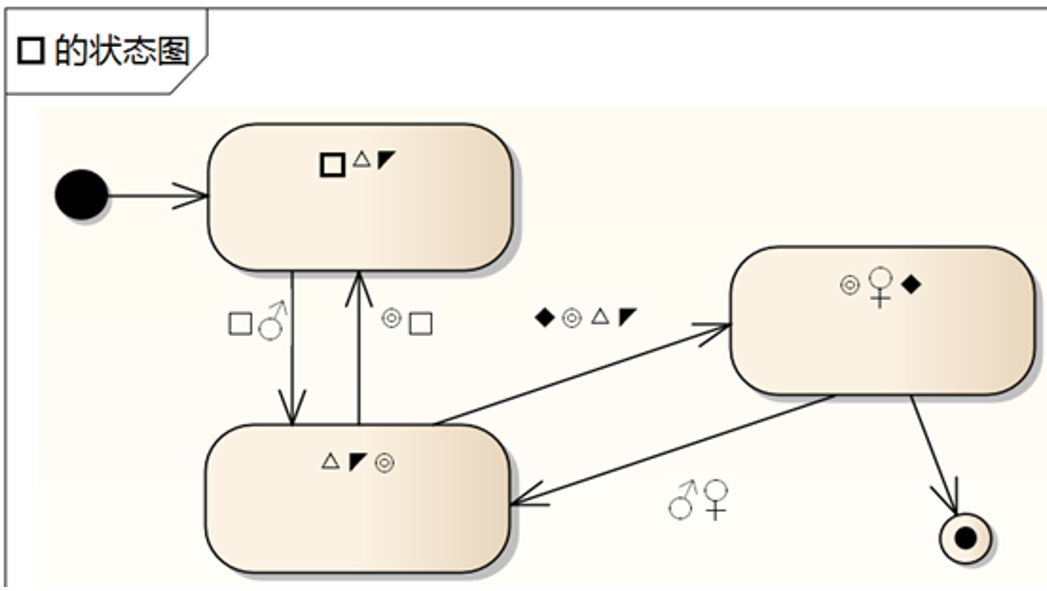
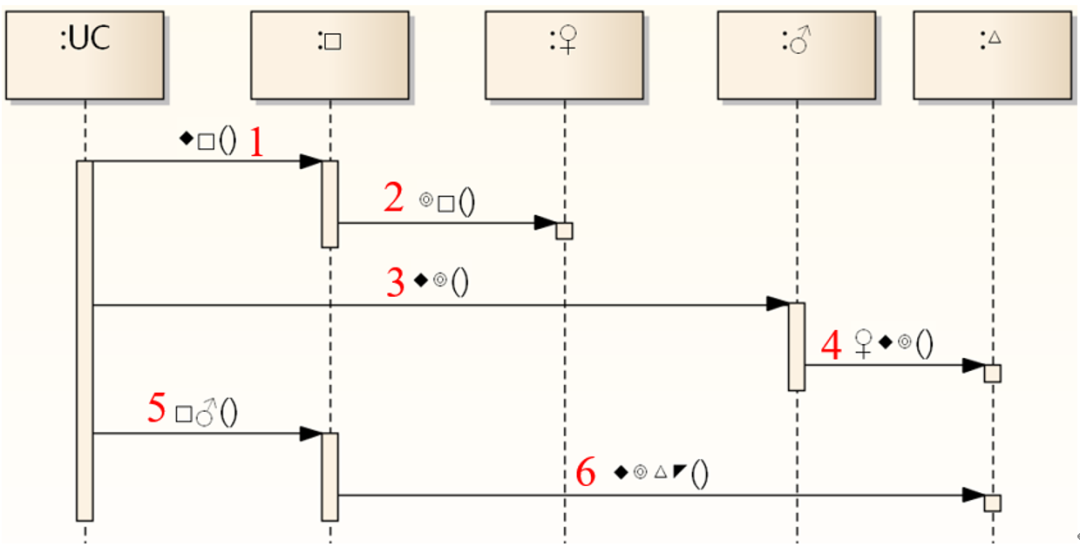
A) 1
B) 2
C) 3
D) 4
E) 5
F) 6
4 [ 单选题 ]“待发货”最合适作为以下哪个类的状态?
A) 购物流程
B) 购物系统
C) 订单
D) 订单管理功能
**5 [ 单选题 ]**以下说法中正确的是:
A) 分析工作流中,不同用例的分析序列图上的边界类不同。
B) UML模型是开发人员用来和涉众沟通的高效手段。
C) 类之间的关系有泛化、关联和依赖。
D) 不同工作流的模型代表源代码的不同视图,可以让开发人员从不同的视角观察源代码,这样就便于人脑把握源代码的复杂性。
**6 [ 单选题 ]**判断类之间关联的方向时,可以参考的原则是:
A) 状态不丰富的指向状态丰富的
B) 多重性为1的指向多重性为多的
C) 多重性为多的指向多重性为1的
D) 状态丰富的指向状态不丰富的
**7 [ 多选题 ]**以下概念经常有直接映射关系的有:
A) 业务序列图上的业务实体类型名称和系统用例图上的系统执行者名称
B) 业务序列图上的业务工人类型名称和系统用例图上的系统执行者名称
C) 分析序列图上的消息名称和分析类图上的属性名称
D) 分析序列图上的生命线名称的右侧和分析类图上的类名称
**8 [ 单选题 ]**长假,西湖断桥,男生李雷和女生韩梅梅相遇。正交谈甚欢间,突然下起了雨。雨越下越大,两人都淋湿了。李雷叫的滴滴到了,他邀请韩梅梅一起上车回如家换衣服休息,结果在如家两人(此处出题者删去三千六百一十八字)……

如果需要在软件系统中模拟李雷和韩梅梅的PaPa行为,把一些逻辑放在一个名为“PaPa”的操作中,把这个操作分给某一个类。那么以下说法正确的是:
A) 因为一般为男生主动,“PaPa”应为“男生”类的操作
B) 如果是封建社会(滴滴马车、如家客栈),“PaPa”放在“女生”类上意义更大
C) “PaPa”所封装的逻辑属于应用逻辑,应该放在控制类中更合适
D) 因为一般为女生被动,“PaPa”应为“女生”类的操作
**9 [ 单选题 ]**使用关系数据库来存储数据时,发现某个表的数据中,每一行都有某些列的值为空。从面向对象建模的角度看,这可能犯了什么错误?
A)忽略了泛化关系
B)把泛化当成关联
C)把关联当成泛化
D)把设计当成需求
**10 [ 单选题 ]**如图是某个图形界面的状态机,通过点击按钮控件A、B、C、D在不同状态间切换。按钮控件的IsEnabled属性值为True,按钮能够接收点击事件,IsEnabled属性值为Fase,按钮不能够接收点击事件。
请问,状态S4时,按钮控件A、B、C、D的IsEnabled属性值最有可能分别是?
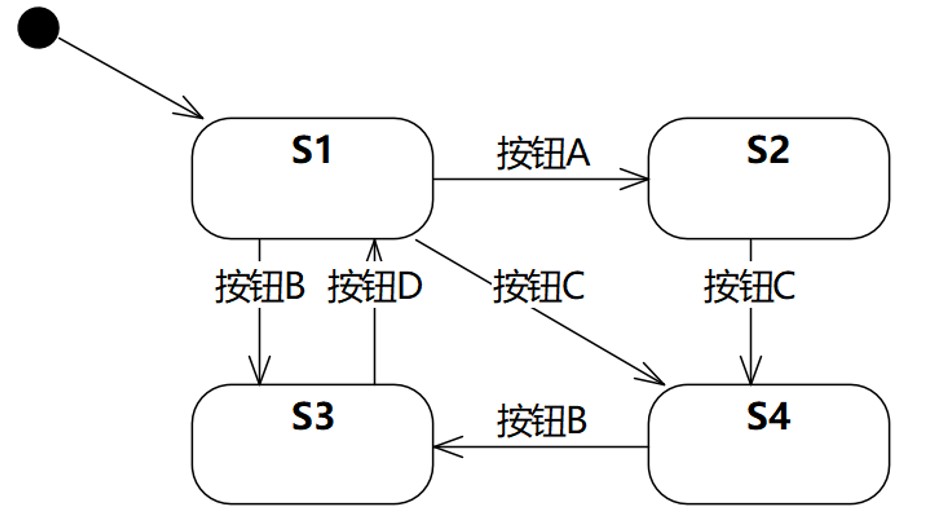
A)True、True、False、True
B)False、False、False、True
C)True、True、True、False
D)False、True、False、False
**11 [ 单选题 ]**以奇书《平安经》为素材画类图,以下最正确的是:


A)
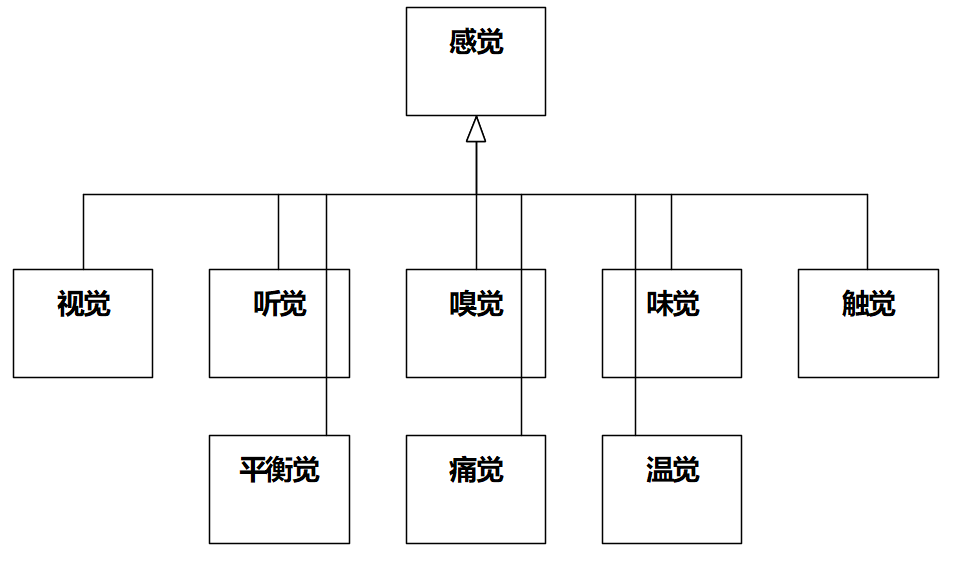
B)
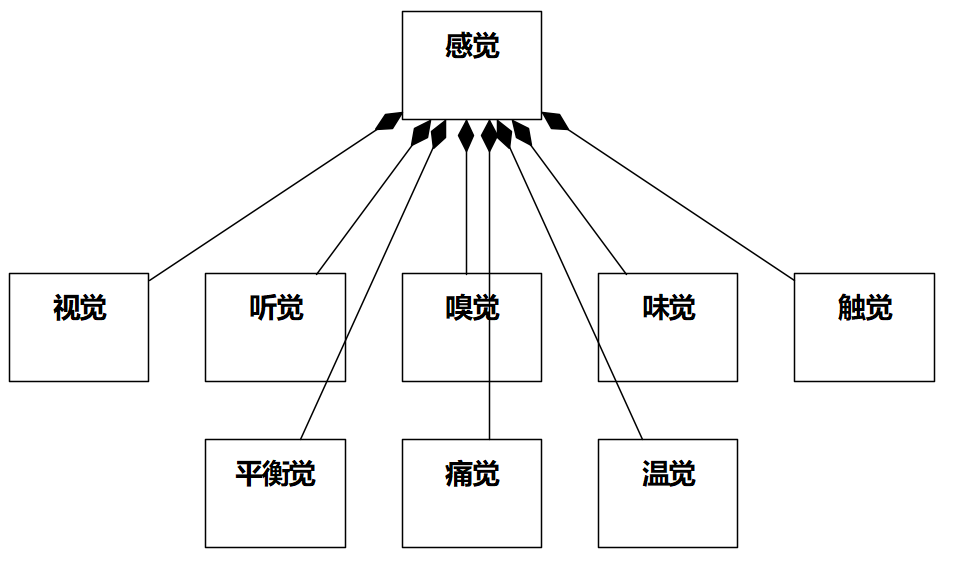
C)
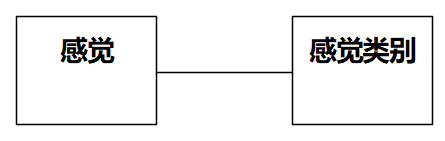
D)
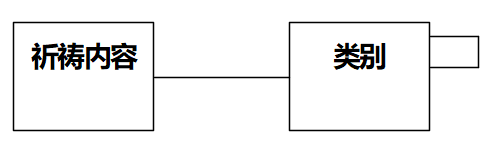
自测链接:https://www.101test.com/cand/index?paperId=MCST9Y
微信:umlchina2
这篇关于《软件方法》强化自测题-分析(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






