本文主要是介绍Mysql从简到杂,从删库到跑路!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
创建数据库、创建表、添加字段、复制表以及删库跑路
CREATE DATABASE test ;#创建一个数据库,名称为testDROP DATABASE IF EXISTS `test`; #如果存在就删除,没有的话执行下方的创建数据库
CREATE DATABASE test ;#创建一个数据库,名称为tesUSE test; #选择哪个数据库
DROP TABLE IF EXISTS `zbc`; #如果表存在,就删除,不存在直接执行下方sql
CREATE TABLE zbc( #创建表,表名称为zbc
id INT PRIMARY KEY AUTO_INCREMENT #id 列名,primary key 主键,auto_increment 自增1
)ENGINE=INNODB DEFAULT CHARSET=utf8 #复制表
CREATE TABLE cbc LIKE zbc;
INSERT INTO cbc SELECT * FROM zbc;
#基于zbc创建cbc表,
查询zbc表中所有信息插入到cbc表中#查看表结构
SHOW CREATE TABLE zbc \G
#注:如果使用第三方软件例如navicat执行此命令时会出现错误,因为第三方软件不能识别出\G
#ENGINE=INNODB 使用InnoDB引擎,InnoDB,是MySQL的数据库引擎之一,DEFAULT CHARSET=utf8 代表数据库默认编码为utf-8
2. 添加列
#添加phone列,类型是 nvarchar(50)
ALTER table zbc add phone nvarchar(30) #添加name列,类型是 nvarchar(50),default 代表着你这字段有默认值 值就是跟在后边的'1'
ALTER table zbc add name nvarchar(50) default '1' #表示插入在第一列
ALTER TABLE zbc ADD Uid INT FIRST;#表示添加在id字段的后边
ALTER TABLE zbc ADD idCard INT AFTER id;3. 修改列
#修改name列,default 默认值为100,设置之后每添加一条数据,该字段会默认添加100
ALTER TABLE zbc MODIFY name int NOT NULL DEFAULT 100;#修改表列名,将之前的 phone 改为了 idCard,类型为int
ALTER TABLE zbc CHANGE phone idCard int ; 4. 删除列
# 删除zbc表中的phone列
ALTER TABLE zbc DROP phone;5. 查询
就以上方这两个表为例子
单表查询
查询所有信息,*号代表里边的所有字段,但是正常开发时不建议使用!
SELECT * FROM `xbc`查询某一列的值
SELECT name FROM `xbc`查询id为3的那条
SELECT * FROM `xbc` where id=3查询id不等于3的数据
SELECT * FROM `xbc` where id!=3查询id是3或者4的信息
SELECT * FROM `xbc` where id=3 or id=4查询id小于三的信息
SELECT * FROM `xbc` where id<3 查询名字带有张的信息
SELECT * FROM `xbc` where name like '%张%'查询前边是10开头的phone
SELECT * FROM `xbc` where phone like '10%'查询以6结尾的信息
SELECT * FROM `xbc` where phone like '%6'查询name中张开头,后边只有一个字的数据,为了明确表达,我把张三改为了张三二
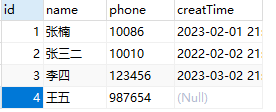
SELECT * FROM `xbc` where name like '张_'基于id排序查询,默认是升序,asc代表的就是升序,默认就是,所以asc写不写无所谓
SELECT * FROM `xbc` order by id asc基于id排序查询,降序
SELECT * FROM `xbc` order by id desc 查询最大的id
SELECT max(id) FROM `xbc` 查询最小id
SELECT min(id) FROM `xbc` 查询所有id的和
SELECT sum(id) FROM `xbc` 查询id的平均数
SELECT avg(id) FROM `xbc` 合并查询结果,需要保证字段数是一致的
select id,... from zbc
UNION #All all代表查询所有,不进行去重 distinct去重,默认自动去重了已经,如果不需要就加All
select id,... from xbc分组,基于name进行分组,查询name字段的条数
select name ,count(*) from zbc group by name 分组查询之后再添加with rollup 所有条数的和
select name ,count(*) from xbc group by name WITH ROLLUP 多表联查---内连接,基于关联条件查询两个表共有的字段
select * from 表名 a #as 起别名,as可以省略,所以这个表名的别名为 a
inner join zbc b on a.id=b.id #inner可以省略多表联查---左连接,以左表为主,也就是zbc为主,xbc为辅,zbc里边的数据会全部展示,如果xbc的数据小于zbc,那么xbc的数据以null补齐
select * from zbc a
left join xbc b on a.id=b.id多表联查---右连接,以右表为主,也就是xbc为主,zbc为辅,xbc里边的数据会全部展示,如果zbc的数据小于xbc,那么zbc的数据以null补齐
select * from zbc a
right join xbc b on a.id=b.id对于字段中出现null值的处理,查询zbc表中Uid字段不是null的信息
select * from zbc where Uid is not null对于字段中出现null值的处理,查询zbc表中Uid字段是null的信息
select * from zbc where Uid is null如果Uid的值是null,那么就给他赋值为0
select ifnull(Uid,0) from zbc 查询---利用正则表达式
#表示查询phone字段最后一位是4的信息
SELECT phone FROM xbc WHERE phone REGEXP '4$';
#表示查询phone字段以10开头的信息
SELECT phone FROM xbc WHERE phone REGEXP '^10';
#表示查询phone字段中带有9的信息
SELECT phone FROM xbc WHERE phone REGEXP '9';
#表示查询phone字段中以9开头并且以4结尾的数据
SELECT phone FROM xbc WHERE phone REGEXP '^[9]|4$';具体表达式参考正则表达式的
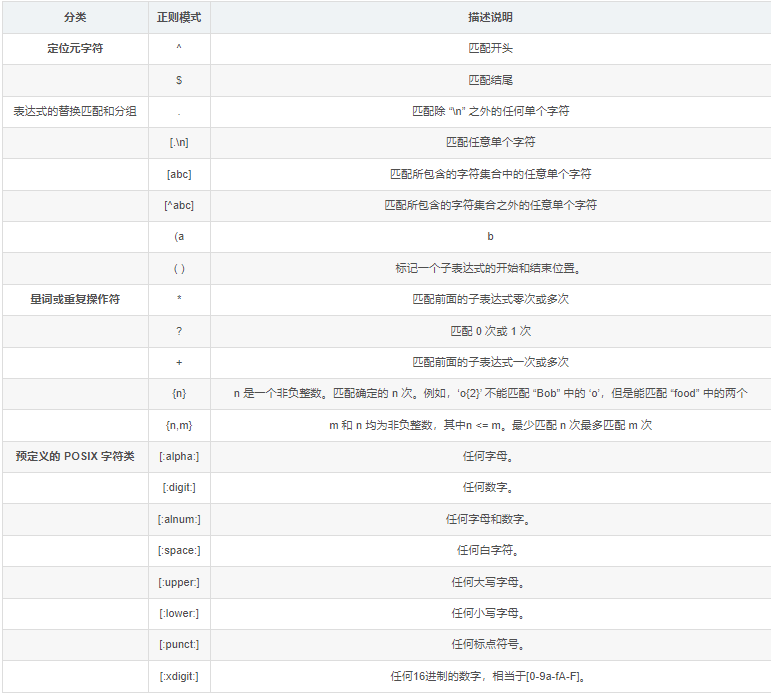
正则表达式的替换
#正则的替换,将zbc表中name字段包含2的内容将2替换成5,条件是2开头的
UPDATE zbc set name = REGEXP_REPLACE(name, '2', '5') WHERE name REGEXP '^2';
#简化之后
UPDATE zbc set name = REGEXP_REPLACE(name, '^2', '5') 查询MYSQL的元数据
SELECT VERSION( ) #当前mysql的版本信息
SELECT DATABASE( ) #当前数据库的名称,如果没有选择就是空
SELECT USER( ) #当前操作的用户名
SHOW STATUS #当前MYSQL的状态
SHOW VARIABLES #服务器配置变量mysql去重
#查询条数 #插叙所有条数,
select count(*) as cc ,id,name,phone from zks
group by id,name,phone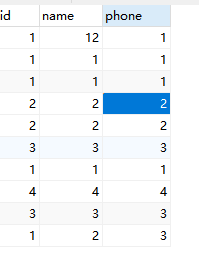
#结果
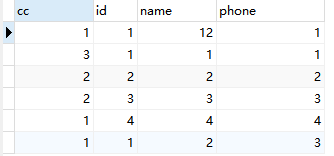
#字面意思就是
id是1,name是1,phone是1的一共有三条,
id是1,name是12,phone是1的有1条,也就是cc代表的条数,id、name、phone代表的各自的字段信息,如果cc>1那么就代表这个表里的信息对应的id,name,phone对应的值有重复的
#加上having
select count(*) as cc ,id,name,phone from zks
group by id,name,phone
having cc>1 
如果加上having就代表只要id是1的,就总结到一起,也就是id是1并且name、phone相同的数据的条数并且>1,因为id是1但是name、phone不是1,所以不存在此条件中!
mysql函数---字符串
#CHAR_LENGTH() 返回name字段的长度,与CHARACTER_LENGTH( ) 作用一致
SELECT id,CHAR_LENGTH(name) AS length from test;#CONCAT() 将所查询的id、name、phone拼接起来并返回
SELECT id,CONCAT(id,' ',name,' ',phone) AS name from test; # CONCAT_WS() #类似CONCAT(),第一个定义的"-"会在后边拼接的位置自动加上:id-name-phone
SELECT CONCAT_WS("-", id,name,phone)AS cc from test;# FIELD() #结合order by 进行使用,自带group by ,如果不添加desc就是默认的升序显示顺序:
1 2 3 132 5 89,如果加上desc 89 5 132 1 2 3 顺序显示
select * from zka order by field(name,'132','5','89') desc ;也可以简单的使用直接查位置,例如官方例子:
SELECT FIELD("c", "a", "b", "c", "d", "e");# FIND_IN_SET ( s1,s2) #查询s2中包含s1信息的字段
SELECT * FROM zka WHERE FIND_IN_SET ( id ,'8,12,1,2,3,4,5,6,7');未完待续...
这篇关于Mysql从简到杂,从删库到跑路!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






