本文主要是介绍kettle源码分析之5 日志系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- core
- 消息体
https://blog.csdn.net/weixin_39819880/article/details/88087652
core
用过kettle的人都有体会,spoon的使用机制是swing的gui开发,在整个过程的机理会使用大量的事件监听。日志系统也一样。
loglevel级别分为:
NOTHING( 0, “Nothing” ),
ERROR( 1, “Error” ),
MINIMAL( 2, “Minimal” ),
BASIC( 3, “Basic” ),
DETAILED( 4, “Detailed” ),
DEBUG( 5, “Debug” ),
ROWLEVEL( 6, “Rowlevel” );
核心类是KettleLogStore,进行日志存储。
/*** Create the central log store with optional limitation to the size** @param maxSize* the maximum size* @param maxLogTimeoutMinutes* The maximum time that a log line times out in Minutes.*/private KettleLogStore( int maxSize, int maxLogTimeoutMinutes, boolean redirectStdOut, boolean redirectStdErr ) {this.appender = new LoggingBuffer( maxSize );replaceLogCleaner( maxLogTimeoutMinutes ); // 根据超时事件定时清理超时日志if ( redirectStdOut ) {System.setOut( new LoggingPrintStream( OriginalSystemOut ) );}if ( redirectStdErr ) {System.setErr( new LoggingPrintStream( OriginalSystemErr ) );}}
public void replaceLogCleaner( final int maxLogTimeoutMinutes ) {if ( logCleanerTimer != null ) {logCleanerTimer.cancel();}logCleanerTimer = new Timer( true );TimerTask timerTask = new TimerTask() {@Overridepublic void run() {if ( maxLogTimeoutMinutes > 0 ) {long minTimeBoundary = new Date().getTime() - maxLogTimeoutMinutes * 60 * 1000;// Remove all the old lines.appender.removeBufferLinesBefore( minTimeBoundary );}}};// Clean out the rows every 10 seconds to get a nice steady purge operation...logCleanerTimer.schedule( timerTask, 10000, 10000 );}
同时,其中的discardLines方法会将某个id及其子元素的日志都remove掉。
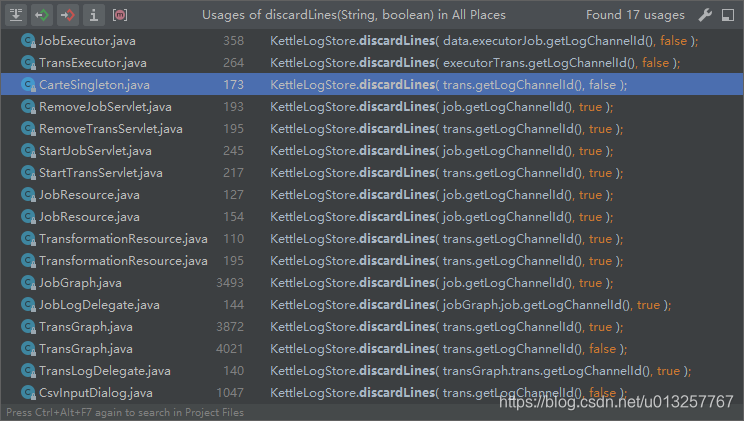
以任务执行为例,首先进入流程清理过期日志:
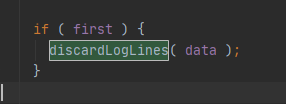
进行删除转换/任务或者disposeListner生效的时候,删除日志:
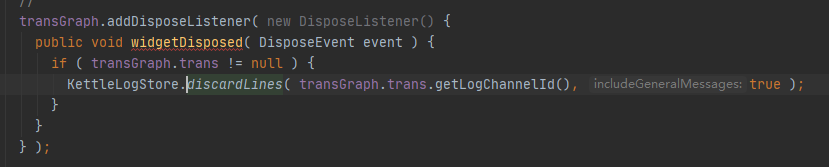
在这里采用事件机制处理是很巧妙的方式,提前添加监听,通过事件处理日志,实现了解耦。
实际的消息存储:LoggingRegistry
默认10000条日志,这个值可以通过设置环境变量处理,在启动bat/sh文件里进行处理。

消息体
日志消息是通过LogMessage进行的,日志通道可以参考LogChannel:
public void println( LogMessageInterface logMessage, LogLevel channelLogLevel ) {String subject = null;LogLevel logLevel = logMessage.getLevel();if ( !logLevel.isVisible( channelLogLevel ) ) {return; // not for our eyes.}if ( subject == null ) {subject = "Kettle";}// Are the message filtered?//if ( !logLevel.isError() && !Utils.isEmpty( filter ) ) {if ( subject.indexOf( filter ) < 0 && logMessage.toString().indexOf( filter ) < 0 ) {return; // "filter" not found in row: don't show!}}// Let's not keep everything...if ( channelLogLevel.getLevel() >= logLevel.getLevel() ) {KettleLoggingEvent loggingEvent = new KettleLoggingEvent( logMessage, System.currentTimeMillis(), logLevel );KettleLogStore.getAppender().addLogggingEvent( loggingEvent );// add to bufferLogChannelFileWriterBuffer fileWriter = LoggingRegistry.getInstance().getLogChannelFileWriterBuffer( logChannelId );if ( fileWriter != null ) {fileWriter.addEvent( loggingEvent );}}}
LogChannel没添加一个日志事件,就循环遍历监听器,添加事件
public void addLogggingEvent( KettleLoggingEvent loggingEvent ) {doAppend( loggingEvent );eventListeners.forEach( event -> event.eventAdded( loggingEvent ) );}
对于kettle日志对象有3类:KettleLoggingEvent,
FileLoggingEventListener
ConsoleLoggingEventListener
Slf4jLoggingEventListener
都继承于KettleLoggingEventListener。
LoggingRegistry是一个单例对象,
这篇关于kettle源码分析之5 日志系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






