本文主要是介绍深度学习 肺结核_结核病的统计分析和数据探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习 肺结核
Data Analysis and data Visualization
数据分析和数据可视化
数据导论 (Introduction to Data)
The objective of this blog is to understand the global health epidemics and to analyse the factors related to Tuberculosis (TB). There are different data sets which provide country-wise information about estimates of incidence & mortality, outcomes, community engagement,laboratories, budgets etc. over a period of time. We thoroughly checked all the data sets and interpreted the relation among different variables.
该博客的目的是了解全球健康流行病并分析与结核病(TB)相关的因素。 有不同的数据集可提供有关一段时间内的发病率和死亡率,结果,社区参与,实验室,预算等的估计的国家信息。 我们彻底检查了所有数据集并解释了不同变量之间的关系。
After scrutinizing the data, we decided to focus on the estimates of HIV patients with TB and Total Estimates of TB. To initiate our analysis, we chose only one data set, i.e., TB_burden_countries_2020–02–29 data set. The data set contains estimation of incidences, incidences per 100k, mortality rate, case fatality ratio along with other useful parameters. It contains 4040 observation and 50 variables out of which 5 are ”character” variables and remaining are ”numeric”.
在仔细检查数据之后,我们决定重点关注HIV感染者的结核病估计数和TB总估计数。 为了开始分析,我们只选择了一个数据集,即TB_burden_countries_2020-02-29数据集。 数据集包含发病率,每10万的发病率,死亡率,病死率以及其他有用参数的估计。 它包含4040个观测值和50个变量,其中5个是“字符”变量,其余是“数字”变量。
Variables of Interest:
兴趣变量:
a) e_inc_100k — This variable shows the estimate incidence of TB per 100k population. It ranges from 0 to 1280 with a mean of 125.8.
a)e_inc_100k-此变量显示每10万人口中结核病的估计发病率。 取值范围是0到1280,平均值是125.8。
b) e_inc_tbhiv_100k — This variable shows the estimate incidence of TB who are HIV positive per 100k population. It ranges from 0 to 983 with a mean of 38.04.
b)e_inc_tbhiv_100k-此变量显示每10万人口中HIV阳性的结核病的估计发病率。 取值范围是0到983,平均值是38.04。
数据整理 (Data Wrangling)
Tidy — The data set looks tidy as each variable has a column and each observation on those variables has its own row.
整洁-数据集看起来整洁,因为每个变量都有一列,而这些变量的每个观察值都有自己的行。
Filter — We will select specific variables of interest by using dplyr.
过滤器-我们将使用dplyr选择感兴趣的特定变量。
Clean — Next step is to clean the data, which involves identifying the missing values and removing them if required.There are 613 missing values in the e_inc_tbhiv_100k” variable. Since there is no specific logic for imputation of the missing values, it is better to remove these observations.
清除-下一步是清除数据,这涉及识别丢失的值并根据需要删除它们。e_inc_tbhiv_100k”变量中有613个丢失值。 由于没有特定的逻辑来估算缺失值,因此最好删除这些观察值。
The region-wise boxplot shows the variation in the TB incidence per 100k among different regions-
区域箱形图显示了不同区域之间每100k TB发病率的变化-
The boxplot indicates that Africa (AFR) and South East Asia (SEA) have most number of TB incidence cases per 100k followed by Western Pacific Region (WPR). There are few data points which fall outside the upper bound of inter-quartile range (IQR). A value is suspected to be a potential outlier if it is less than (1.5)(IQR) below the first quartile or more than (1.5)(IQR) above the third quartile.On further investigation, it was observed that these values correspond to the countries with low population and high number of TB incidence per 100k so they can not be considered as outliers.
方框图表明,非洲(AFR)和东南亚(SEA)的结核病发病率每10万例中最多,其次是西太平洋地区(WPR)。 很少有数据点超出四分位间距(IQR)的上限。 如果该值小于第一个四分位数以下(1.5)(IQR)或大于第三个四分位数以上(1.5)(IQR),则可能是一个潜在异常值。在进一步研究中,我们发现这些值对应于每10万人口中结核病发病率低且人口众多的国家,因此不能将其视为异常值。
规划: (Planning:)
AFR, SEA and WPR regions encounter almost 80% of the all the TB incidence cases, so, further data analysis is done by focusing majorly on these three regions. Our hypotheses is — People who have HIV are at a higher risk of developing TB as compared with non HIV population.
AFR,SEA和WPR地区几乎遇到了所有结核病发病病例的80%,因此,通过主要关注这三个地区来进行进一步的数据分析。 我们的假设是:与非HIV人群相比,HIV人群患结核病的风险更高。
In this section, we will check for assumptions for normality and homoscedacity. The basic visual inspection of normality can be done by plotting histograms. Let us see the histograms for our variables-
在本节中,我们将检查正态性和同态性的假设。 正常的基本外观检查可以通过绘制直方图来完成。 让我们看看变量的直方图-
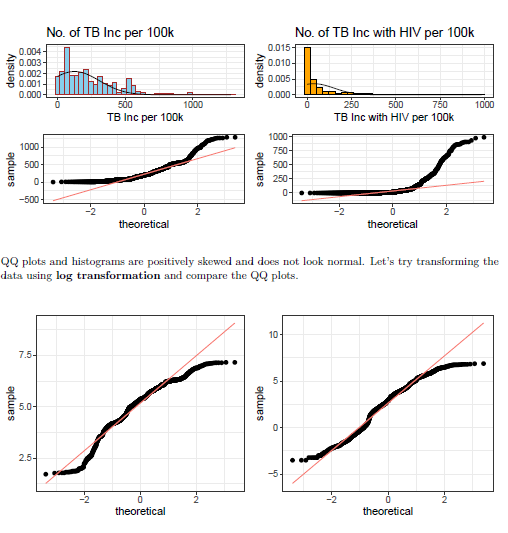
QQ plots and histograms are positively skewed and does not look normal. Let’s try transforming the data using log transformation and compare the QQ plots.
QQ图和直方图正偏,看起来不正常。 让我们尝试使用对数转换来转换数据并比较QQ图。

The plots look better after transformation but are still skewed.
变换后的图看起来更好,但仍然偏斜。
Another way is to do quantitative normality tests for skewness and kurtosis. We will perform these tests on the transformed data and interpret the results.
另一种方法是对偏度和峰度进行定量正态性检验。 我们将对转换后的数据执行这些测试并解释结果。

Because the absolute value of skew.2SE is greater than 1, we conclude that the skewness for both variables is different from 0. For Kurtosis, values are greater than 1, therefore we can say that kurtosis is different from 0. The results of skewness & kurtosis were quite high before data transformation.
因为skew.2SE的绝对值大于1,所以我们得出结论,两个变量的偏度都不同于0。对于峰度,值大于1,因此可以说峰度不同于0。偏度的结果数据转换之前,峰度和峰度很高。
To further test for normality, we use Shapiro-Wilk normality test and the test shows that the TB incidence per 100k is significantly non normal at 5% level of significance (p value < .05).
为了进一步检验正常性,我们使用Shapiro-Wilk正常性测试,该测试表明,每5%的TB发病率在5%的显着性水平上是显着非正常的(p值<.05)。
So we can conclude that the normality assumption does not hold true for both the variables based on visual as well as quantitative inspection. Next is the homoscedacity assumption which can be checked through levene test.
因此,我们可以得出结论,对于基于视觉和定量检查的变量,正态性假设均不成立。 接下来是均一性假设,可以通过乙炔测试进行检验。
Based on Levene Test, it is found that homogeneity of variance is significant at 5% level of significance (F=1.5886, p < 0.05), so we can thus infer that the assumption of homoscedasity is not met.
根据Levene检验,发现方差的同质性在5%的显着性水平上具有显着性(F = 1.5886,p <0.05),因此我们可以推断出不满足同质性的假设。
分析 (Analysis)
Now let’s look at the correlation between our variables of interest. We will do a quick visual check by using a scatter plot.
现在让我们看一下我们感兴趣的变量之间的相关性。 我们将使用散点图进行快速的视觉检查。
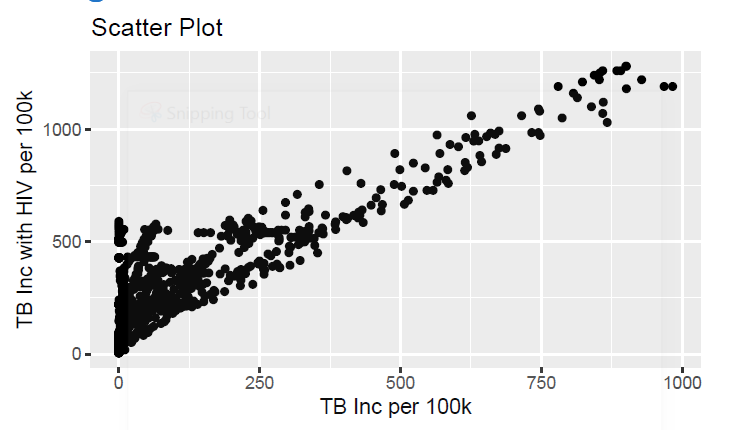
It looks like Total TB incidences might be positively correlated with TB incidences in people who have HIV. But correlation does not necessarily implies causation. We can test for correlation by using cor.test() and Pearson coefficient as we have interval data.
看起来总的结核病发病率可能与艾滋病毒感染者的结核病发病率呈正相关。 但是关联并不一定意味着因果关系。 我们可以使用cor.test()和Pearson系数来测试相关性,因为我们有间隔数据。
Total TB Incidences are significantly correlated with TB Incidences in people with HIV, r=0.84 (p < 0.001, 95% CI 0.827 to 0.858). A correlation of 0.84 represents a large effect explaining 71.11% of the variance.
艾滋病毒感染者的总结核病发病率与结核病发病率显着相关,r = 0.84(p <0.001,95%CI 0.827至0.858)。 0.84的相关性表示解释71.11%的方差的较大影响。
Let’s get more insights on TB incidence with respect to age and sex for the year 2018. After doing data wrangling, we see some interesting results.
让我们对2018年有关年龄和性别的结核病发病率有更多了解。经过数据整理之后,我们看到了一些有趣的结果。

From the boxplots of TB incidence rate, we observe that higher proportion of males is affected by TB as compared with females. If we look at 15 plus age group, males have 65% incidence rate whereas females are at about 35%.
从结核病发病率的箱线图中,我们观察到男性感染结核病的比例高于女性。 如果我们从15岁以上年龄段来看,男性的发病率为65%,而女性的发病率为35%左右。
If we observe the TB mortality rates of HIV and Non HIV population, there is significant difference between them. The percentage of people who had HIV before death is almost 2.5 times higher than the people who did not have HIV. The graph indicates that the mortality rates are declining over the last 18 years which may be a result of better healthcare and increased awareness about the disease but the difference in the HIV and Non HIV TB morality rates is more or less constant.
如果我们观察到艾滋病毒和非艾滋病毒人群的结核病死亡率,则两者之间存在显着差异。 死前感染艾滋病毒的人几乎是未感染艾滋病毒的人的2.5倍。 该图表明,在过去的18年中,死亡率下降了,这可能是由于更好的医疗保健和对疾病的认识提高所致,但是HIV和非HIV TB道德率的差异或多或少是恒定的。

One of the reasons for this gap could be the disproportionate budget allocation for TB HIV patients. For example,region got 4.5% of the total budget for TB HIV patients in 2018 and it had the highest proportion (37%) of TB HIV patients.
造成这一差距的原因之一可能是为结核病艾滋病毒患者分配的预算不相称。 例如,该地区在2018年占结核病艾滋病患者总预算的4.5%,占结核病艾滋病患者的比例最高(37%)。
结论 (Conclusion)
We got quite wonderful insights through our analysis which supports the hypothesis that people with HIV are at a higher risk of developing TB as compared with Non HIV population. Additionally, males have higher incidence of TB than females. Although the government is allocating resources to control this disease but still there are a few gaps in terms of financial allocation and health facilities which vary across countries. Moreover, the mortality rates have declined over the years which is a positive sign. There are other factors as well which directly or in-directly affect the incidence of TB but we can surely conclude that HIV is one of the important factors which causes TB.
通过我们的分析,我们获得了非常精彩的见解,支持了以下假设:与非HIV人群相比,HIV人群患结核病的风险更高。 此外,男性的结核病发病率高于女性。 尽管政府正在分配资源来控制这种疾病,但在财政分配和医疗设施方面仍然存在一些差距,具体情况因国家而异。 而且,这些年来死亡率下降了,这是一个积极的信号。 还有其他直接或间接影响结核病发病率的因素,但是我们可以肯定地得出结论,艾滋病毒是导致结核病的重要因素之一。
Data Source- WHO: TB dataset
数据来源- 世卫组织:结核病数据集
翻译自: https://medium.com/@waliapallav25/statistical-analysis-and-data-exploration-of-tuberculosis-7e293e32adb0
深度学习 肺结核
相关文章:
这篇关于深度学习 肺结核_结核病的统计分析和数据探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





