本文主要是介绍[深度学习]交叉熵(Cross Entropy)算法实现及应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面:要学习深度学习,就不可避免要学习Tensorflow框架。初了解Tensorflow的基础知识,看到众多API,觉得无从下手。但是到了阅读完整项目代码的阶段,通过一个完整的项目逻辑,就会让我们看到的不只是API,而是API背后,与理论研究相对应的道理。除了Tensorflow中文社区的教程,最近一周主要在阅读DCGAN的代码(Github:https://github.com/carpedm20/DCGAN-tensorflow)。在阅读代码的过程中,遇到了很多问题,也学习了不少知识。接下来的篇幅,围绕DCGAN代码中出现的知识点,记录我的学习过程。
一.交叉熵(Cross Entropy)
交叉熵(Cross Entropy)是Shannon信息论中的一个重要概念,主要用于度量两个概率分布间的差异性信息。
公式如下:

其中,p表示真实标记的分布,q则为训练后的模型的预测标记分布。利用交叉熵,可以衡量p与q的相似性。交叉熵在神经网络中可以作为损失函数。
二.应用场景
在Tensorflow中,针对分类问题,定义了四个交叉熵函数,分别是:
1)tf.nn.sigmoid_cross_entropy_with_logits
2)tf.nn.softmax_cross_entropy_with_logits
3)tf.nn.sparse_softmax_cross_entropy_with_logits
4)tf.nn.weighted_cross_entropy_with_logits
1)tf.nn.sigmoid_cross_entropy_with_logits
[适用场景]:二分类或者多目标问题
二分类:将目标分为两类
多目标:例如,判断图片中是否包含10种动物。这10个分类之间是相互独立的,但不是相互排斥的。也就是说,图片中可以包含动物x,也可以包含动物y。对于每一个动物类别而言,其实也是一个二分类问题。与多目标问题不同的是,多分类问题要求这10个分类之间是相互排斥的。
[实际应用]:在DCGAN网络中,计算Discriminator和 Generator的 loss的时候,使用的是tf.nn.sigmoid_cross_entropy_with_logits。因为是判断输入Discriminator的数据是真实数据还是由Generator生成的数据,也就是判断数据是1还是0,相当于一个二分类问题。
[API]:tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, names=None)
定义:
`x = logits`, `z = targets`.
逻辑损失为:
z * -log(sigmoid(x)) + (1 - z) * -log(1 - sigmoid(x))
= z * -log(1 / (1 + exp(-x))) + (1 - z) * -log(exp(-x) / (1 + exp(-x)))
= z * log(1 + exp(-x)) + (1 - z) * (-log(exp(-x)) + log(1 + exp(-x)))
= z * log(1 + exp(-x)) + (1 - z) * (x + log(1 + exp(-x))
= (1 - z) * x + log(1 + exp(-x))
= x - x * z + log(1 + exp(-x))
当x<0的时候,为了避免exp(-x)溢出,将上述等式改为:
x - x * z + log(1 + exp(-x))
= log(exp(x)) - x * z + log(1 + exp(-x))
= - x * z + log(1 + exp(x))
因此,将x>0与x<0时的情况统一起来可以得到:
max(x, 0) - x * z + log(1 + exp(-abs(x)))
Args:
logits: 未经sigmoid缩放的输入logits,即类型为float32或者float64,shape为[batch_size,num_classes]的tensor。
targets: 目标targets,即与logits具有相同类型和shape的tensor。
name: 操作的名称(可选)。
Returns:
计算得到的sigmoid交叉熵,即与logits具有相同shape的tensor。
Raises:
ValueError:如果logits和targets的shape不同,则会抛出异常。
代码举例:
# coding:utf-8
import tensorflow as tfdef sigmoid_cross_entropy_with_logits(x, y):try:return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)except:return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, targets=y)def main(_):logits = [[0.5,0.7,0.3],[0.8,0.2,0.9]]loss = sigmoid_cross_entropy_with_logits(logits, tf.ones_like(logits))sess = tf.Session()print sess.run(loss)if __name__ == '__main__':tf.app.run()运行结果为:
注意事项:

(1)输入logits是未经缩放的,该操作内部会对logits使用sigmoid操作。
(2)logits和labels(targets)必须具有相同的shape。
2)tf.nn.softmax_cross_entropy_with_logits
[适用场景]:多分类问题
也就是将输入分为多类,每一类都是相互排斥的。
[实际应用]:例如,在tensorflow的cifar10示例中,判断图片的动物具体是哪一种,只能是某一种类型。
[API]:softmax_cross_entropy_with_logits(logits, labels, dim=-1, name=None)
Args:
logits: 未经softmax缩放的输入logits,即类型为float16,float32或者float64,shape为[batch_size,num_classes]的tensor。
labels: 目标targets,即与logits具有相同类型和shape的tensor。
dim: 分类的类别所在的维度。默认为-1,也就是最后一维。
name: 操作的名称(可选)。
Returns:
计算得到的softmax交叉熵,也就是一维tensor,与输入的logits中的batch_size大小相同。
代码举例:
# coding:utf-8
import tensorflow as tfdef main(_):logits = [[2,0.5,1],[0.1,1,3]]labels = [[0.2,0.3,0.5],[0.1,0.6,0.3]]logits_scaled = tf.nn.softmax(logits)result1 = tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=labels)result2 = -tf.reduce_sum(labels*tf.log(logits_scaled),1)result3 = tf.nn.softmax_cross_entropy_with_logits(logits=logits_scaled,labels=labels)with tf.Session() as sess:print '直接使用API计算softmax交叉熵:'print sess.run(result1)print '\n'print '利用原理计算softmax交叉熵:'print sess.run(result2)print '\n'print '错误!将logits输入事先用softmax缩放:'print sess.run(result3)if __name__ == '__main__':tf.app.run()运行结果:

3)tf.nn.sparse_softmax_cross_entropy_with_logits
[应用场景]:多分类问题
tf.nn.sparse_softmax_cross_entropy_with_logits是 tf.nn.softmax_cross_entropy_with_logits的易用版本,除了输入参数不同,作用和算法实现都是一样的。前面提到softmax_cross_entropy_with_logits的输入必须是类似onehot encoding的多维特征,但是CIFAR-10,ImageNet和大部分分类场景都只有一个分类目标,label都是从0编码的整数,每次转成one hot encoding比较麻烦。那么,就可以使用tf.nn.sparse_softmax_cross_entropy_with_logits,直接使用类别索引作为labels,而不用转为one hot encoding。
例如:类别2,在softmax_cross_entropy_with_logits中labels可以表示为[0,0,1];在sparse_softmax_cross_entropy_with_logits中labels可以表示为2。
[API]:sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)
Args:
logits:未经softmax缩放的输入logits,即类型为float32或者float64,shape为[d_0, d_1, ..., d_{r-2}, num_classes]的tensor。
labels: 标签,即类型为int32或者int64,shape为[d_0, d_1, ..., d_{r-2}]的tensor 。[d_0, d_1, ..., d_{r-2}]代表batch_size。labels中的每一项都必须是范围为[0, num_classes)的索引,也就是代表label是属于哪一类的。
name: 操作的名称(可选)。
Returns:
表示softmax交叉熵的tensor。与labels具有相同的shape,也就是batch_size。与输入logits具有相同的类型。
代码举例:
# coding:utf-8
import tensorflow as tfdef main(_):logits = [[2,0.5,1],[0.1,1,3]]labels = [[0,1,0],[0,0,1]]labels2 = [1,2]result= tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=labels)result2= tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,labels=labels2)with tf.Session() as sess:print 'softmax_cross_entropy_with_logits,输入logits:[[0,1,0],[0,0,1]]'print sess.run(result)print'\n'print 'sparse_softmax_cross_entropy_with_logits,输入logits:[1,2]'print sess.run(result2)if __name__ == '__main__':tf.app.run()运行结果:

4)tf.nn.weighted_cross_entropy_with_logits
[应用场景]:tf.nn.weighted_cross_entropy_with_logits是tf.nn.sigmoid_cross_entropy_with_logits的扩展版,输入参数和实现与后者类似,不同之处在于增加了一个pos_weight参数,目的是可以增加或者减小正样本在计算Cross Entropy时的loss。
[API]:weighted_cross_entropy_with_logits(logits, targets, pos_weight, name=None):
在前面介绍tf.nn.sigmoid_cross_entropy_with_logits时,已经提到过,一般计算交叉熵的方法为:
targets * -log(sigmoid(logits)) + (1 - targets) * -log(1 - sigmoid(logits))
pos_weight用于正样本的loss计算项上:
targets * -log(sigmoid(logits)) * pos_weight +(1 - targets) * -log(1 - sigmoid(logits))
展开来就是:
qz * -log(sigmoid(x)) + (1 - z) * -log(1 - sigmoid(x))
= qz * -log(1 / (1 + exp(-x))) + (1 - z) * -log(exp(-x) / (1 + exp(-x)))
= qz * log(1 + exp(-x)) + (1 - z) * (-log(exp(-x)) + log(1 + exp(-x)))
= qz * log(1 + exp(-x)) + (1 - z) * (x + log(1 + exp(-x))
= (1 - z) * x + (qz + 1 - z) * log(1 + exp(-x))
= (1 - z) * x + (1 + (q - 1) * z) * log(1 + exp(-x))
令l = (1 + (q - 1) * z),为了避免溢出,最终实现为:
(1 - z) * x + l * (log(1 + exp(-abs(x))) + max(-x, 0))
`logits` 和 `targets`必须具有相同的类型和shape。
Args:
logits: 输入logits,即类型为float32或者float64,shape为[batch_size,num_classes]的tensor。
targets: 与logits具有相同类型和shape的tensor。
pos_weight: 系数,用于正样本上。
name: 操作名称(可选)。
Returns:
与logits具有相同shape的损失tensor。
Raises:
ValueError:如果logits和targets的shape不同,则会抛出异常。
代码举例:
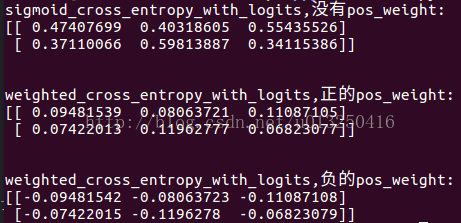
# coding:utf-8
import tensorflow as tfdef main(_):logits = [[0.5,0.7,0.3],[0.8,0.2,0.9]]loss = tf.nn.sigmoid_cross_entropy_with_logits(logits, tf.ones_like(logits))loss2 = tf.nn.weighted_cross_entropy_with_logits(logits, tf.ones_like(logits), 0.2)loss3 = tf.nn.weighted_cross_entropy_with_logits(logits, tf.ones_like(logits), -0.2)with tf.Session() as sess:print 'sigmoid_cross_entropy_with_logits,没有pos_weight:'print sess.run(loss)print'\n'print 'weighted_cross_entropy_with_logits,正的pos_weight:'print sess.run(loss2)print'\n'print 'weighted_cross_entropy_with_logits,负的pos_weight:'print sess.run(loss3)if __name__ == '__main__':tf.app.run()运行结果:
三.总结
我们可以根据业务需求(分类目标是否独立或者互斥)来选择基于sigmoid或者softmax的实现。在这两大类里面,再根据实际需求来选择使用tf.nn.sigmoid_cross_entropy_with_logits或者tf.nn.weighted_sigmoid_cross_entropy_with_logits,tf.nn.softmax_cross_entropy_with_logits或者tf.nn.sparse_softmax_cross_entropy_with_logits。
浅显解读,更深层次,移步Tensorflow官方文档。
参考博客:http://dataunion.org/26447.html
这篇关于[深度学习]交叉熵(Cross Entropy)算法实现及应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




