本文主要是介绍【机器学习】使用scikitLearn对数据进行聚类:高斯聚类GaussianMixture,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
无监督学习:
【机器学习】使用scikitLearn对数据进行聚类:Kmeans聚类算法及聚类效果评估
【机器学习】使用scikitLearn对数据进行聚类:Kmeans聚类算法的应用及密度聚类DBSCAN
【机器学习】使用scikitLearn对数据进行聚类:7种异常和新颖性检测方式
高斯混合模型,是一种生成模型,不但可以进行聚类,因为掌握了每一类的概率模型,还可以进行每一类新实例的生成。、
生成过程为:
假定生成m个实例,共有k个高斯分布可供选择;生成每个实例时,根据一组权重参数,先选取该实例所属集群的标签,根据标签从k个高斯分布中选取该集群对应的分布,然后再利用高斯分布采样出该实例,就完成了一个新实例点的生成。
from sklearn.mixture import GaussianMixture
#高斯聚3类
gm = GaussianMixture(n_components=3, n_init=10, random_state=42)
gm.fit(X)
模型训练结束后,可以进行如下操作:
#判断新数据点的类别
gm.predict(X)
#进行软聚类,输出新数据点属于每一类的概率
gm.predict_proba(X)
#生成6个新数据点
X_new, y_new = gm.sample(6)
其高斯分布参数采用期望最大化模型进行求解,同kmeans算法的求解较为类似,也使用n_init=10多次求解取最优值。
同时,在给定的任意坐标点处,可以输出不同集群实例分布的密度分数,密度分数越高,实例分布越密:
densities = gm.score_samples(X)
下面根据百分位数,进行密度筛选(密度选择的结果可以做异常检测):
比如筛选出分布较稀疏的前10%的密度点,假定异常率是10%:
#查看个样本所在点的密度
densities = gm.score_samples(X)
#取后10%的密度阈值(取密度最稀疏的10%的分界密度)
density_threshold = np.percentile(densities, 10)
#比该密度值还小的点是异常点,这里使用同形bool做的mask进行索引,
#找出这些最稀疏的点:
anomalies = X[densities < density_threshold]
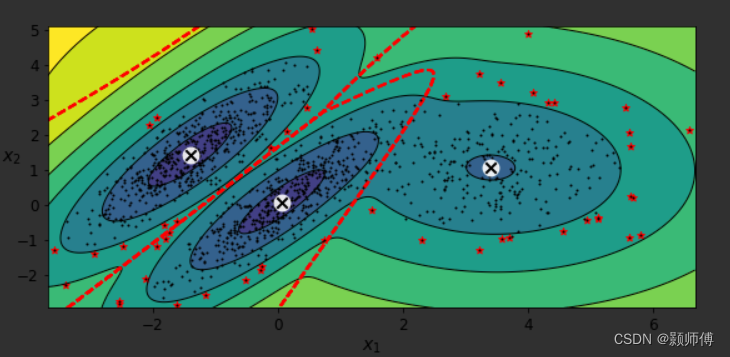
标红的点被认为异常的,其常用于数据清洗工作。
限制算法的自由度,加速收敛的办法有:
设置covariance_type置,对算法的收敛做限制:
"spherical":集群为不同半径的球形。
"diag"“:集群为轴平行于坐标轴的椭圆,大小不同。
"tied":集群必须具有相同的椭圆形状,只是出现位置不同。
默认情况下,covariance_type等于"full"。
实例数m、维度n、集群数k:
对于时间复杂度:当参数为full及tied时,其值为kmn2+kn3
当为前两者时,复杂度为kmn
所以高斯聚类不适用于太高维数据。
使用贝叶斯信息准则(BIC)或赤池信息准则(AIC)选择最优聚类数:
两者可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
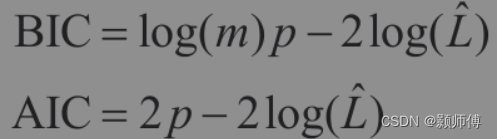
p为模型可学习参数量,m为实例数目,L为模型的似然函数最大值。
BIC及AIC的值越小,代表模型越好,可见实例及参数越多,似然函数值越低,代表拟合精度越差,同时算法所用实例及参数越多。
其中AIC不受实例的数目影响,BIC较AIC对精度的考虑低,对参数量的考虑多,能找出更精简的模型(实例m相当于对参数数量进行了加权)。
高斯聚类能源此法评估,是因为其计算最大期望函数时,得到了似然值。
直接调用相关函数接口去计算BIC及AIC的值:
gm.bic(X)
gm.aic(X)
或使用BayesianGaussianMixture类,并设置一个较大的集群数目,算法在运行后将自动对集群的数目进行精简。
import numpy as np
from sklearn.mixture import BayesianGaussianMixture
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [12, 4], [10, 7]])
#初始10类,最后输出将决定实际分类数。
bgm = BayesianGaussianMixture(n_components=10, random_state=42).fit(X)
#得出各类权重,部分不需要的集群权重归0,这里是超出两位小数后的位取整
np.round(bgm.weights_, 2)
输出结果中非0元素个数,即为最终确定的分类。
这篇关于【机器学习】使用scikitLearn对数据进行聚类:高斯聚类GaussianMixture的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




