本文主要是介绍ETL数据集成丨SQLServer到Doris的无缝数据同步策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在现代企业数据架构中,数据整合是至关重要的一个环节,它不仅关乎数据的准确性与一致性,还直接影响到数据分析的有效性和业务决策的精确性。Doris(原名 Palo)与 Hive 是两大在大数据处理领域内广泛应用的数据存储与分析系统,它们各有千秋,适用于不同的场景。将Doris数据整合至Hive数据库,旨在融合两者的优势,构建更为强大、灵活的数据分析平台,以支撑复杂多变的业务需求。
Doris与Hive的特点对比
Doris是一个高性能的MPP(大规模并行处理)数据库,专为OLAP(在线分析处理)设计,擅长处理复杂的分析查询,提供低延迟的即席查询能力。其分布式架构、列式存储以及先进的索引机制,使得在海量数据上进行亚秒级响应成为可能。Doris还支持实时数据导入,非常适合实时分析场景。
相比之下,Hive则起源于Hadoop生态系统,最初作为SQL接口被设计来处理批处理式的数据分析任务,适合处理PB级别的静态数据仓库应用。Hive通过HDFS存储数据,利用MapReduce或Tez等执行引擎进行计算,虽然在交互式查询性能上可能不如Doris,但其生态丰富、兼容SQL标准,且易于与Hadoop生态内的其他组件集成,如Spark、HBase等,提供了强大的数据处理和管理能力。
Doris与Hive同步方式
Doris与Hive作为大数据处理领域中两个重要的数据仓库系统,它们在数据分析、报表生成以及大规模数据处理场景中扮演着核心角色。尽管两者都旨在提供高效的数据存储与查询能力,但它们的设计理念、架构特点及应用场景各有侧重。因此,在实际应用中,实现Doris与Hive之间的数据同步不仅能够充分发挥两者的优势,还能促进数据资源的有效整合与利用。
Doris与Hive之间的数据同步策略应根据实际应用场景、数据量大小、实时性要求以及资源条件综合考虑。直接导出导入适用于小型项目或一次性迁移;而借助中间件、ETL工具或自定义脚本则能更好地应对大规模、实时性需求;利用系统间的桥接服务,则是在保持数据源独立性的同时,实现跨系统查询的有效途径。每种方法都有其优势与局限,关键在于合理选择与灵活应用,以达到数据同步的最佳效果。
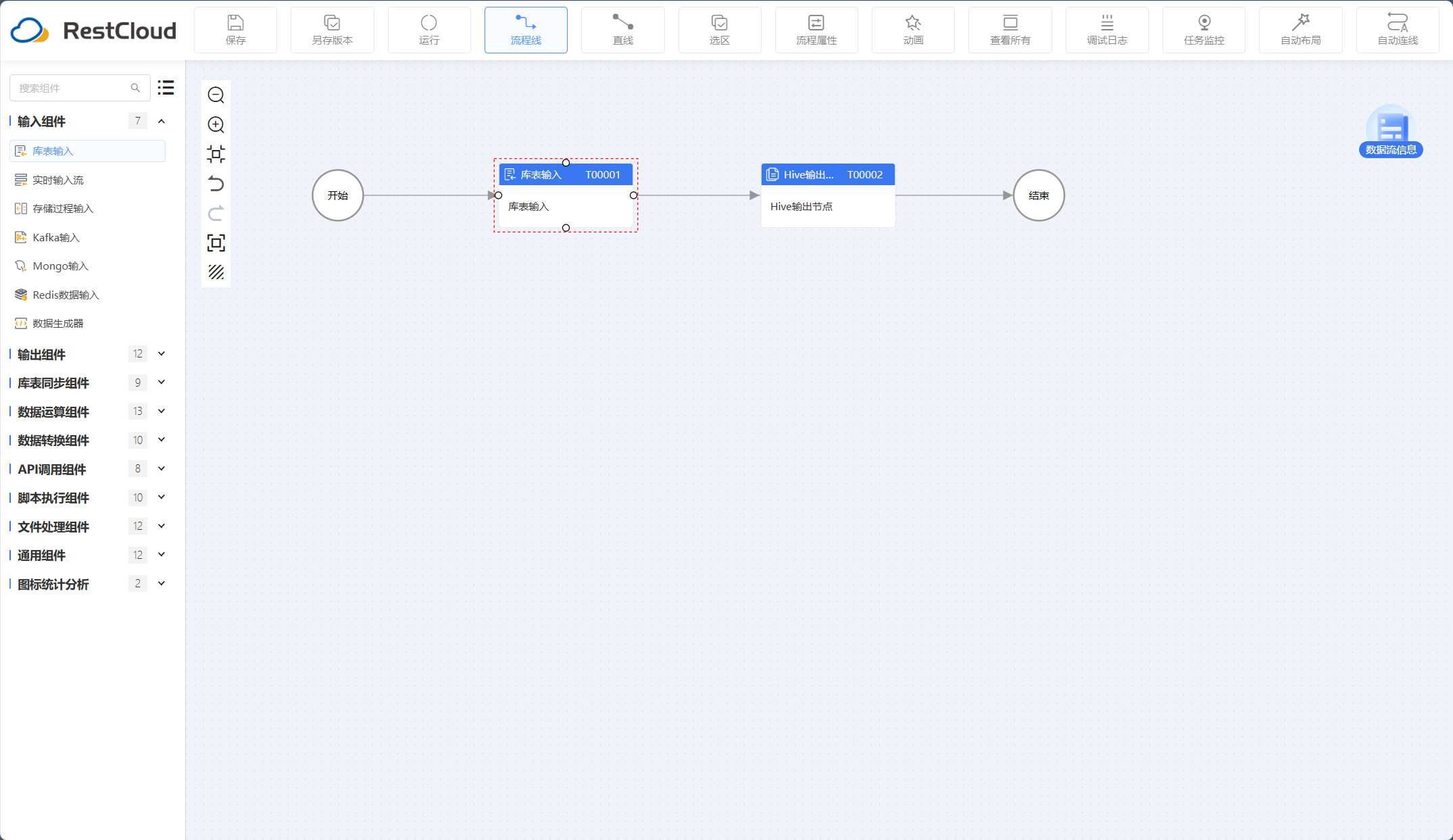
借助ETLCloud工具实现Doris数据同步至Hive数据库演示
通过对组件的拖拉拽以及配置,能快速构建数据整合通道。
流程设计
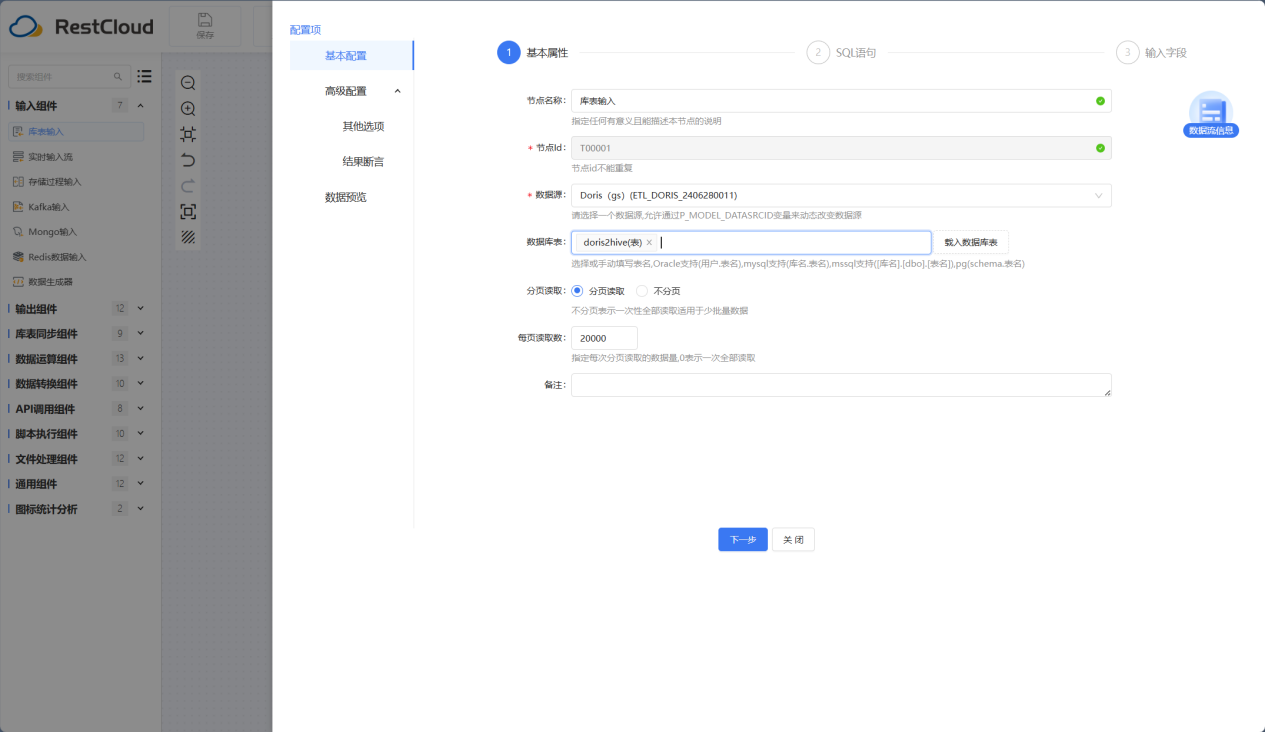
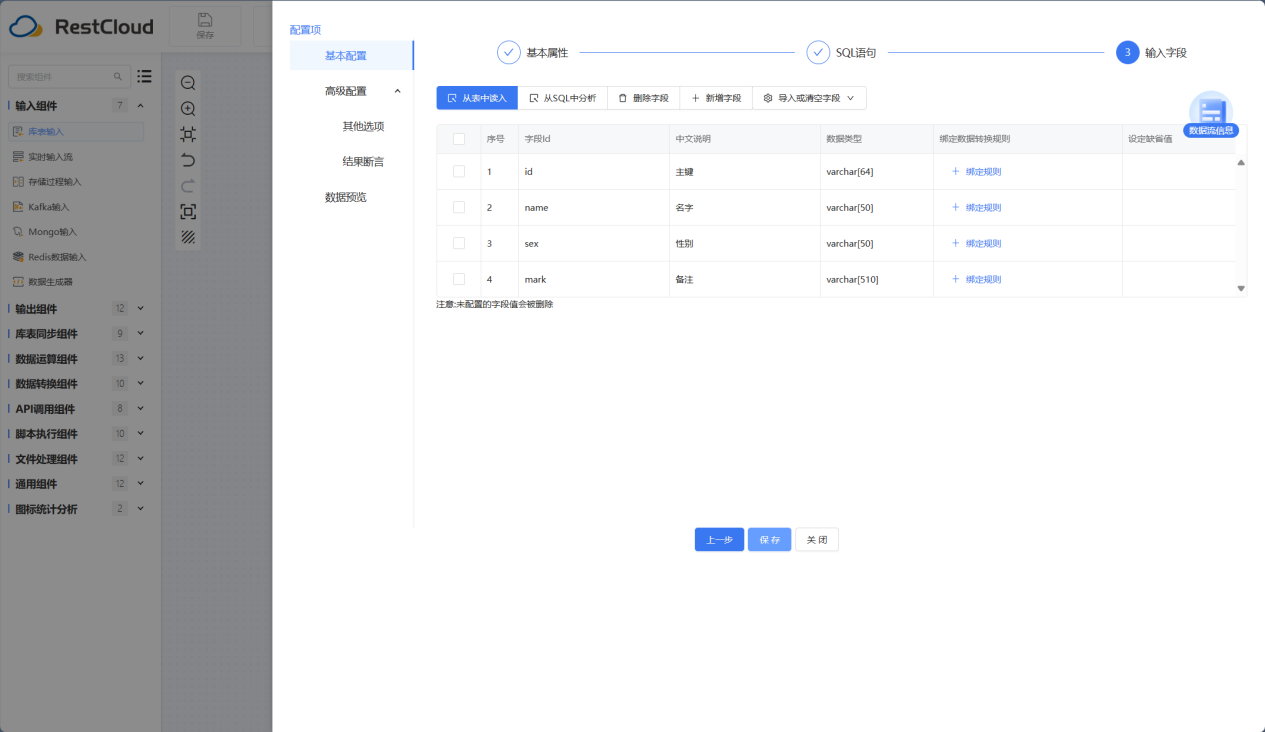
库表输入组件配置
选中Doris数据源并选中要读取数据所在的表
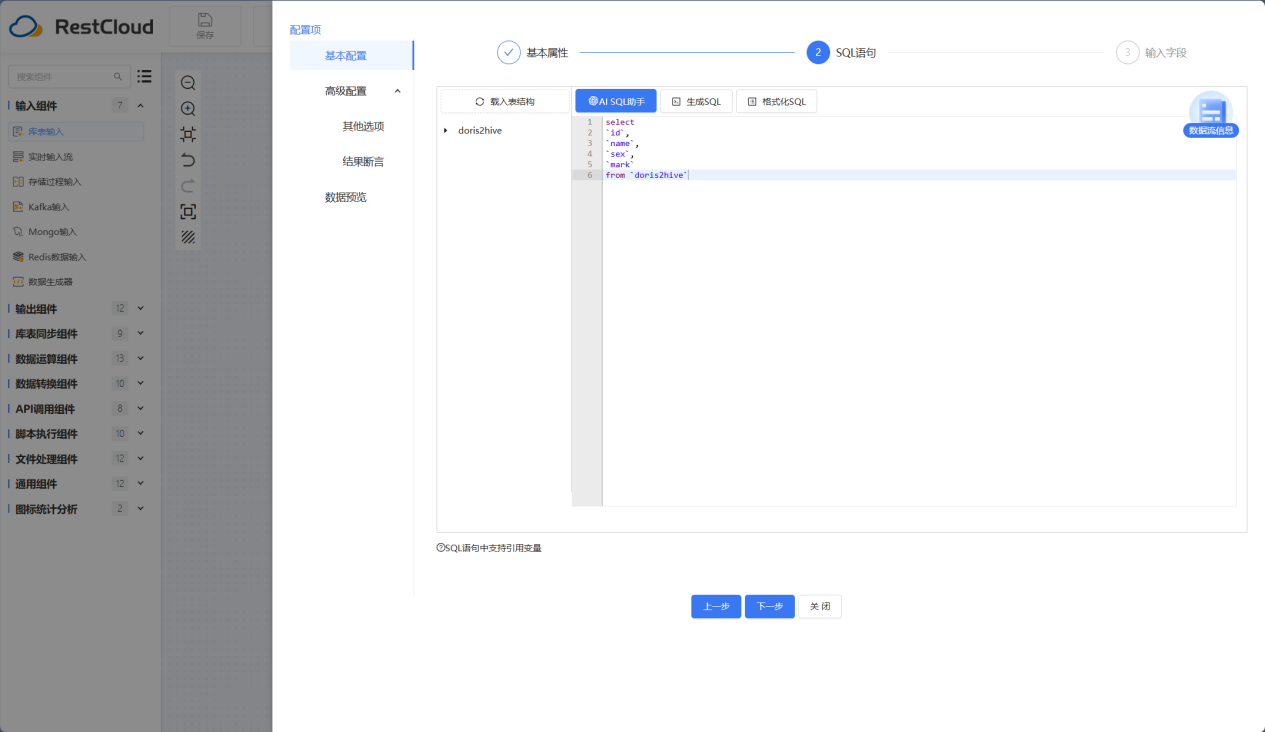
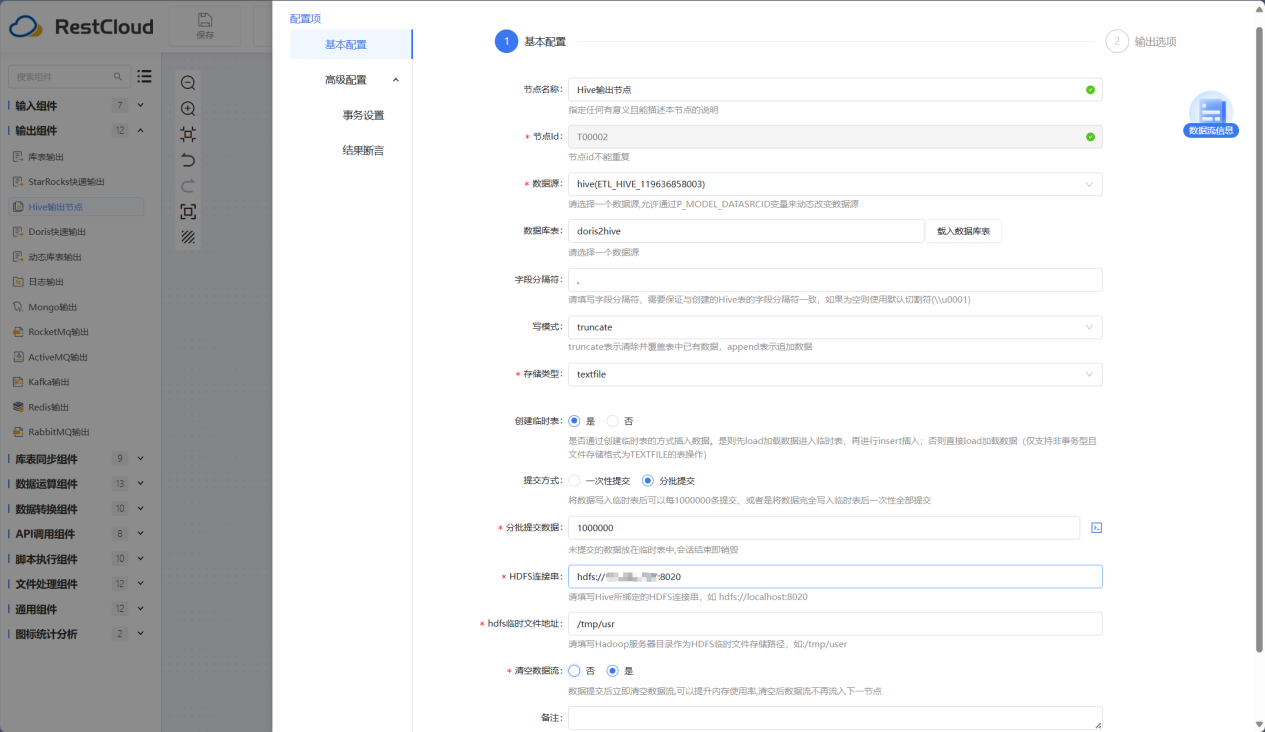
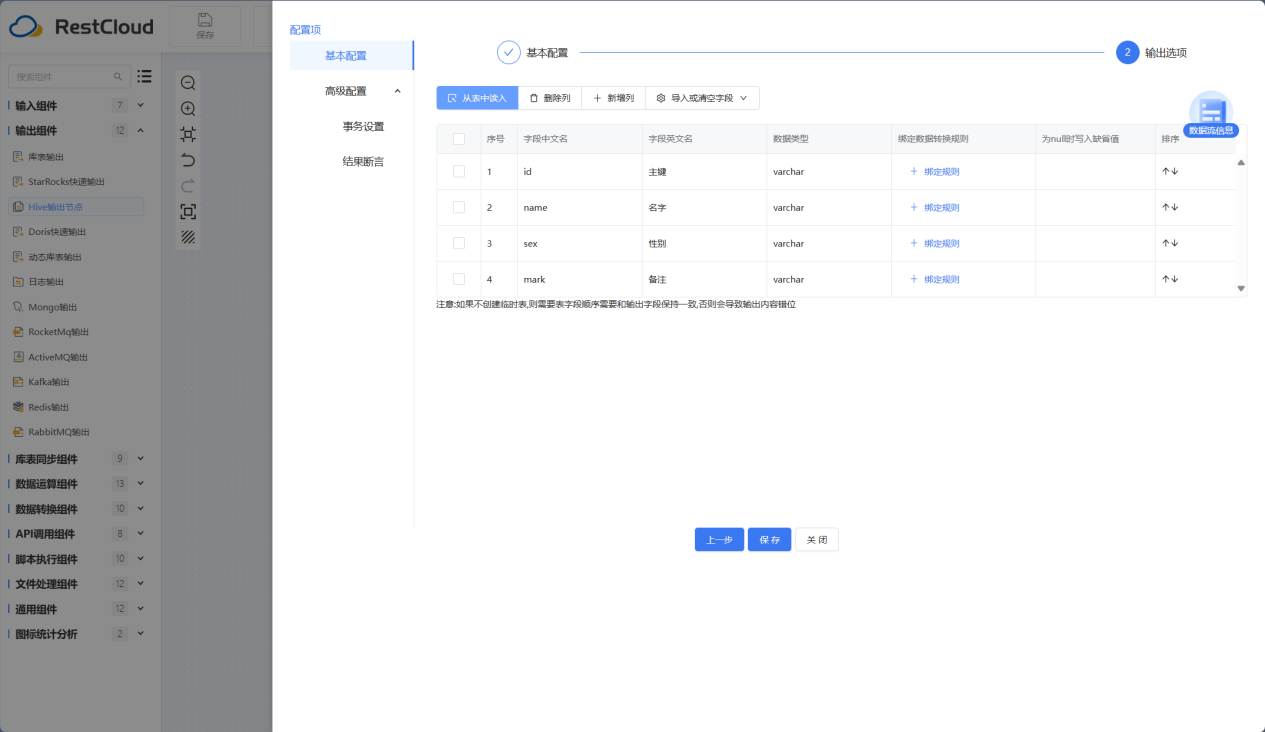
Hive输出节点组件配置
Hive输出节点是针对Hive数据库写入数据的组件,大大增加了数据传输到Hive的效率。
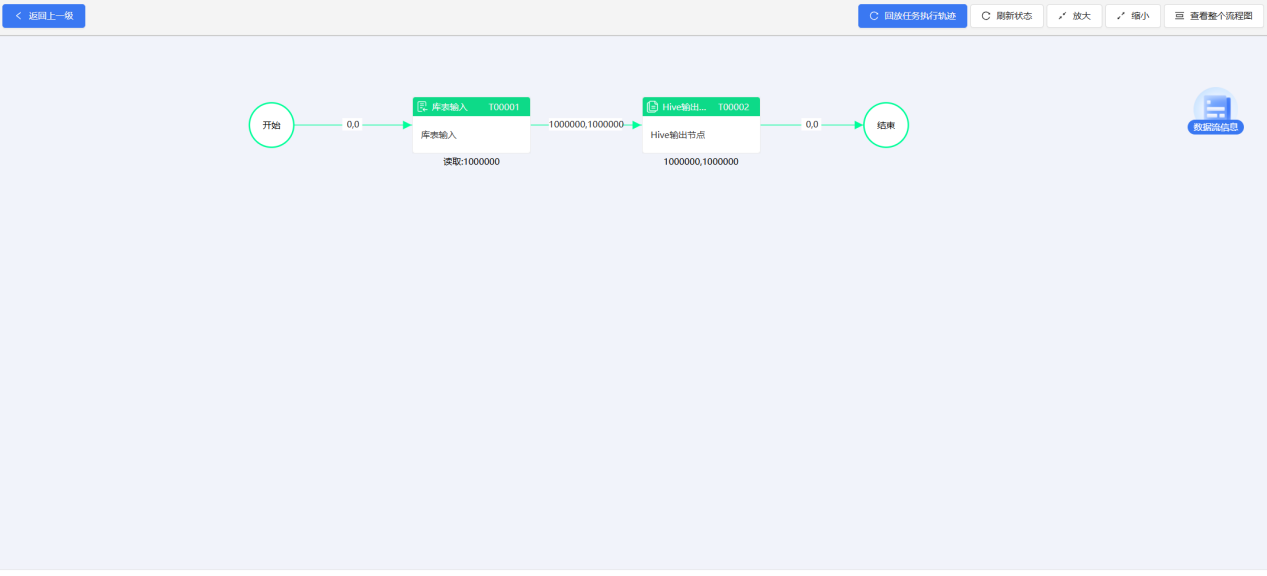
流程运行结果
轻松同步100W的数据量。
除了最基本的同结构表同步数据,ETLCloud还提供了非常丰富的数据转换、运算组件来应对同步的各种情况,比如当上述数据源的表字段不一致的话,可以在中间加入字段值映射组件来进行两张表的字段映射:
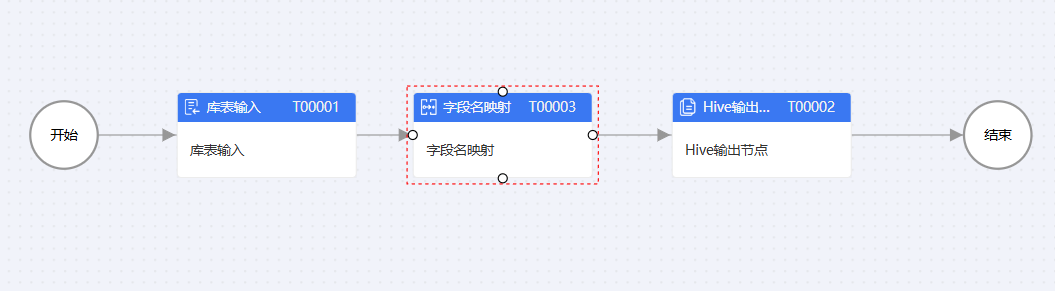
而如果想要目标表多一个字段并且赋予一个由其他两个字段进行数学运算得出的值,还可以使用字段值计算组件。

最后
在各种数据源之间进行数据迁移,选择合适的工具能够高效地解决问题。ETLCloud 作为一款高效的数据迁移工具,能快速把Doris的海量数据同步至Hive数据仓库,无论是数据分析,还是要对数据进行转换处理,平台都有针对性的功能、组件,帮助提升数据管理的效率和效果。
这篇关于ETL数据集成丨SQLServer到Doris的无缝数据同步策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







